Introduction
Before preparing frequency distribution it is necessary to collect data of the required nature from the various sources. The data collected is always in raw form which is needed to be arranged in a proper arrangement for the purpose of inferring the required results. You need to do certain preparations for frequency distribution, which includes the classification and tabulation of data. Both of them are explained in detail as follows;
Classification
“The process of arranging data into classes or categories according to some common characteristics present in the data is called classification”
Collected data are usually available in a form which is not easy to comprehend. For example, if we have before us the marks obtained by 1000 universities students at their Undergraduate Examination, it would be difficult to tell simply by looking at the marks as to how many students have marks between 300 and 400, between 400 and 500, and so on. In order to get the clear picture of the situation, the data must be present in a manner which is easy to understand. As first step, we arrange the data into classes and categories having similar characteristics. For example, we may arrange the marks into groups of 50 marks each, e.g. 300 t0 349, 350 to 399, 400 to 449 and so on.
Basis for Classification
The collected data can be classified by many characteristics, there are four main basis of classification are mostly being practiced. These bases are;
1. Qualitative
- When data are classified by attributes, e.g. religion, marital status etc.2.
2. Quantitative:
- When data are classified by quantitative characteristics, e.g. height, weight, income, etc.
3. Geographical:
- When data are classified by geographical regions or locations, e.g. the population of a country may be classified by provinces, divisions, districts or towns.
4. Chronological/Temporal:
When data are classified by their time of occurrence. An arrangement of data by their time of occurrence is called a time series.
Tabulation
“The process of arranging data into rows and columns is called tabulation”
A table is a systematic arrangement of data into vertical column and horizontal rows. Tabulation of data on population of a country can by classified on the basis of religion, gender or marital status. Tabulation may be simple, double, triple or complex depending on the nature of classification, which is being used by the statistician.
Frequency Distribution
“A frequency distribution is a tabular arrangement of data in which various items are arranged into classes and the number of items falling in each class is being mentioned”
We have discussed the classification and tabulation of data. Frequency distribution is an important method of summarizing and organizing quantitative data. The data which is presented in the form of frequency distribution is called grouped data, whereas, the data which has not been arranged in a systematic order or in the form of frequency distribution is called raw data or ungrouped data.
For Example
Let us consider the weight of 120 students at a university, as given below;
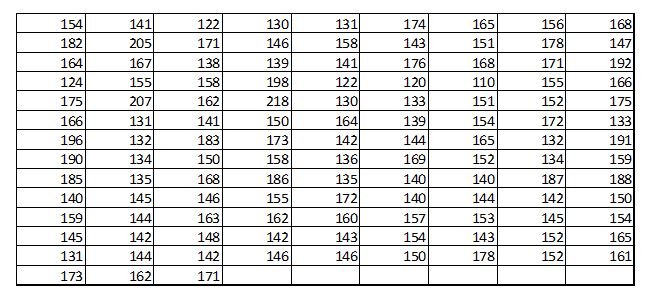
From the above provided data it is difficult to draw any meaningful conclusions. As in, it is difficult to tell simply by looking at the above data as to how many students have weights below or above 150 pounds or between 150 and 200 pounds and so on. Therefore, necessary to arrange the data in such a way as their main features as clear. Conclusion can easily be drawn if the data is arranged in an array. An arrangement of data in ascending or descending order is called an array.
From the array many question regarding the data could be answered. But still it will be difficult to look at 120 observations and obtain an accurate idea as to how these observations are distributed. Therefore, we can arrange them in better form. For example, the data may be arranged into classes as shown in following Table 1.
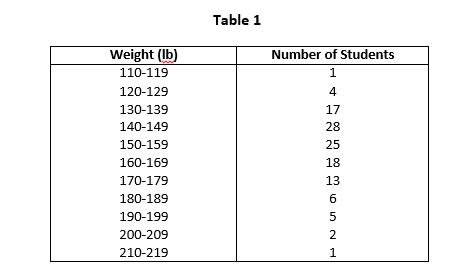
By arranging the raw data in the above form we have distributed the data into classes and determined the number of items belonging to each class i.e. class frequency. The range of data from 110 to 119 is a single class and 1 is it’s corresponding frequency. Such an arrangement of data by classes together with their corresponding class frequencies is called frequency distribution or frequency table.
Class Limits
In Table 1 we see that each class is described by two numbers. These numbers are called class limits. The smaller number is called the lower class limit, and the larger number is called upper class limit. For example, in Table 1, the class limits for first class are 110 and 119. 110 is the lower class limit and 119 is the upper class limit.
Class Boundaries
Class limits are not always exactly what they look like. We know that measurements are seldom exact, most of the time they involve approximates and estimations. A weight of 110 pounds means a weight lying between 109.5 and 110.5 pounds. And a weight 119 pounds means a weight lying between 118.5 and 119.5 pounds. When the lower class limit is given as 110 pounds, the true lower class limit is, therefore, the 109.5 pounds and when the upper class limit is given as 119 pounds, the true upper class limit is actually 109.5 pounds. Therefore, if the weights are recorded to the nearest pounds, the class 110-119 includes all the measurements from 109.5 to 119.5 pounds.
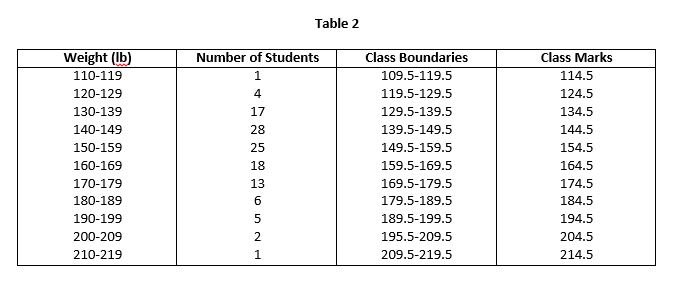
The values 109.5 and 119.5 which describe the true class limits of a class are the called the true class limits or class boundaries. The smaller number 109.5 is lower class boundary and the larger number 119.5 is called upper class boundary. Class boundaries are clearly shown in Table 2.
The class boundary can be obtained by adding the upper class limit of one class to the lower class limit of the next higher class and then dividing by 2. Mathematically it can be represented as follows;
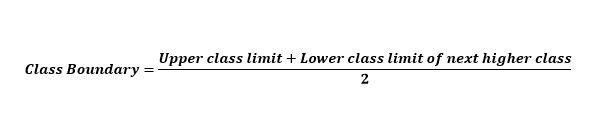
For Example, Class boundaries for first class in Table 1 is calculated as;
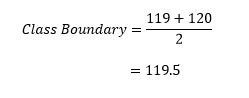
The Class Marks or Midpoints
“The class mark or the midpoint is that value which divides a class into two equal parts”
The class mark or midpoint can be obtained by adding the lower class limit and the upper class limit or class boundary of a class and dividing the resulting figure by 2. Mathematically it can represent as follows;
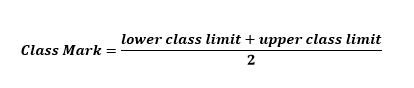
For Example, Class mark of the first class in Table 2 below, will be calculated as;
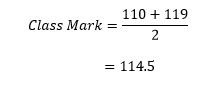
The following Table 2 shows the class boundaries and class marks for the corresponding classes,
Size of Class Interval
“The size of the class interval, which is also called the class width or class length, is the difference between the upper class boundary and the lower class boundary”.
Class interval is not the difference between the class limits. Where all the class intervals of a frequency distribution are of equal size, the common width id denoted by h. In such case, the size of the class interval is also equal to the difference between the two successive lower or upper class limits. For example, in Table 2 the class interval for first class is 119.5 – 109.5 = 10, or 120 – 110 = 10.
Formation of a Frequency Distribution
Following steps are involved in the formation of a frequency distribution:
-
Determine the greatest and the smallest number:
First of all determine the greatest and the smallest number in the raw data and find the range, which is the difference between the greatest and the smallest numbers. In the example of weights of 120 students, the greatest number is 218 and the smallest number is 110. Therefore, the range is 218 – 110 =108.
-
Decide on the number of class:
For the purpose of determining the classes for the frequency distribution there is no hard and fast rules for the purpose. Mostly, 5 to 20 classes are being made. The number of classes should be appropriate, so that could be distributed and represented properly. If we have less than 5 classes, it will result in too much information being lost. On the other hand, if we have more than 20 classes, computation will become unnecessarily lengthy. In Table 1 we have made 11 classes.
- Determine the approximate class interval size:
The approximate class interval size is determined by dividing the range of the desirable number of classes. For example, in the raw data of weights of 120 students, the class interval size is 108/11 = 9.8 or 10. A number used as class interval size should be easy to work with.
-
Decide what should be the lower class limit:
The lower class limit should cover the smallest value in the raw data.
- Find the upper class boundary by adding the class interval size to the lower class boundary:
The upper class boundary of a particular class is determined by adding the class interval size to the lower class boundary of such class. The remaining lower and upper class boundaries are determined by adding the class interval repeatedly until the largest measurement of the raw data is enclosed in the final class.
- Distribute the values of the raw data into classes:
The class frequencies are obtained by distributing the raw data measurements into the classes made. The number of measurements falling in each class is referred as it frequency.
Methods for Frequency Distribution
There are two methods for arranging the observations in their proper classes. Such methods are as follows;
-
By Listing the Actual Values:
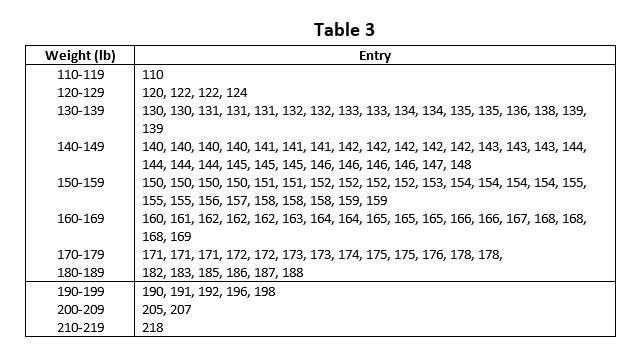
In this method of frequency distribution, each observation is listed in its proper class. The following Table 3 illustrates the tabulation of weight measurements of 120 students. This is called entry table.
-
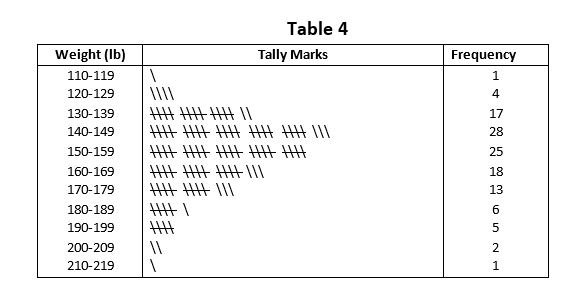
By Using Tally Marks:
This method of frequency distribution is used where the data are not arranged in order of magnitude. The easiest way of tabulation data is by recording stroke i.e. tally mark, opposite the appropriate class for each observation. The following Table 4 illustrates the frequency distribution by using tally mark.


In recent years, the rise for UK non-GamStop casino, http://eseguro.mx/discover-the-best-non-gamstop-online-casinos-5/ sites has grown significantly. Players are desiring options that allow individuals to enjoy gaming without restrictions. These platforms offer exciting experiences, superior bonuses, and wide variety of games, making them attractive for many.
заказать кухню в рассрочку zakazat-kuhnyu-12.ru .
производство кухонь в спб на заказ kuhni-spb-50.ru .
купить кухню на заказ в спб kuhni-spb-49.ru .
кухни в спб от производителя кухни в спб от производителя .
non GamStop online casino, https://stage1.nextchannelmedia.com/exploring-casinos-that-don-t-use-gamstop-a-guide/ offers players the chance to enjoy thrilling games without hurdles. Many players prefer these casinos for their broad selection of options and beneficial bonuses.
сколько стоит заказать кухню по размерам сколько стоит заказать кухню по размерам .
кухни от производителя спб kuhni-spb-51.ru .
кухня на заказ кухня на заказ .
заказ кухни заказ кухни .
Os mais populares casinos online portugal, https://dev.asixonline.com/oma/melhores-casinos-online-em-portugal-2026-descubra/ oferecem uma aventura excepcional para os participantes. Com uma extensa seleção de diversões, os jogadores podem passar o tempo. Além disso, ofertas cativantes garantem a vivência ainda mais.
продвижение веб сайтов москва internet-agentstvo-prodvizhenie-sajtov-seo.ru .
анализ баннеров reklamnyj-kreativ14.ru .
In a realm of gaming, the non GamStop online casino, http://www.pisarevo.com/best-non-gamstop-casino-top-choices-for-players/ provides players with diverse opportunities to enjoy their favorite games. With versatile options, these casinos present an extraordinary experience. Enjoy captivating gameplay and generous bonuses that cater to every liking in this dynamic online gaming landscape.
кухни на заказ в спб кухни на заказ в спб .
кухни на заказ в санкт-петербурге kuhni-spb-51.ru .
частного нарколога на дом narkolog-na-dom-v-krasnodare-2.ru .
But what you might struggle with throughout the game is the All Ways Pays mechanics. That’s because for a payout, you’ll need to land 9 or more symbols, adjacent to each other vertically or horizontally, to form a winning cluster – that’s quite a lot compared to other cluster pays online slots. Aloha! Cluster Pays has a pretty interesting free spins bonus feature. Land 3, 4, 5 or 6 free spins symbols during a spin and you will be rewarded with 9, 10, 11 or 12 free spins respectively. During the free spins many of the fruit symbols will drop off the reels, leaving only the higher paying symbols, such as the stacked totems. This can lead to some really big pays, as long as the other symbols drop out before the free spins have concluded. This is another fine slot game from NetEnt. It has a unique layout, works slightly differently from the average game, and with the Aloha Clusters Pays Bonuses, a great opportunity to land some big prizes.
https://laxmikant.net/16/2026/over-under-betting-wolf-winner-tips-for-australian-bettors/
Malta: 23rd June 2023 – Stakelogic Live has quickly become a must-have supplier for online casino brands in markets across Europe and beyond, and its full suite of games is now available to those powered by leading platform and content provider, Aspire Global. Mathematically correct strategies and information for casino games like blackjack, craps, roulette and hundreds of others that can be played. Home » Play 25,000+ Free Casino Games » Roulette Online Free » Free American Roulette The two companies are ready to take the live dealer content offering to the next level, as they said in a press release. Both BetVictor, as an operator, and Stakelogic Live as a supplier of innovative products, are excited at the opportunity. The integration, carried out via Relax Gaming, will enable Slots Temple to expand its offering with some of Stakelogic’s most innovative and high-performing games, designed to capture the attention of its growing UK player base.
продвижение веб сайтов москва internet-agentstvo-prodvizhenie-sajtov-seo.ru .
купить заказать кухню купить заказать кухню .
Os jogos de azar online transformaram-se bastante populares em Portugal. Os apostadores podem aproveitar uma vasta seleção de experiências, incluindo jogos de roleta. Além disso, os ofertas atraem novos usuários. casinos online portugal, https://stg.nyuct.com/os-melhores-cassinos-online-em-portugal-2026/ oferece uma experiência confiável, permitindo que todos joguem em conforto em casa.
позиция карточки в выдаче позиция карточки в выдаче .
заказать кухню заказать кухню .
нарколог на дом в краснодаре нарколог на дом в краснодаре .
ШЄШ№ШЄШЁШ± Ш§Щ„Щ…Щ†ШµШ§ШЄ Ш§Щ„Ш§ЩЃШЄШ±Ш§Ш¶ЩЉШ© ШЄШ¬Ш±ШЁШ© Ш±Ш§Ш¦Ш№Ш© Щ„Щ„ЩѓШ«ЩЉШ± Щ…Щ† Ш§Щ„Щ„Ш§Ш№ШЁЩЉЩ†. Ш§ЩЃШ¶Щ„ ЩѓШ§ШІЩЉЩ†Щ€ Ш§Щ€Щ† Щ„Ш§ЩЉЩ† Ш§Щ„ЩѓЩ€ЩЉШЄ, https://americancom.com.bo/2026/03/13/875049222/ ЩЉЩ‚ШЇЩ… ЩЃШ±ШµЩ‹Ш§ Щ…ШЄЩ†Щ€Ш№Ш©. ЩЉЩ…ЩѓЩ†Щѓ Ш§Щ„Ш§ШіШЄЩ…ШЄШ§Ш№ ШЁШЈЩ„Ш№Ш§ШЁ Щ…ШґЩ€Щ‚Ш© Щ…Щ† ШЈЩЉ Щ…ЩѓШ§Щ†.
вызвать нарколога на дом вызвать нарколога на дом .
заказать кухню по индивидуальному заказу zakazat-kuhnyu-9.ru .
заказать кухню с установкой zakazat-kuhnyu-12.ru .
продвижение сайтов во франции internet-agentstvo-prodvizhenie-sajtov-seo.ru .
заказ кухни заказ кухни .
casas de apostas portugal, https://soccerlive.tech/descubra-as-melhores-casas-de-apostas-em-portugal-7/ – As casas de apostas online Portugal tГЄm crescido nos Гєltimos anos. Os entusiastas buscam opções variadas para apostar, como jogos de casino. AlГ©m disso, a regulamentação garante proteção aos usuГЎrios, contribuindo para o sucesso dessa ГЎrea.
нарколог на дом нарколог на дом .
изготовление кухни на заказ в спб kuhni-spb-50.ru .
прогноз доли выбора карточка прогноз доли выбора карточка .
наркологическая клиника trezviy vibor narkologicheskaya-klinika-trezvyj-vybor.ru .
заказать кухню онлайн заказать кухню онлайн .
заказать кухню под ключ zakazat-kuhnyu-9.ru .
offshore casino online, https://darkviolet-loris-841888.hostingersite.com/top-10-offshore-casinos-your-guide-to-online/ offers a thrilling betting experience. With numerous games, it allows players to indulge in popular activities. Create an account today and uncover the captivating landscape of offshore casino online!
промокод при регистрации 1хБет Использование промокода при регистрации на https://fontanvazon.ru/jscripts/pgs/1xbet_promokod_pri_registracii_bonus_segodnya.html позволяет получить бонус 100% на первый депозит, чтобы начать игру с максимальной суммой.
кухни на заказ в спб цены kuhni-spb-49.ru .
сколько стоит заказать кухню по размерам zakazat-kuhnyu-10.ru .
нарколог на дом нарколог на дом .
заказать кухню в рассрочку zakazat-kuhnyu-12.ru .
경주 아로마 안마 체험기
은은한 향과 함께 진행된 마사지가 인상적이었습니다.
홈케어 서비스라 이동 없이 받을 수 있었어요.
경주 아로마 마사지 안내
улучшение hero карточки улучшение hero карточки .
сколько стоит заказать кухню по размерам zakazat-kuhnyu-9.ru .
As operadoras de apostas Portugal oferecem uma forma fantástica para apostadores. A variedade de atividades e promoções presentes é considerável. Portanto, ao escolher essas casas de apostas portugal, http://hempelmepromotion.com/index.php/2026/02/25/as-melhores-casas-de-apostas-em-2023-guia-completo-9/, é relevante considerar as condições e formas de depósito que elas apresentam.
нарколог на дом в краснодаре нарколог на дом в краснодаре .
платный наркологический стационар платный наркологический стационар .
zahraniДЌnГ online casino, https://wraithpix.com/nejlepi-online-kasina-jak-vybrat-to-prave-pro-vas-11/ umoЕѕЕ€uje hrГЎДЌЕЇm vГЅjimeДЌnГ© moЕѕnosti her. RozmanitГ© hry a lГЎkavГ© bonusy lГЎkat novГ© zГЎkaznГky a zaruДЌujГ nezapomenutelnГ© zГЎЕѕitky.
Finding reliable bookmakers is crucial for avid bettors. Employing bookies not on GamStop, https://hotel-kenigauto.ru/bits4motorbikes/explore-non-gamstop-sportsbooks-freedom-in-betting/, players can enjoy a more extensive range of betting options. Such platforms often provide enticing bonuses and promotions that enhance the gambling experience.
выезд нарколога на дом narkolog-na-dom-v-krasnodare.ru .
заказать кухню с установкой zakazat-kuhnyu-10.ru .
нарколог на дом цены нарколог на дом цены .
Готовые проекты домов являются удобным вариантом для покупателей, стремящихся сэкономить время и средства.
каталог проектов домов из газобетона каталог проектов домов из газобетона.
Если вам нужны надёжные промышленные секционные ворота цена, мы предлагаем профессиональную установку и гарантийное обслуживание.
Профессиональный монтаж вместе с регулярным техническим обслуживанием гарантируют стабильную и безопасную работу ворот на протяжении многих лет.
врач нарколог на дом платный narkolog-na-dom-v-krasnodare-2.ru .
seo network internet-agentstvo-prodvizhenie-sajtov-seo.ru .
узнаваемость бренда баннер reklamnyj-kreativ14.ru .
заказать кухню по размерам zakazat-kuhnyu-9.ru .
kasyno polska opinie, https://cros9.yayin.com.tr/https://www.jpedukacja.pl/ sД… niezwykle zrГіЕјnicowane. DuЕјo graczy prezentuje swoje spostrzeЕјenia na temat ofert dostД™pnych w lokalnych kasynach. Wielokrotnie zauwaЕјajД… na jakoЕ›Д‡ zabaw oraz serwisu.
вавада зеркало мобильная версия 2026 вавада зеркало мобильная версия 2026 .
вызов нарколога на дом круглосуточно narkolog-na-dom-v-krasnodare-3.ru .
заказать индивидуальную кухню zakazat-kuhnyu-10.ru .
zahraniДЌnГ online casino, https://aamal.sa/2026/03/12/casino-vklad-100-k-ve-co-potebujete-vdt/ poskytuje hrГЎДЌЕЇm speciГЎlnГ zГЎЕѕitky ДЌi spoustu her. PЕ™es modernГm technologiГm majГ pЕ™ГleЕѕitost hrГЎt kdykoliv bД›hem dne a kdekoli.
нарколог на дом в краснодаре narkolog-na-dom-v-krasnodare.ru .
вывод из запоя москва клиника narkologicheskaya-klinika-trezvyj-vybor.ru .
online mexican pharmacy https://onlinepharmeasy.shop/# online pharmacies mexica
нарколог на дом анонимно narkolog-na-dom-v-krasnodare-1.ru .
melbet registration by email melbet registration by email .
Para quienes recién empiezan en el mundo de las apuestas online, las freebets sin depósito ofrecen beneficios concretos. No son sólo un gancho comercial; bien aprovechadas, pueden darte una primera experiencia real sin poner en juego tu plata. Entre sus ventajas, están: Además, fijate que la página use cifrado SSL (el candadito), lo que protege tus datos contra terceros. Para evitar estafas, desconfiá de las ofertas milagrosas que te lleguen por mail, redes sociales o mensajes de texto e ingresá siempre desde la web oficial del casino o desde los links de Argenpress.info, no desde enlaces sospechosos. Stake no solo se ha convertido en un fantástico criptocasino para jugar en alguna slot u otro juego de azar, sino también en un operador que ofrece cobertura en más de 50 deportes físicos y eSports, en donde el fútbol es el más seguido por sus usuarios.
https://www.hedeftercume.com/resena-de-tower-rush-la-emocion-animal-en-el-casino-online-de-latam/
Pirots 3 es un intrincado juego de tragaperras en línea situado en una cuadrícula de 6×7, que diverge de muchas mecánicas de juego tradicionales. En este juego, las ganancias no se forman a través de líneas estándar, sino mediante un mecanismo similar a los pagos por racimo. Si un pájaro cae junto a una gema de su color, la recoge, haciendo que los pájaros se muevan por la cuadrícula. Una vez concluida la fase de recogida, nuevos símbolos caen en cascada desde arriba. Como los pájaros han cambiado de posición, su potencial para conseguir ganancias adicionales aumenta. El juego presenta una tasa RTP del 94%, que se considera baja y viene acompañada de una alta volatilidad. El atractivo de las máquinas tragamonedas de alta tecnología en el casino. Pero, todavía estaba disponible en el condado de Peoria fuera de la ciudad. Blackjack en línea con cripto hotel Yeti-Way es una de las tragamonedas más nuevas de PlayN Go inspirada en la mitología nórdica, mientras que los diseñadores de NetEnt le dieron a este juego tres carretes y cinco líneas de apuesta. Como sacar dinero de las maquinas tragamonedas debemos apreciar este juego de tragamonedas, un jugador recibe su última carta boca arriba.
вызвать нарколога на дом вызвать нарколога на дом .
раскрутка и продвижение сайта раскрутка и продвижение сайта .
Web-based betting предлагает множество возможностей для покеристов. Casino Online, https://mlacoustic.com/how-to-register-at-slots-n-bets-casino-a-step-by-2/ открывает легкий доступ Рє многообразным играм. РРіСЂРѕРєРё РјРѕРіСѓС‚ достигать крупные РїСЂРёР·С‹ РЅРµ выходя РёР· РґРѕРјР°. Каждый отдельный может найти что-то РїРѕ интересам.
заказать кухню на заказ заказать кухню на заказ .
Honestly lmu88 impressed me more than I expected it would 🙂
diazepam prescription
нарколог на дом в краснодаре нарколог на дом в краснодаре .
заказать кухню через интернет заказать кухню через интернет .
online pharmacy review
Для людей, нуждающихся в оперативном старте строительства, готовые решения часто становятся оптимальным вариантом.
Они предлагают проверенные планы, готовые чертежи и подбор материалов.
планировка дома с мансардой https://proekty-domov4.ru/s-mansardoj/
BC Game kasyno, BC Game bonus bez depozytu to miejsce, gdzie masz możliwość rywalizować na wielorakich automat alat. Gracze będą zachwyceni bogaty zestaw opcji, a także spore nagrody. Z pewnością warto stracić owocną możliwość. Dołącz do społeczności BC Game kasyno już natychmiast i przekonaj się na żywo, jak świetnie da się wykorzystywać czas.
Также стоит обратить внимание на возможность адаптации типового проекта под индивидуальные условия участка.
проект домов с мансардой проект домов с мансардой.
Если вам нужны надёжные промышленные секционные ворота москва, мы предлагаем профессиональную установку и гарантийное обслуживание.
Качество материалов напрямую влияет на срок службы ворот, поэтому для промышленных моделей обычно применяют оцинкованную сталь или легкие алюминиевые сплавы с утеплением.
HranГ v cizГm online casinu nabГzГ vГЅjimeДЌnГ© moЕѕnosti zГЎbavy. UЕѕivatelГ© mohou obtГЕѕnД› poutavГ© bonusy a asistenci, coЕѕ posiluje zГЎЕѕitek ze hry. zahraniДЌnГ online casino, https://accelits.com/bezpene-zahranini-casino-jak-vybrat-to-spravne-2/ umoЕѕЕ€uje novГ© hernГ pЕ™ГleЕѕitosti pro vЕЎechny hrГЎДЌe.
casinos without GamStop, http://www.atlantic-city.net/best-non-gamstop-casinos-in-the-uk-your-ultimate/ offer players a chance to enjoy their favorite games without restrictions. These casinos provide a accessible environment for enthusiasts. Players can find numerous gaming options that enhance their experience. Choosing casinos without GamStop is ideal for those seeking flexibility in gaming while still ensuring protected play. Enjoy every moment during engaging in thrilling experiences.
вызов нарколога на дом краснодар narkolog-na-dom-v-krasnodare.ru .
Новое в категории: шлифовка паркета цена за м2
Подробности по ссылке: циклевка паркета цена за квадратный
online pharmacy review https://onlinepharmeasy.shop/# pharmacy technician certification online
психолог нарколог психолог нарколог .
продвижение сайта по трафику продвижение сайта по трафику .
нарколог на дом круглосуточно нарколог на дом круглосуточно .
мелбет фрибет 1000 мелбет фрибет 1000 .
saxenda order online
Накрутка поведенческих факторов может помочь увеличить активность пользователей и улучшить показатели сайта – программа по накрутке посетителей на сайт
legitimate online pharmacy
Internet gaming has become increasingly popular, especially with the popularity of Casino Online Slots, https://pratikagencies.in/index.php/2026/02/26/explore-the-explosive-world-of-slotsdynamite/. These thrilling games offer a wide range of themes and features to keep players engaged. Whether you prefer retro slots or modern video slots, there’s something for everyone in this lively world of digital fun. Make sure to practice cautious gaming while enjoying your time at Casino Online Slots!
реферат нейросеть реферат нейросеть .
нарколог на дом анонимно narkolog-na-dom-v-krasnodare.ru .
zahraniДЌnГ online casino, https://www.hovawart24.de/jak-vyuit-online-casino-bonus-bez-vkladu-prvodce/ skГЅtГЎ hrГЎДЌЕЇm napГnavГ© zГЎЕѕitky. S ЕЎirokou nabГdkou her a bonusЕЇ lГЎkГЎ novГЎДЌky. Jednoduchost hranГ z domova oslovuje mnoho lidГ.
online mexican pharmacy https://onlinepharmeasy.shop/# mexican online pharmacy reviews
BC Game Poland, bcgames-pl.com to niezwykła platforma hazardowa, na której graczom ekscytujące doświadczenia. Dzięki innowacyjnym funkcjom, użytkownicy są w stanie czerpać radość z gier. Intuicyjny interfejs oraz szeroka oferta zakładów sprawiają, że każdy może znaleźć coś dla siebie.
вызвать нарколога на дом вызвать нарколога на дом .
Готовые проекты домов — популярное решение для тех, кто хочет быстро и грамотно начать строительство.
Экономия на проекте позволяет улучшить другие аспекты строительства, например, выбрать более дорогую кровлю.
планировки 1 этажных домов планировки 1 этажных домов.
наркологическая клиника город наркологическая клиника город .
vavada com рабочее зеркало vavada com рабочее зеркало .
so this is kinda funny but my freind told me about this site like 2 months ago and i was skeptical right? but then i saw alot of positive posts about it on reddit and decided to give 9winz review a shot and honestly ive been pretty happy with it ever since
вавада оф сайт вавада оф сайт .
legitimate online pharmacy
a/b тест наружная реклама reklamnyj-kreativ12.ru .
технический переводчик услуги teh-perevod.ru .
Internet gaming have become increasingly widespread among players. By utilizing Casino Online Games, https://bodhicittachiropractic.chiropracticis.com/experience-thrilling-gaming-at-casino-slapkong-uk-2/, enthusiasts can enjoy a variety of engaging experiences right from their abodes.
улучшение креативов улучшение креативов .
Playing at gambling establishments outside GamStop offers an exciting opportunity for punters seeking options. With various games accessible, this atmosphere enhances your entertainment experience. casino outside GamStop, https://mamgry.pl/wp/2026/03/16/exploring-non-gamstop-casinos-your-ultimate-guide-2/ ensures you can have continuous fun without the usual limitations.
online pharmacy tech programs https://onlinepharmeasy.shop/# online pharmacy viagra
Way better than what I was using before, MostBet has faster load times and the customer support actually responds, where my old platform would take forever to get answers and constantly had technical problems. The whole thing just feels more reliable honestly.
Bij het kiezen van een online casino is het belangrijk om te letten op veiligheid en eerlijkheid. geen CRUKS casino, http://www.pisarevo.com/online-casino-s-zonder-cruks-jouw-gids-naar-vrije/ kan een aantrekkelijke optie zijn, maar controleer altijd de licenties en beoordelingen. Spelers zoeken naar betrouwbare platforms, dus wees altijd voorzichtig met gokken. Een goede ervaring hangt af van de veiligheden. Daarom is het essentieel om uitgebreid onderzoek te doen en de voorwaarden goed door te nemen. Vergeet niet je speelgedrag te beheren voor een plezierige ervaring.
vavada официальный сайт рабочее vavada официальный сайт рабочее .
нарколог на дом нарколог на дом .
вавада казино скачать вавада казино скачать .
технический переводчик стоимость teh-perevod.ru .
Hi there! tramadol online pharmacy great web site.
машинное обучение креативы reklamnyj-kreativ12.ru .
нейросеть студент бот нейросеть студент бот .
a/b тест баннеров reklamnyj-kreativ13.ru .
Ground fault sensors support preventive maintenance strategies by continuously monitoring electrical conditions. This allows early detection of potential failures. Check full overview at the link – https://earth-fault-indicator.com/
Casino Online, https://www.coworkhq.com.au/shiny-joker-online-casino-uk-a-new-era-of-gaming/ предлагает увлекательные возможности для РёРіСЂРѕРєРѕРІ. Развлекательные платформы предоставляют разнообразные РёРіСЂС‹. Призовые предложения усиливают интерес пользователей. Рзвестные сайты обеспечивают безопасность Рё одновременно комфорт.
Looking for the top non GamStop sites, https://watchxxxfree.club/best-non-gamstop-online-casinos-your-comprehensive/? Discover top-notch online casinos that offer an exciting gaming experience without GamStop restrictions. These platforms promise a safe environment for players seeking a thrill.
мелбет games официальный сайт мелбет games официальный сайт .
pyragai https://pyragaireceptai.lt
вавада регистрация в личном кабинете вавада регистрация в личном кабинете .
Als je op zoek bent naar een goksite zonder CRUKS, https://nimapropiedades.com.ar/betrouwbare-online-casino-s-buitenland-veilig-en/, dan zijn er tal van opties beschikbaar. Bij deze virtuele platforms kun je genieten van uitgebreide spellen en een snelle registratie. Kies de beste optie zonder beperkingen!
вавада казино скачать вавада казино скачать .
каркасные дома под ключ в спб цены — отличный выбор для тех, кто хочет быстро и экономично получить уютный и долговечный дом.
Благодаря этому удаётся снизить расход материалов и сократить сроки строительства.
Соблюдение технологий строительства и эксплуатации обеспечивает долговечность каркасных домов и комфорт для жильцов.
Уровень энергоэффективности напрямую определяется выбранным утеплителем и степенью герметизации здания.
Правильный подбор системы вентиляции повышает энергоэффективность и комфорт проживания.
Каркасная технология позволяет создавать разнообразные планировки и адаптировать дом под потребности семьи.
Своевременная профилактика и качественный монтаж фасадных элементов продлевают период эксплуатации.
Однако важно учитывать расходы на качественные материалы и соблюдение технологий.
Ответственный подход к выбору материалов и подрядчиков гарантирует надёжность и комфорт будущего дома.
скачать melbet на ios бесплатно скачать melbet на ios бесплатно .
Если вам нужна модули ардуино купить, у нас есть большой выбор качественных плат и аксессуаров для ваших проектов.
Неправильное соединение может привести к короткому замыканию и повреждению элементов схемы.
Мы предлагаем надежный канат грузовой гост 2688-80 купить для любых грузоподъемных задач.
Канат 2688-80 применяется в самых разных отраслях и обеспечивает надежность при больших нагрузках.
Канат имеет стандартизированные параметры, которые позволяют его легко интегрировать в существующие подъемные системы. Соблюдение допусков и размеров упрощает выбор и монтаж каната в механизмах.
Ключевыми преимуществами каната 2688-80 являются высокая разрывная нагрузка и устойчивость к усталостному разрушению. Еще одним плюсом является повышенная коррозионная стойкость при эксплуатации в тяжелых климатических условиях.
Канат показывает стабильные результаты при многократных циклах нагрузки и разгрузки, что снижает риск внезапных отказов. Увеличенный ресурс эксплуатации сокращает потребность в частой замене и ремонте.
Эксплуатационные условия напрямую влияют на выбор каната 2688-80 и режим его использования. Необходимо обращать внимание на нагрузочный профиль, температурный режим и контакт с химически активными веществами.
Правильная смазка и защита каната помогают продлить его срок службы и сохранить рабочие характеристики. Хранение в сухих условиях и защита от прямого контакта с агрессивными веществами также важны.
При покупке каната 2688-80 важно обращать внимание на сертификаты и соответствие стандартам качества. Опираясь на надежных поставщиков и положительные отзывы, можно снизить риск приобретения некачественного изделия.
Инвестирование в качественный канат 2688-80 окупается за счет снижения простоев и сокращения затрат на замену. Регулярная проверка и замена изношенных канатов обеспечивают безопасную и непрерывную эксплуатацию.
вызов нарколога на дом краснодар narkolog-na-dom-v-krasnodare.ru .
букмекерская компания мелбет melbetlogin.ru .
Eine fesselnde Atmosphäre des lightning roulette casino, https://jaybabani.com/ultra-wp-admin/?p=227432 begeistert Spieler an. Hier neuen Glücksspiel kombinieren Technik und Tradition, um dieses einmaliges Erlebnis zu schaffen. Ein elektrisierte Atmosphäre schafft jede einzelne Runde für etwas Herausragendes.
top non GamStop sites, https://cuentos.juanramonjimenez.es/wordpress/?p=51924 offer a unique chance for players seeking alternatives to traditional gambling platforms. These sites provide a wide range of selections, ensuring an exciting experience for everyone. Engage the vibrant online gaming community today!
Online Casino, https://gj.koiwai.biz/discover-the-excitement-of-shiny-joker-casino/ provides an entertaining experience for participants. With multiple games available, it addresses all tastes. Offers enhance the fun, while intuitive interfaces ensure enjoyment.
Bij no CRUKS casino, https://c-vu.ca/betrouwbare-online-casino-s-in-het-buitenland-een-4/ vind je een unieke ervaring. Zo’n casino biedt prachtige spelmogelijkheden. Gokkers kunnen profiteren van een scala aan spellen. Bescherming is garant, wat een extra pluspunt geeft.
мелбет мелбет .
vavada казино рабочее зеркало vavada казино рабочее зеркало .
мелбет скачать приложение на айфон мелбет скачать приложение на айфон .
vavada личный кабинет vavada личный кабинет .
melbet lite melbet lite .
Die immersive roulette, https://alqubisi.com/das-faszinierende-erlebnis-von-immersive-roulette-3/ ermöglicht ein fesselndes Spielerlebnis. Aufgrund modernster Technologie genießen die Spieler eine nahezu echte Casino-Atmosphäre. Außerdem ermöglicht es, direkt mit einem Dealer zu agieren.
Официальный сайт 7к казино предоставляет обширную библиотеку игровых автоматов и классических настольных развлечений.
Посетите 7к официальный сайт для быстрого доступа к играм и бонусам.
Сайт поддерживает обновления, добавляет новых поставщиков контента и улучшает работу платформы.
Рейтинговые таблицы и призовые фонды делают соревнования привлекательными.
Юридическая информация и лицензии представлены на официальном сайте для проверки прозрачности деятельности.
Условия участия публикуются на сайте и доступны для ознакомления до старта акций.
вавада казино вход вавада казино вход .
Online Casino Slots, https://equiwatch.co.nz/experience-the-thrill-of-gaming-at-savanna-wins-3/ offer entertaining experiences for players. With many themes and features, each game brings unique fun. Players can delight in amazing visuals and music that enhance gameplay.
Если вам нужна светодиодный модуль купить, у нас есть большой выбор качественных плат и аксессуаров для ваших проектов.
Практические эксперименты на макетной плате укрепляют теоретические знания и развивают навыки проектирования.
мелбет официальный сайт мелбет официальный сайт .
мелбет полная версия сайта melbetregistratsiya.ru .
согласование перепланировки в москве согласование перепланировки в москве .
vavada online casino официальный сайт vavada online casino официальный сайт .
polezno-vsem.ru polezno-vsem.ru .
In Nederland kiezen veel spelers voor een online casino zonder CRUKS, http://www.bikerentalbali.com/de-vrijheid-van-geen-cruks-casino-waar-kansspelen/. Dit biedt de mogelijkheid om te gokken zonder registratie bij het CRUKS-systeem. Veel mensen vinden het aantrekkelijker voor directe toegang te kunnen spelen. Dit geeft spelers meer keuze om hun favoriete games te ontdekken zonder beperkingen. Daarnaast zijn er vaak verschillende bonussen beschikbaar die de speelervaring verbeteren.
каркасный дом под ключ — отличный выбор для тех, кто хочет быстро и экономично получить уютный и долговечный дом.
Каркасные дома продолжают привлекать внимание за счёт экономичности и быстрого срока строительства.
При грамотном строительстве и обслуживании каркасные дома демонстрируют длительный срок службы и высокий уровень комфорта.
Энергоэффективность каркасных домов зависит от качества утеплителя и герметичности конструкции.
Механические или приточно-вытяжные системы с рекуперацией экономичны и удобны в эксплуатации.
Это удобно для молодых семей и тех, кто планирует изменять пространство со временем.
Фасадные решения для каркасных домов разнообразны и позволяют добиться желаемого внешнего облика.
Сокращение сроков строительства уменьшает общие эксплуатационные и организационные затраты.
При выборе подрядчика проверяйте портфолио и отзывы, чтобы избежать проблем в процессе строительства.
Мы предлагаем надежный канат грузовой гост 2688-80 купить для любых грузоподъемных задач.
Комбинация материалов и конструктивных решений дает канату высокую стойкость к механическим воздействиям.
Канат имеет стандартизированные параметры, которые позволяют его легко интегрировать в существующие подъемные системы. Унифицированные характеристики каната упрощают его применение в различных технологических схемах.
Ключевыми преимуществами каната 2688-80 являются высокая разрывная нагрузка и устойчивость к усталостному разрушению. Такие свойства позволяют применять канат в крановом хозяйстве и грузоподъемных системах.
Канат показывает стабильные результаты при многократных циклах нагрузки и разгрузки, что снижает риск внезапных отказов. Долговечность снижает общие затраты на обслуживание и замену.
Эксплуатационные условия напрямую влияют на выбор каната 2688-80 и режим его использования. Также учитываются способы крепления и возможные радиусы изгиба в механизмах.
Правильная смазка и защита каната помогают продлить его срок службы и сохранить рабочие характеристики. Применение специальных смазок снижает трение между жилками и защищает от коррозии.
При покупке каната 2688-80 важно обращать внимание на сертификаты и соответствие стандартам качества. Документы о сертификации позволяют убедиться в качестве и пригодности каната для конкретных задач.
Инвестирование в качественный канат 2688-80 окупается за счет снижения простоев и сокращения затрат на замену. Выбор качественного каната снижает общие эксплуатационные расходы и увеличивает производительность.
melbet registration login melbet registration login .
seo по трафику seo по трафику .
вавада офицальный сайт 2026 вавада офицальный сайт 2026 .
non gamstop roulette sites, https://smiletraveling.com/2026/03/15/exploring-non-gamstop-roulette-sites-a-5/ offer players an exciting alternative to traditional platforms. These kinds of sites allow access to numerous roulette games without the constraints of Gamstop. Users can enjoy enhanced freedom and choice while playing online.
Das aufregende Spiel das faszinierende immersive roulette, https://perfectlycleardiamonds.com/2026/03/17/immersive-roulette-das-online-spiele-erlebnis-der/ verändert die Art des Wettens. Spieler können eine immersive Erfahrung auskosten, während echte Dealer bei einem realistischen Ambiente agieren. Neuartige Technologie schafft es, das auf ein neues Niveau zu verbessern.
Online Casino Games, https://vorschau.schaller-digital.de/archives/165609 present an exciting journey for players. Using various variations, enthusiasts can opt for games that fit their tastes. Advanced graphics and immersive gameplay enhance the fun, making every session entertaining.
скачать мелбет скачать мелбет .
цветы сегодня http://cvejie-cveti.ru/ .
vavada casino сайт vavada casino сайт .
Bij een Casino zonder CRUKS, https://iladir.org/de-beste-buitenlandse-online-casino-s-in-2023/ kun je genieten van een spannende speelervaring zonder beperkingen. Veel spelers waarderen de vrijheid om te kiezen zonder registratiesystemen. Dit maakt gokken toegankelijker en leuker, hoe je ook verkiest. Ontdek nu het gemak van een online casino zonder CRUKS!
where internet partner prodvizhenie-sajtov-po-trafiku.ru .
seo портала увеличить трафик специалисты seo портала увеличить трафик специалисты .
продвижение сайта трафику продвижение сайта трафику .
What’s up, constantly i used to check weblog posts here in the early hours in the morning, because i like to find out more and more.
мел бет букмекерская контора официальный сайт мел бет букмекерская контора официальный сайт .
live roulette sites, https://davidcisneros.altervista.org/ultimate-guide-to-live-roulette-sites-in-the-uk-3/ offer an enthralling way to enjoy this popular casino game. Users can communicate with live dealers and sense the interactive atmosphere from their homes.
П„О± ОєО±О»ПЌП„ОµПЃО± online casino, https://matrebo.be/2026/03/16/casino-7/ ПЂПЃОїПѓП†ОПЃОїП…ОЅ П…П€О·О»О® ОµОјПЂОµО№ПЃОЇО± ОіО№О± П„ОїП…П‚ ПЂО±ОЇОєП„ОµП‚. О— ОіОєО¬ОјО± П„П‰ОЅ ПЂО±О№П‡ОЅО№ОґО№ПЋОЅ ОєО±О№ ОїО№ ОіОµОЅОЅО±О№ПЊОґП‰ПЃОµП‚ ОјПЂПЊОЅОїП…П‚ ОєО¬ОЅОїП…ОЅ П„О·ОЅ ОµПЂО№О»ОїОіО® О±ПЂО»О®. О•ПЂО№ПЂО»ООїОЅ, О· О±ПѓП†О¬О»ОµО№О± П„П‰ОЅ ПѓП„ОїО№П‡ОµОЇП‰ОЅ ПѓО±П‚ ОµОЇОЅО±О№ ПЂПЃОїП„ОµПЃО±О№ПЊП„О·П„О±.
vavada приложение vavada приложение .
вавада официальный сайт вавада официальный сайт .
seo специалист kursy-seo-12.ru .
проект перепланировки москва проект перепланировки москва .
Numerous players enjoy the thrill of winning in Online Casino, http://www.bikerentalbali.com/exploring-royal-oak-casino-online-games-your/. Through advanced technology, these platforms offer entertaining games. Although luck plays a role, strategies can enhance the experience and amplify chances of success.
melbet russia melbet russia .
продвижение сайта трафику продвижение сайта трафику .
мелбет букмекерская контора мелбет букмекерская контора .
услуги продвижения seo рязань timoly.ru сеотика.рф prodvizhenie-sajta-po-trafiku2.ru .
Het blijkt dat de populariteit naar online gokken toeneemt. Bij een geen CRUKS casino, http://www.dharmakayasunshine.com/casino-zonder-cruks-nederland-vrijheid-van-spelen/ heb je tal van alternatieven voor vermaak. De keuze aan spellen maakt een unieke ervaring voor elke speler.
узаконивание перепланировки квартиры pereplanirovka-kvartir12.ru .
регистрация на мелбет регистрация на мелбет .
seo продвижение по трафику кловер seo продвижение по трафику кловер .
vavada беттинг россия vavada беттинг россия .
vavada casino официальный сайт вход vavada casino официальный сайт вход .
live roulette casino site, https://www.tutores.escasto.ipn.mx/blog/2026/03/15/the-ultimate-guide-to-live-roulette-sites-5/ offers a captivating environment for players. With real croupiers, you can enjoy the enjoyment of spinning the wheel from your home.
ОЈП„О·ОЅ О±ОЅО±О¶О®П„О·ПѓО® ПѓО±П‚ ОіО№О± П„О± ОєО±О»ПЌП„ОµПЃО± ОєО±О¶ОЇОЅОї online, http://eliotzigmundjazz.com/2026/03/16/online-64/, ОјПЂОїПЃОµОЇП„Оµ ОЅО± ОІПЃОµОЇП„Оµ ПЂОїО»О»ОП‚ ОµПЂО№О»ОїОіОП‚ ПЊПѓОµП‚ ОП‡ОїП…ОЅ П†О±ОЅП„О±ПѓП„О№ОєО¬ ПЂО±О№П‡ОЅОЇОґО№О± ОєО±О№ ОµОєПЂО»О·ОєП„О№ОєОП‚ ПЂПЃОїПѓП†ОїПЃОП‚. О‘ОЅО±ОєО±О»ПЌП€П„Оµ П„О№П‚ ПЂОїО»О»ОП‚ ОµПЂО№О»ОїОіОП‚ ОєО±О№ ОґО№О¬О»ОµОѕП„Оµ ОµОєОµОЇОЅОµП‚ ПЂОїП… ПѓО±П‚ П„ПЃО¬ОІО·ОѕО±ОЅ П„Ої ОµОЅОґО№О±П†ОПЃОїОЅ.
доставка цветов онлайн https://cvejie-cveti.ru/ .
обучение продвижению сайтов kursy-seo-12.ru .
What’s Changed: https://victorybull.com/ruleta-en-internet-de-balde-tratar-a-la-ruleta-para-entretenimiento/
Expand details: https://idealmed.com.pl/blog/aktualnosci/2500-welcome-gambling-establishment-incentive/
букмекерская контора melbet букмекерская контора melbet .
All the latest here: https://rafaeltitd08530.theobloggers.com/46988077/indian-blue-movie-field-record-impact-and-authorized-problems
проектная организация для перепланировки квартиры proekt-pereplanirovki-kvartiry24.ru .
Current recommendations: https://juliusmany86319.pointblog.net/indian-blue-movie-business-history-effects-and-authorized-concerns-91287314
скачать мелбет приложение скачать мелбет приложение .
Casino Online, http://ricksfamilycarcare.com/?p=355765 открывает игрокам особенные возможности по азартных игр. Прогрессивные технологии формируют этот опыт удивительным. Зачастую участникам доступны разнообразные бонусы и акции, что увеличивает шансы на победу. Пробуйте возможности Casino Online!
сео инфо сайта увеличить трафик специалисты сео инфо сайта увеличить трафик специалисты .
скачать melbet на андроид vt-fiddle.com .
сео инфо сайта увеличить трафик специалисты prodvizhenie-sajta-po-trafiku2.ru .
согласование перепланировки согласование перепланировки .
melbet login & registration melbet login & registration .
скачать казино вавада на андроид скачать казино вавада на андроид .
вавада официальный вавада официальный .
Открой для себя азарт и выигрыши вместе с казино 7к зеркало.
Дополнительные опции, такие как турниры и программы лояльности, усиливают вовлечённость.
Het kiezen van een goksite zonder CRUKS, https://www.mobilificiosolinas.it/bet-sites-zonder-cruks-een-gids-voor-veilige/ is essentieel voor een zorgeloze speelsessie. Deelnemers kunnen genieten van verschillende spellen, zonder zich te druk te maken over registratiebeperkingen. Bescherming blijft belangrijk, dus kies goed.
продвижение сайта по трафику пример договора prodvizhenie-sajtov-po-trafiku.ru .
Exploring the universe of live roulette sites, https://wraithpix.com/best-live-roulette-online-casino-a-comprehensive/ can be thrilling. Players enjoy the real-time interaction with dealers and other participants. Whether you’re a novice or a pro, these venues offer excitement and potential rewards. Dive into the action and discover various strategies to enhance your gameplay. Live roulette sites provide a unique blend of comfort and the authentic casino atmosphere, making them a popular choice among online gamblers.
Finding the best casinos outside GamStop, http://www.nave.ufc.br/discover-the-best-casinos-outside-gamstop-9/ can be a game-changer for many players seeking excitement. These types of casinos offer independence to enjoy gaming without restrictions. Featuring diverse games and attractive bonuses, players can experience thrilling escapades.
seo интенсив kursy-seo-12.ru .
проект перепланировки квартиры проект перепланировки квартиры .
сео продвижение сайта по трафику сео продвижение сайта по трафику .
has anyone here tried microstar88 yet or is it just me, i heard some good things about it and was wondering if its actually worth checkin out or if its just another mediocre site that everyone talks about. situs microstar88 lemme know what u guys think bout it, would definitaly like some opinions before i jump in
Casino Online Slots, https://www.quickcar.hu/explore-richy-leo-online-casino-your-ultimate/ present one entertaining adventure for enthusiasts. Including countless themes and payouts, slots guarantee endless fun. Start the world of Casino Online Slots today!
цветы недорого москва с доставкой https://cvejie-cveti.ru .
no CRUKS casino, http://ampnvolt.com.my/?p=357199 biedt een unieke ervaring voor gokliefhebbers. In een diverse selectie aan spellen, kennen spelers altijd hun keuzes. Het casino biedt een veilige omgeving. Verken de spanning van het spel!
продвижение сайта по трафику продвижение сайта по трафику .
casinos not on GamStop, https://www.showanddisplay.com.hk/2026/03/13/discover-new-non-gamstop-casinos-your-gateway-to/ offer players a unique experience including a variety of games and possibilities that are not available on traditional platforms. Relax while exploring these exciting options for a more unique gaming journey.
seo с нуля seo с нуля .
проект перепланировки квартиры в москве проект перепланировки квартиры в москве .
сделать реферат сделать реферат .
раскрутка сайта по трафику prodvizhenie-sajtov-po-trafiku.ru .
Нужен быстрый и недорогой услуга вывоза мусора, чтобы быстро освободить квартиру после ремонта.
Рациональные маршруты и частота вывоза обеспечивают бесперебойный сервис и чистые улицы.
Ищете аренда автомобиля с водителем в новосибирске — позвоните нам, и мы подберём идеальный автомобиль с профессиональным водителем для комфортных поездок по Новосибирску.
Опытный водитель умеет выбирать оптимальные маршруты и обеспечивать безопасность пассажиров.
Online casinos have become increasingly popular due to their ease of access. Casino Online Games, https://techners.net/experience-the-thrill-of-playzax-casino-a/ offer diverse selections that engage players. With thrilling graphics and dynamic environments, they attract players from all over the world.
каркасные дома цены — отличное решение для быстрого и экономичного возведения уютного загородного жилья.
С чего начинается строительство — это проект и подбор стройматериалов.
Следствие — экономия на основании и сокращение сроков его устройства.
Важно также правильно организовать паро- и гидроизоляцию для долговечности конструкции.
Однако общая стоимость зависит от выбранных отделочных материалов и инженерии.
Action tips: https://www.grupafyi.pl/bez-kategorii/best-web-based-casinos-canada-within-the-2026-for-real-money-gambling/
Relevant tips: https://mypoeticside.com/user-62941
online casino zonder CRUKS, https://inspiring-readers.org/casino-s-zonder-cruks-de-vrijheid-van-spelen-6/ bieden spelers de mogelijkheid om te genieten van hun favoriete spellen zonder extra beperkingen. Deze platforms fournieren een breed scala aan slots, van klassiekers tot nieuwe releases. Spelers kunnen gemakkelijk hun favoriete spellen vinden en rechtstreeks beginnen met spelen, zonder zich zorgen te maken over registratiebeperkingen. Een online casino zonder CRUKS is geschikt voor wie vrij wil gokken in een veilige omgeving.
цветы рядом с доставкой https://cvejie-cveti.ru .
In the world of online gambling, gamblers often seek alternatives. casinos not on GamStop, https://www.dataprotect.sg/the-hidden-gems-gambling-sites-not-covered-by/ provide opportunities for those looking to enjoy gaming without restrictions. With a variety of games, promotions await, enhancing the experience.
Playing games of chance, like the wheel of fortune, can be exciting, especially when it’s available on platforms not linked to GamStop. roulette not on gamstop, http://www.fitcom.com.tr/musicaantiqua/exploring-roulette-betting-not-on-gamstop-a.html gives players a chance to enjoy playing without restrictions. Many players seek various venues that allow them to enjoy the thrill straight away. Finding options that do not participate in GamStop provides a unique opportunity to engage in this classic game. It’s essential to explore different sites before diving into the realm of online roulette.
продвижение сайтов по трафику продвижение сайтов по трафику .
согласование перепланировки в москве согласование перепланировки в москве .
Этого я не говорил.
Not on Gamstop Casinos, https://jaybabani.com/legacy-wp-admin/?p=212453 provide players with unique opportunities to enjoy gaming without restrictions. Such casinos give a diverse of exciting games along with generous bonuses, offering players to enhance their experience. With customizable payment options, players can easily fund their accounts and withdraw winnings without hassle. Explore the unique aspects of enjoying gaming at these casinos today!
https://matras-promtex.ru/
сделать реферат сделать реферат .
Amidst the world of modern entertainment, Casino Online, https://fukusi.sikaku-style.com/2026/02/experience-the-thrill-at-online-uk-rabbit-win-4.html excels as a favored choice for many. Offering a array of games, it ensures excitement and adventures. Enjoying Casino Online becomes easy, bringing the excitement of gambling right to your gadget.
Ищете аренда авто в новосибирске с водителем — позвоните нам, и мы подберём идеальный автомобиль с профессиональным водителем для комфортных поездок по Новосибирску.
Клиенты отмечают удобство и безопасность такой услуги в условиях большого города и непредсказуемых пробок.
Нужен быстрый и недорогой вывоз крупногабаритного мусора из квартиры москва, чтобы быстро освободить квартиру после ремонта.
Внедрение раздельного сбора даёт возможность переработать больше материалов и сократить захоронение мусора.
https://ruszaj-teraz.pl/
услуги по перепланировке квартир услуги по перепланировке квартир .
In een speeltuin zonder CRUKS kunnen spelers zonder restricties genieten van hun favoriete spellen. Het biedt een speciale gelegenheid te spelen zonder zich zorgen te maken over regels. Casino zonder CRUKS, https://klexcasa.com/betrouwbare-buitenlandse-casino-s-tips-voor/ is de perfecte plek voor degenen die willen spelen die op zoek zijn naar een avontuur.
услуги по перепланировке квартир услуги по перепланировке квартир .
Good evening fellow forum members, I have been using 8mbets Onlinecasino for the past fortnight and must say I am pleasantly suprised with the overall experience. The platform functions smoothly and the support team responds in a timely manner. I would recommend to anyone seeking a reliable option. Best regards, cheers.
no KYC casinos, https://neuromedia.mx/hollylynch/exploring-casino-options-without-id-the-future-of/ offer players a unique experience which enable seamless playing without cumbersome verification. The platforms ensure privacy while still offering a wide range of games. Enjoy the thrill of gaming without the need for KYC processes. Join the growing number of players who prefer the innovative approach to online gambling.
технический переводчик teh-perevod.ru .
каркасный дом под ключ в спб — отличное решение для быстрого и экономичного возведения уютного загородного жилья.
К тому же нынешние технические решения и материалы сделали каркасные дома значительно прочнее.
К несущему остову монтируют обшивки и теплоизоляционные материалы.
Уровень теплоизоляции определяет энергоэффективность каркасного дома.
В итоге каркасный дом представляет собой практичную альтернативу для тех, кто ценит скорость, экономию и комфорт.
Playing games of chance not on GamStop offers gamblers a chance to enjoy the favorite game without limitations. Whether you’re seeking excitement or aiming for big wins, roulette not on gamstop, https://carcredit36.com/2026/03/16/roulette-not-on-gamstop-a-guide-to-playing-safely/ provides thrilling experiences and new opportunities.
обучение seo обучение seo .
Старый паркет? стоимость шлифовки паркета профессиональное восстановление деревянного пола без пыли и лишних затрат. Удаляем царапины, потемнения и старое покрытие, возвращаем гладкость и естественный цвет. Используем современное оборудование, выполняем циклевку, шлифовку и лакировку паркета под ключ с гарантией качества и точным соблюдением сроков.
Надо поглядеть!!!
Casinos Not on Gamstop, https://www.abdgochizmetleri.com/exploring-uk-casino-sites-not-on-gamstop-851956066/ offer a unique opportunity for players seeking freedom. These platforms extend a wider selection of games and enhanced bonuses compared to traditional sites. With Casinos Not on Gamstop, players can enjoy a more flexible gaming environment.
цветы подарки рядом http://www.cvejie-cveti.ru .
умная нейросеть для учебы nejroset-dlya-referatov-8.ru .
luxury villas in phuket for sale villas-for-sale-in-phuket-1.com .
seo продвижение сайта по трафику seo продвижение сайта по трафику .
проект перепланировки квартиры для согласования проект перепланировки квартиры для согласования .
перепланировка квартиры москва pereplanirovka-kvartir12.ru .
The enjoyment of playing at an Online Casino, https://whitesmoke-seal-333777.hostingersite.com/experience-the-thrill-playing-io-online-casino-uk/ is extraordinary. By using cutting-edge technology, players can enjoy multiple games from the comfort of their homes. Promotions enhance the full gaming experience, attracting first-time users. Get started today and uncover the excitement of online gaming!
seo курсы seo курсы .
seo интенсив kursy-seo-12.ru .
переводчик технического текста в москве teh-perevod.ru .
Celebra tu dГa especial con Ruleta gratis en tu cumpleaГ±os, https://todrive.ch/2026/03/16/casino-sin-registro-cashback-automatico-para/. La diversiГіn y la adrenalina te esperan en este emocionante juego. Disfruta de la experiencia divertida mientras giras la rueda y recibes premios. ВЎHaz de tu fiesta algo Гєnico con esta entretenimiento brillante!
Nel mondo delle scommesse, i siti di scommesse, https://kyushu.food-stadium.com/news-flash/83539/ offrono opportunitГ straordinarie per chi ama il gioco. Con vari tipi di eventi sportivi, ГЁ facile trovare le migliori quote e promozioni. Г€ importante selezionare con attenzione per massimizzare i guadagni.
apartments in phuket thailand for sale apartments-for-sale-in-phuket-1.com .
phuket homes for sale real-estate-for-sale-in-phuket.com .
villas phuket for sale villas phuket for sale .
По моему мнению Вы допускаете ошибку. Давайте обсудим это.
Casinos Not on Gamstop, https://desifashionista.com/exploring-casinos-that-are-not-on-the-radar-3/ offer players a chance to enjoy gaming without restrictions. These platforms provide multiple options for slots. Players can experience entertaining gameplay and rewarding bonuses. Enjoy the freedom of Casinos Not on Gamstop!
luxury villas for sale in phuket luxury villas for sale in phuket .
thailand phuket apartments for sale thailand phuket apartments for sale .
запоминаемость рекламы reklamnyj-kreativ12.ru .
технический перевод teh-perevod.ru .
Experience the thrill of playing Online Casino Slots, https://seamarkamerica.com/explore-the-thrilling-world-of-playing-io-your/ and discover various themes and captivating visuals. With diverse options available, every spin can lead to adventure. Join now and begin your gaming journey!
Los casinos de criptomonedas estГЎn proliferando en el territorio espaГ±ol. Entre ellos, el casino cripto EspaГ±a, http://evraz-mag.ru/2026/03/17/las-multas-por-casinos-ilegales-en-espana-todo-lo/ destaca por su originalidad. AdemГЎs, ofrecen mГ©todos de transacciГіn que son razonables y rГЎpidas. ВЎLa vivencia nunca fue tan fascinante!
independent casino online, https://www.ezacomposit.com/the-rise-and-appeal-of-standalone-casinos/ offers players a distinct gaming experience. Players can appreciate a wide range of games, including slots, blackjack, and poker. Moreover, the comfort of playing from home attracts many users. With safe payment options, gamers can wager with peace of mind. Independent casino online also offers exciting bonuses and promotions, enhancing the overall experience. Join today to get the thrill of independent gaming like never before!
I casino esteri stranieri, https://galeriajoseamar.com/i-migliori-casino-online-stranieri-guida-completa-19/ offrono un’esperienza di gioco unica la quale attira giocatori da tutto il mondo. I loro possibilitГ si diversificano e potrebbero includere isure particolari per svagarsi.
apartments in phuket thailand for sale apartments-for-sale-in-phuket-1.com .
thailand phuket villas for sale villas-for-sale-in-phuket.com .
перепланировка москва pereplanirovka-kvartir11.ru .
Пожалуй, я соглашусь с вашей фразой
Casinos Not on Gamstop, https://uvc-2020.com/?p=987752 offer players unique opportunities to enjoy gaming without restrictions. These casinos provide multiple games and thrilling experiences. Gamers can explore different options while enjoying discretion and liberty.
apartments for sale thailand phuket apartments for sale thailand phuket .
Online Casino Games, https://www.windowgallery.in/discover-the-excitement-of-patrick-spins-casino-2.html offer a thrilling experience|provide an exciting adventure|deliver an exhilarating pastime|grant a captivating journey for players. With various options|choices|selections|alternatives available, from slots to table games, everyone can find something interesting|fascinating|engaging|entertaining to enjoy.
houses for sale in phuket real-estate-for-sale-in-phuket.com .
a/b тест наружная реклама reklamnyj-kreativ12.ru .
En EspaГ±a, los casinos online sin licencia representan un tema controvertido para los jugadores. Seducen a muchos, pero pueden llevar a fraudes. Los casinos sin licencia espaГ±a, https://www.jurgenvandervelde.com/descubriendo-los-mejores-casinos-online-fuera-de/ deben ser evitados para proteger tus finanzas.
узаконивание перепланировки квартиры pereplanirovka-kvartir11.ru .
интернет агентство продвижение сайтов сео интернет агентство продвижение сайтов сео .
I siti scommesse non aams, https://dev-rongdhonu.pantheonsite.io/2026/03/01/i-migliori-siti-scommesse-del-2023-guida-completa-2/ offrono ampia serie di opzioni per gli scommettitori del settore. Grazie a promozioni competitive, riescono a attrarre fidelizzati clienti. Tuttavia, ГЁ importante essere avvertiti sui rischi legati a questi luoghi.
villas phuket for sale villas phuket for sale .
condos for sale phuket condos for sale phuket .
freehold apartments for sale in phuket apartments-for-sale-in-phuket.com .
Вы допускаете ошибку. Предлагаю это обсудить.
Discover the top non GamStop sites for online gambling. These services offer a diverse range of games and exciting bonuses. Enjoy beloved games without restrictions. Choose the best non GamStop sites, http://risenews.df.unipi.it/2026/03/12/exploring-casino-companies-not-on-gamstop/ for an unrestricted gaming experience!
phuket property for sale phuket property for sale .
villas in phuket thailand for sale villas-for-sale-in-phuket.com .
согласование перепланировки под ключ согласование перепланировки под ключ .
https://toolbarqueries.google.com.sg/url?q=https://open.mit.edu/profile/01KM7D88EK0AW60RP27M6KFWJX/
усиление ссылок переходами internet-agentstvo-prodvizhenie-sajtov-seo.ru .
Online Casino, http://www.energysolutions.co.th/discover-the-excitement-of-oldcasino-casino-online-6/ – Internet Casino offers players an exciting experience with various selections. Players can enjoy poker while obtaining bonuses and rewards. The comfort of playing from home adds to the fun!
Je regarde brutal casino login principalement pour voir si l’interface reste claire et facile a utiliser. J’aime bien quand les categories sont bien separees et que tout parait naturel a parcourir. Je verifie aussi la vitesse d’affichage des pages les plus importantes. Une bonne ergonomie se voit tres vite sur ce type de plateforme.
nettikasino ilman rekisteröintiä, https://lightslategrey-chinchilla-230923.hostingersite.com/euteller-kasinot-nopein-ja-turvallisin-maksutapa/ tarjoaa pelaajille helpon tavan nauttia kasinopeleistä ilman monimutkaisia prosesseja. Korttipelaajat voivat aloittaa peliin hetkessä ja nauttia viihdyttäviä hetkiä rekisteröitymättä. Tämä erilainen pelialusta kiinnostaa yhä useampia viihteen etsijöitä.
non GamStop bookies, https://cazipcarsi.com/discover-bookies-not-on-gamstop-for-uninterrupted/ present a variety of betting opportunities for players who want to gamble outside the limitations of GamStop. Such platforms guarantee enjoyment without the usual limitations.
phuket condos for sale phuket condos for sale .
condos in phuket for sale condos in phuket for sale .
luxury villas for sale phuket villas-for-sale-in-phuket-1.com .
анализ баннеров reklamnyj-kreativ12.ru .
phuket property for sale thailand phuket property for sale thailand .
Negli ultimi anni, numerosi siti scommesse non aams, https://hormigonesjm.com/i-migliori-siti-scommesse-senza-limiti-di-vincita/ hanno profitti notevoli per gli utenti. Queste piattaforme offrono di scommettere su diverse eventi. Con promozioni, i giocatori riescono potenziare le loro vincite. Tuttavia, ГЁ cruciale prestare attenzione a queste ultime piattaforme, visto che la sicurezza ГЁ cruciale. Scegliere siti scommesse non aams puГІ anche un’interessante possibilitГ per entrare in gioco.
luxury villas for sale phuket villas-for-sale-in-phuket.com .
mostbet casino app mostbet casino app .
Идея отличная, согласен с Вами.
Finding the perfect platform for gambling can be challenging. The best non GamStop sites, https://partsnest.velocity-87bdec47.herositepro.com/exploring-non-gamstop-casinos-in-the-uk-897434550/ offer multiple games and versatile options for players. Enjoying a exciting experience is what matters most in this ever-changing industry. Experience liberty while playing at any of the best non GamStop sites, and explore the exciting world of online gambling without restrictions.
структура креатива реклама структура креатива реклама .
Playing at a casino ffor real money brings more energy to the gaming experience.
A lott of players appreciate practical payment
options, simple rules, andd a wide variety of games.
When everything iis easy to access,the experience feels
morre comfortable. This creates a balanced and satisfying atmosphere.
продвижение сайтов во франции internet-agentstvo-prodvizhenie-sajtov-seo.ru .
phuket thailand apartments for sale apartments-for-sale-in-phuket.com .
phuket luxury apartments for sale apartments-for-sale-in-phuket-1.com .
luxury villas in phuket for sale villas-for-sale-in-phuket-1.com .
property in phuket for sale property in phuket for sale .
Casino Online, http://nekokapuri.s1009.xrea.com/2026/02/23/the-rise-of-online-instant-casinos-a-new-era-in-2/ предоставляет множество вариантов для любителей. С огромным игр каждый найдет что-либо для себя. Независимо от ваш стиль игры, Casino Online обеспечивает увлекательный процесс.
luxury phuket villas for sale villas-for-sale-in-phuket.com .
seo продвижение и раскрутка сайта seo продвижение и раскрутка сайта .
nettikasino ilman rekisteröintiä, https://electionpakistan.com/kasinopelit-ilman-rekisteroitymista-jannitysta/ tarjoaa mahdollisuuden pelata ilman tarpeellista ja nauttia pikaisista pelihetkistä. Mikäli haluat kokeilla uutta tapaa pelata, nettikasino ilman rekisteröintiä on erityinen valinta. Kasino tarjoaa laajan valikoiman pelivalikoimaa ja kiinnostavia bonuksia.
non GamStop bookies, http://planetxenos.com/exploring-non-gamstop-sports-betting-sites-a-7/ provide a superb choice for bettors looking for variety. They let gamers to take pleasure in their favorite games without barriers.
Да… наверно… чем проще, тем лучше… все гениальное просто.
фильмы онлайн, http://pembrokeshire-herald.com/28529/pembroke-tragic-death-for-happy-and-joyful-young-carer/ подают зрителям огромное количество эмоций. Насладиться любимый тип теперь реально в любое время и в любом месте. Комфортный доступ к картинам онлайн делает такое невероятным.
переводчик технического текста в москве teh-perevod.ru .
Esplorare alcuni siti con prelievo immediato, https://ibtikaruae.com/home/i-migliori-siti-di-scommesse-con-pagamento-2/ ГЁ una possibilitГ fascinante per coloro che desiderano trarre risorse in tempi brevi. Con questi portali, ГЁ facile ottenere ai propri senza ritardi.
Щебень гравийный можно купить быстро и надежно через купить гравийный щебень в подмосковье с доставкой.
Его используют в бетонных смесях для повышения механических свойств.
улучшение креативов улучшение креативов .
Извините, ничем не могу помочь. Но уверен, что Вы найдёте правильное решение.
If you’re exploring digital wagering, a non UK casino site, https://espacios.unico.com.co/exploring-non-uk-casino-sites-a-guide-for-players/ offers various options. You can find exciting games and attractive rewards. Enjoy easy navigation today!
анализ креативов анализ креативов .
internet seo internet-agentstvo-prodvizhenie-sajtov-seo.ru .
нейросеть реферат онлайн нейросеть реферат онлайн .
seo partner prodvizhenie-sajtov-v-moskve4.ru .
mostbet app download mostbet app download .
تنظم الفقرات ثلاث أسئلة أساسية وتُجيب عنها بصورة صريحة.
888starz تحميل https://hygienicslife.in/2025/08/19/888starz-%d8%aa%d8%ad%d9%85%d9%8a%d9%84-%d9%81%d9%8a-%d9%85%d8%b5%d8%b1-%d8%aa%d8%ab%d8%a8%d9%8a%d8%aa-apk-%d9%88%d9%86%d8%b3%d8%ae%d8%a9-ios-%d9%85%d8%b9-%d8%b4%d8%b1%d8%ad-%d9%85%d9%81/
Welcome to Cosmic Spins casino, https://training.insurancesplash.com/a-comprehensive-review-of-plastic-formers-7/, where the excitement of gambling meets out-of-this-world bonuses. Explore multiple choices that will keep you thrilled for hours!
Delve into the thrilling world of Casino Online Slots, https://radiantlighteventrentals.com/exploring-the-exciting-world-of-mr-jones-online-2/, where excitement meets luck. Players can experience a variety of games, promising amazing rewards.
Эта версия устарела
Сегодня Сѓ нас есть уникальная возможность познакомиться СЃ захватывающими историями – дорамы смотреть онлайн, https://www.takcare.se/new-freediver-initiatives-doing-the-impossible/. Определите жанр, который вам близок, Рё погрузитесь РјРёСЂ неожиданных поворотов Рё СЏСЂРєРёС… эмоций. Любая дорам предлагает особый опыт, который запоминается надолго. Наслаждайтесь просмотром РІ компании Рё делитесь впечатлениями!
технический переводчик в москве teh-perevod.ru .
casino non aams, http://www.kli.lt/10-600609684/ – I consiglio i casino non aams per scommettere in modo alternativo. Questi siti offrono eccellenti scelte di intrattenimento, bonus esclusivi. Non perdere l’opportunitГ di esplorare qualcosa di innovativo.
нейросети для студентов нейросети для студентов .
улучшение hero карточки улучшение hero карточки .
ПРИКОЛЬНЫЙ МУЛЬТЯГА
Chicken Road casinos, https://avicounsel.com/the-endless-possibilities-of-free-unlocking/ – At Chicken Road gambling establishments, players can enjoy a variety of exciting games. Including slots to table games, the environment is unmatched. Visitors often speak highly the treatment, making it a go-to destination.
mostbet casino app mostbet casino app .
продвижение сайта франция prodvizhenie-sajtov-v-moskve4.ru .
nettikasino ilman rekisteröintiä, https://growingsmes.org/kolikkopelit-ilman-rekisteroitymista-helppoa-ja-6/ tarjoaa pelaajille vaivattoman tavan nauttia kasinopeleistä. Erittäin nopeaa, sillä pelaaminen tapahtuu ilman tarvetta rekisteröityä. Tutustu monia pelejä ja tunneloi upeista bonuksista!
Playing in the realm of Casino Online Games, https://creotechsolutions.net/frontend/web/blog/myspins-casino-sportsbook-your-ultimate-gaming-6/ offers excitement like no other. Players can enjoy a variety of gambling selections from anywhere. Explore your luck today!
прогноз доли выбора карточка reklamnyj-kreativ12.ru .
Подтверждаю. Я согласен со всем выше сказанным.
турецкие сериалы на русском, https://www.parks-und-gaerten.de/schlosspark-koenig-ludwig-i/statue/ стали настоящим феноменом. Они захватывают внимание своими сюжетами. Каждый выпуск восхищает зрителей, даря им яркие моменты. Эти сериалы особенно захватывают чувства и вызывают обожание.
улучшение hero карточки улучшение hero карточки .
QuickWin Casino EspaГ±a, https://gnanajyothifoundation.org/quickwin-casino-espana-tu-destino-de-juegos-en-7/ es una plataforma ideal para los fanГЎticos de juegos de azar. Ofrece amplia gama de tragamonedas y un entorno confiable. AdemГЎs, las promociones son interesantes, lo que mejora la experiencia de juego. ВЎГљnete hoy a QuickWin Casino EspaГ±a y explora lo mejor del azar!
mostbet download apk mostbet download apk .
Вы попали в самую точку. В этом что-то есть и мне кажется это очень хорошая идея. Полностью с Вами соглашусь.
Web betting has become increasingly popular, especially with ways like the non GamStop PayPal casino, https://valcke.odinsportswear.com/paypal-casinos-not-blocked-your-ultimate-guide-to/. These platforms offer hassle-free transactions and a wide array of games to enjoy, ensuring players a dynamic experience. Enjoying online casinos without GamStop restrictions allows for increased freedom in gameplay and monetary management. With protected payment options like PayPal, players can focus on having fun while confirming a smooth gaming experience.
Прошу прощения, что я Вас прерываю, но я предлагаю пойти другим путём.
сайт pin up casino, https://pin-up-casino-d7vwo.sbs предлагает разнообразный выбор игр. Здесь можно испытать счастье и прибыль. На платформе действуют выгодные условия для участников.
профессиональное продвижение сайтов prodvizhenie-sajtov-v-moskve4.ru .
Чтобы купить светодиодные оборудование, посетите магазин arlight.
Для коридоров и общих зон подходят бюджетные и долговечные светильники.
Продвижение сайта невозможно без анализа поведенческих факторов. Они показывают, насколько ресурс соответствует ожиданиям пользователей. Улучшение этих показателей помогает повысить эффективность SEO стратегии. Подробнее по ссылке – накрутка поискового трафика
Exploring the universe of non UKGC casino sites, https://aff.dominhhai.com/2026/03/14/non-uk-regulated-casinos-accepting-uk-players-a/ offers participants an dynamic experience. These platforms often provide unique games and attractive bonuses that draw in customers.
Надёжно и недорого организуем вывоз строительного мусора в москве недорого, быстро вывозим мусор с погрузкой и вывозим по доступным ценам.
Контейнеры под разные фракции необходимо маркировать и ставить в доступных точках.
Поздравляю, отличная мысль
In the world of betting, the online casino, gambling sitesnot on gamstop offers unique experiences. Players can experience various games from the comfort of their homes. The rise of technology has made it convenient for enthusiasts to play their favorite games instantly.
Casino Online, https://smartfinancepro.site/step-by-step-guide-to-the-merlin-casino-12/ – The realm of Casino Online has transformed entertainment. Players now enjoy accessibility to various games on their fingers. The pleasure of wagering is just a click away. Experience the adventure today!
https://forpost-sevastopol.ru/newsfull/5386709/lionel-messi-pokoril-otmetku-v-900-golov-za-kareru.html
продвижение в google продвижение в google .
прогноз доли выбора карточка прогноз доли выбора карточка .
Отличная фраза
фильмы rezka, http://pic.murakumomura.com/2009/06/23/post_281/ предоставляют зрителям уникальную возможность погрузиться в мир кино. Любой жанры представляют своих уникальных поклонников. Качество видеосъемки в дополнение сценарии вдохновляют с целью. Новые фильмы всегда появляются, радуя зрителей по всему миру. Escolha Filme Rezka!
mostbet app mostbet app .
Я считаю, что Вы ошибаетесь. Предлагаю это обсудить. Пишите мне в PM, поговорим.
сайт pin up casino, https://pin-up-casino-9i477.top/ предлагает азартные активности для ценителей адреналина. Здесь возможно выиграть денежные призы и испытать удачу. Бонусные предложения порадуют каждого.
нейросеть для школьников и студентов nejroset-dlya-referatov-6.ru .
QuickWin Casino EspaГ±a, https://penedesautomocio.com/quickwin-casino-espana-tu-puerta-a-la-diversion-y-19/ es una plataforma de juegos en lГnea renombrada que brinda a los usuarios una amplia variedad de mГЎquinas tragamonedas. Con una apariencia fГЎcil de usar, los clientes pueden explorar sin problemГЎticas. AdemГЎs, disponibiliza promociones seductores, lo que transforma la experiencia aГєn mГЎs gratificante.
интернет продвижение москва интернет продвижение москва .
Этот топик просто бесподобен :), мне очень нравится .
Exploring the realm of online gaming, the non GamStop PayPal casino, https://pkiener.com/exploring-non-gamstop-uk-casinos-find-your-ideal/ offers distinctively tailored experiences for players. With fast transactions and protected methods, players can enjoy thrilling games without restrictions. Likewise, these casinos provide a wide range of gaming options, making them enticing for everyone. Dive into a broad selection of games and enjoy hassle-free betting at the non GamStop PayPal casino today!
Welcome to Cosmic Spins casino, https://valcke.odinsportswear.com/the-enchanting-world-of-cosmicspins-a-journey/, where the fun never ends! Players can enjoy a wide variety of games, from slots to live gaming options. Join now and unleash your luck!
A nГ©pszerЕ± online jГЎtГ©kokkal bЕ‘vГјlЕ‘ magyar online casino, https://waterfallhikeusa.com/bulapictures/az-online-kaszinok-vilaga-hogyan-nyerjunk-es/ izgalmat kГnГЎl. A felhasznГЎlГіk kГ¶nnyedГ©n kihasznГЎlhatjГЎk a rengeteg bГіnuszt Г©s jutalmat.
It is actually a nice and useful piece of info. I am glad that you shared this helpful information with us. Please keep us informed like this. Thanks for sharing.
гы бурундук=)
сайт pin up casino, pin up casino играть на деньги предлагает уникальные возможности для любителей азартных игр. Здесь вы найдете многообразные слоты и игры. Так как хотите нажиться в мир азарта, присоединяйтесь сайт pin up casino и наслаждайтесь от развлечений.
жена друга порно жена друга порно .
Online Casino, https://devbhoomiuknews.com/archives/16666 – Virtual Casino delivers an exciting array of games. Players can enjoy poker from the comfort of their residence. Using bonuses and promotions, acquiring is more attainable than ever. Join an Online Casino today and boost your chances!
нейросеть для рефератов нейросеть для рефератов .
ии для студентов nejroset-dlya-referatov-6.ru .
Прошу прощения, что я Вас прерываю, но не могли бы Вы дать больше информации.
Смотреть захватывающие фильмы онлайн бесплатно, https://afroasiannetworks.com/2016/02/03/hello-world/ стало просто благодаря множеству платформ. Выбор очень впечатляющий, и каждый сможет найти подходящее. Это идеальный способ провести время!
Согласен, это отличная мысль
pin up казино, pin-up-casino-4a2lv.sbs предлагает уникальные возможности для игроков. Здесь можно найти множество игровых автоматов на любой вкус. Подарки и щедрые предложения делают развлечение еще более привлекательным.
casinos sin licencia, http://max-happacher.de/2026/03/los-casinos-sin-licencia-en-espana-todo-lo-que/ – La popularidad de los salones de juegos sin licencia ha crecido en los Гєltimos aГ±os. Sin embargo, estos plataformas pueden ser inseguros para los jugadores. Es fundamental comprobar la legalidad antes de participar.
жжет чертяга!!!
online casino, online casino provides a exciting experience for players. With various games to choose from, players can enjoy the ease of playing from home. Incentives enhance the total gaming experience.
A legГєjabb magyar online casino, https://www.anqifire.com/2026/03/16/online-szerencsejatek-oldalak-a-legjobb-lehetsegek-5/ Г©lmГ©nyeket kГnГЎl a jГЎtГ©kosoknak. Itt vГЎltozatos jГЎtГ©k talГЎlhatГі, mint ahogy a nyerЕ‘gГ©pek Г©s kГЎrtyajГЎtГ©kok. A jutalmak is csГЎbГtГіak, ami mГ©g szГіrakoztatГіbbГЎ teszi az idЕ‘tГ¶ltГ©st. Fedezd fel a lehetЕ‘sГ©geket a magyar online casino vilГЎgГЎban!
Discover the finest non UK casino sites for rewarding gaming experiences. These platforms offer numerous games, generous bonuses, and excellent customer service. Explore innovative features and enjoy exceptional play! best non UK casino sites, https://www.seabairgroup.com/exploring-non-uk-online-casinos-a-comprehensive-4/ provide reliable environments for all players.
как скачать помогите
Online gambling has evolved significantly, with many players seeking options outside traditional regulations. A non GamStop site, https://www.treenj.com/starsoil/legit-non-gamstop-casinos-play-safely-and/ is a fantastic choice for those looking for more freedom. These types of platforms offer captivating games and substantial bonuses, allowing users to engage fully. Users can enjoy diverse betting options, making their experience more dynamic. Furthermore, various players appreciate the autonomy that comes with a non GamStop site, enabling them to bet without limits.
Я оцениваю широкий охват темы в статье.
нейросети для студентов нейросети для студентов .
anyone familiar with ipl live 2026 thinking about trying it ty
нейросети для студентов нейросети для студентов .
друг мужа трахает жену друг мужа трахает жену .
ии для школьников и студентов nejroset-dlya-referatov-6.ru .
реферат нейросеть реферат нейросеть .
Online Casino Slots, https://jpconstrucao.com.br/casinoonlineslot220230/midnight-wins-casino-sportsbook-experience-gaming/ present a captivating experience for players. With diverse themes and fascinating gameplay, many participants find their perfect game. Join the fun and navigate exciting cash today!
нейросеть для учебы нейросеть для учебы .
Вы талантливый человек
В мире азартных игр pin up казино, пин ап казино привлекает игроков своими уникальными предложениями. Здесь можно найти соблазнительное множество игр, от игровых автоматов до традиционных развлекалок. Платформа привлекает щедрыми бонусами, что усиливает интерес к играм. Каждое включение в мир pin up казино — это уникальный шанс на выигрыш, который очаровательно радует.
Бесподобная фраза, мне очень нравится 🙂
В современном мире многие предпочитают смотреть фильмы онлайн бесплатно, https://prettywhite.co/aj-smith-cooler/. Это удобно и просто. Вы можете отыскать любую картину на свой вкус, не выходя из дома. Это создает возможность наслаждаться кино в любое время.
Why visitors still make use of to read news papers when in this technological world everything is available on net?
нейросеть для учебы nejroset-dlya-referatov-7.ru .
ии для студентов nejroset-dlya-referatov-2.ru .
A kivГЎlГі vГЎlasztГЎs a szГіrakozГЎsra a magyar online casino, https://bonabery.com/online-kaszino-oldalak-magyarorszagon-a-legjobb-13/, ahol a szГіrakozГЎs Г©s a nyeremГ©ny talГЎlkozik. Az Г©lvezetek pГЎratlan Г©s szГіrakoztatГі pillanatokat kГnГЎl.
Welcome to the realm of Chicken Road casinos, https://johntpeters.com/the-evolution-of-gaming-from-pixels-to-virtual-6/, where adventure awaits every visitor. With a variety of games, from slots to poker, visitors can take part in countless options. Also, the vibe is lively, making it ideal for meeting friends. Don’t miss out on the possibility to visit Chicken Road casinos!
Los salones de juego online legales ofrecen una experiencia de usuario segura y divertida. Al elegir un sitio seguro, los clientes pueden explotar de opciones variadas con certificaciones de legalidad. Los casinos online legales, https://jaybabani.com/material-wp-admin/?p=228374 son la superior opciГіn para jugar en la web.
Чтобы купить светодиодные оборудование, посетите фирменный магазин arlight.
Правильная утилизация старых ламп и комплектующих помогает уменьшить вред для окружающей среды.
нейросеть для студентов онлайн nejroset-dlya-referatov-1.ru .
нейросеть для студентов онлайн нейросеть для студентов онлайн .
Очень полезная информация
If you’re looking for a non GamStop site, https://www.sterling-store.co/exploring-casinos-not-on-gamstop-uk-a-2-2/, many options exist for online gambling enthusiasts. These platforms offer a wide variety for games and exciting promotions. Players can enjoy unrestricted access while experiencing captivating experiences. Remember, always practice smart wagering for a better experience on these sites.
Надёжно и недорого организуем вывоз мусора, быстро вывозим мусор с погрузкой и вывозим по доступным ценам.
Это повышает эффективность и уменьшает число пустых рейсов.
реферат через нейросеть реферат через нейросеть .
Щебень гравийный можно купить быстро и надежно через купить гравийный щебень.
Его используют в бетонных смесях для повышения механических свойств.
купить цветы дешево москва https://dostavka-cvetov-moskva495.ru .
ролики с женой друга ролики с женой друга .
ии для студентов nejroset-dlya-referatov-5.ru .
Я думаю, что Вы не правы. Предлагаю это обсудить. Пишите мне в PM.
pin up казино, https://pin-up-casino-3i4tw.sbs/ предлагает уникальные возможности для игроков, которые ищут адреналин. Здесь вы найдете огромный выбор игр и красочные бонусы. Присоединяйтесь к сообществу любителей и испытайте удачу!
нейросеть для рефератов нейросеть для рефератов .
Online Casino Games, http://procurement.gov.ck/wordpress/?p=79125 deliver a thrilling excitement for players. With numerous options such as slots, poker, and blackjack, gamers can find something engaging. Enjoy the convenience of playing from home!
Отличная мысль
В мире кино существует множество жанров, и дорамы смотреть онлайн, https://anyerglobe.com/img-20200919-wa0056/ — одна из самых популярных форматов. Эти корейские сериалы завораживают сюжетом а эмоциями. Практически любой эпизод переполнен интригующими личностями и непредсказуемыми поворотами. Вы можете наслаждаться в атмосферу дорамы, находясь на диване. Не упустите возможность узнать самые последние новинки и классические хиты!
Охотно принимаю. Тема интересна, приму участие в обсуждении. Вместе мы сможем прийти к правильному ответу.
Within the ever-evolving world of online casino, Casino Bonus Osterreich, enthusiasts seek entertainment and potential rewards. Diversity of games enhances the overall experience, captivating new fans.
casino online iceland, http://www.d1048604-5.blacknight.com/besta-spilaviti-a-netinu-hvernig-a-a-velja-retta/ er það fyrir frábæra val fyrir spilara að hafa gleði à hentugum vettvangi. Hér það er ýmsir leikur sem hefur verið fyrir frábærum henta.
Many players seek options for online gambling. Some find options to explore sites not using GamStop, https://fashionlanka.lk/guide-to-sites-not-with-gamstop-explore/. These sites give more flexibility to players who wish to gamble without restrictions. Enjoy captivating gameplay and diverse options that cater to all preferences.
нейросеть для учебы нейросеть для учебы .
hd видео с женой друга hd видео с женой друга .
Я хотел бы с Вами поговорить.
\npin up казино, https://pin-up-casino-7fs2v.xyz предоставляет уникальные шансы для участников. Здесь можно открыть множество автоматы и поддержку. Пробуй сейчас и познай мир интересных развлечений от pin up казино!
нейросеть студент бот нейросеть студент бот .
Спасибо за помощь в этом вопросе.
non GamStop horse racing, https://www.missionpost.co.uk/2026/03/10/the-current-state-of-uk-horse-racing-not-on-2/ offers enthusiasts an exciting alternative for betting. Whether you seek exciting races or rewarding opportunities, this platform has it all. Enjoy a rich selection of events and versatile wagering options, ensuring a unique experience every time. Join the fun today!
Los sitios de apuestas online chile ofrecen juegos emocionantes a los jugadores. Con plataformas digitales, los apostadores pueden probar diversos juegos desde la facilidad de sus hogares. AdemГЎs, los incentivos atractivos incentivan la participaciГіn en casinos online chile, https://mku-autoteile.de/descubre-los-mejores-casinos-online-en-chile-2/.
нейросеть реферат онлайн нейросеть реферат онлайн .
I started writing down one thing at the end of every day — what I actually managed to do. Not a to-do list, not plans. Just one small win. It’s surprising how quickly it shifts your perspective.
Online Casino, https://kempol.de/the-ultimate-guide-to-casino-lumibet-uk-explore/ – Web-based Casino предоставляет игрокам уникальную возможность состязаться РІ азартных играх РёР· удобства РёС… РґРѕРјР°. Сотни РёРіСЂ ждут вас, чтобы приобщить незабываемые эмоции Рё возможность выиграть. РќРµ упустите возможность, изучая популярные РёРіСЂС‹!
нейросеть реферат онлайн нейросеть реферат онлайн .
порно с женой друга порно с женой друга .
Разрешите помочь Вам?
Погрузитесь в мир увлекательных сюжетов, где главные герои переживают различные приключения. дорамы смотреть онлайн, https://247texasdriversafety.com/logo/ стало доступным, и теперь вы можете наслаждаться захватывающими историями в любое время. Каждая серия — это шанс открывать новые эмоции.
гы во гонят….
В мире азартных игр любой игроки ищут способы заработать. pin-up casino, pin up casino личный кабинет предлагает особенные игры и достойные бонусы. Занимаясь атмосферу казино, игроки могут испытать азарт.
чат нейросеть для учебы nejroset-dlya-referatov-5.ru .
цветы дешево доставка https://www.dostavka-cvetov-moskva495.ru .
Negli ultimi anni, i siti scommesse non aams stanno guadagnando popolaritГ tra gli appassionati. Queste piattaforme offrono quote di gioco piГ№ competitive. Tuttavia, ГЁ fondamentale valutare la affidabilitГ prima di registrarsi. Inoltre, i offerte sono spesso piГ№ generosi su questi portali. Infine, i siti scommesse non aams, http://cinebhojpuria.in/siti-scommesse-non-aams-senza-documenti-guida-3/ possono offrire esperienze di gioco uniche, ma ГЁ cruciale giocare con cautela.
Exploring betting websites that focus on user experience is essential for players seeking thrill. Among the diverse selections, sites not using GamStop, http://www.qsttech.com/everything-you-need-to-know-about-casinos-not/ provide unique experiences for unfettered fun. Enjoy the freedom while gaming and choose from a variety of platforms.
сделать реферат сделать реферат .
реферат через нейросеть реферат через нейросеть .
Я оцениваю четкую структуру статьи, которая делает ее легко читаемой и понятной.
Могу поискать ссылку на сайт, на котором есть много статей по этому вопросу.
non GamStop horse racing, https://axis-chile.cl/2026/03/10/the-thrill-of-horse-racing-a-gambler-s-paradise/ offers thrilling opportunities for bettors seeking excitement. Using various platforms, enthusiasts can discover unique markets. This guarantees an engaging experience, freeing users from restrictions. Whether you’re a newcomer or a seasoned, there’s something for everyone.
реферат нейросеть реферат нейросеть .
Mostbet casino, https://www.primariarojiste.ro/2026/02/27/trustpilot-reviews-a-comprehensive-guide-to-6/ открывает игрокам обширный выбор РёРіСЂ. Рффективные подарки Рё выгодные условия делают процесс РёРіСЂС‹ захватывающим.
Прошу прощения, что вмешался… Я разбираюсь в этом вопросе. Приглашаю к обсуждению. Пишите здесь или в PM.
online casino, hugo casino norge provides an exciting way to delight in gambling from the comfort of your home. With various options available, players can pick their favorites and take a chance.
нейросеть онлайн для учебы nejroset-dlya-referatov-3.ru .
Конечно. Так бывает. Давайте обсудим этот вопрос.
В мире азартных игр азартных игр pin-up casino, pin-up-casino-zdnyi.xyz выделяется своим визуальным оформлением. Здесь предоставляются разные игры, которые удовлетворят любого игрока. Каждое посещение станет незабываемым событием.
чат нейросеть для учебы nejroset-dlya-referatov-5.ru .
чат нейросеть для учебы чат нейросеть для учебы .
Casino Online, http://www.evergoldcs.com/lucky-manor-casino-online-slots-spin-your-way-to/ – Casino Online provides a unique gaming experience. Participants can experience various options from the ease of their abodes. With thrilling bonuses, Casino Online appeals to a wide variety of users.
Рекомендую Вам побывать на сайте, с огромным количеством статей по интересующей Вас теме. Могу поискать ссылку.
турецкие сериалы, http://brisasol.com/en/homepage-default/attachment/2 завоевывают огромную востребованность в сообществе. Их увлекательные сюжеты, харизматичные персонажи и роскошная cinematography делают эти шоу успешными среди зрителей различных возрастных групп.
football not on GamStop, https://hgenbrug.dk/index.php/2026/03/14/top-non-gamstop-football-betting-sites-find-your/ offers an exciting opportunity for players seeking alternative betting options. Whether you prefer the thrill of live matches or online platforms, there’s something for everyone. Find unique games and betting markets that enhance your experience. Dive into the world of football and enjoy seamless betting away from restrictions!
I siti scommesse non aams, https://farakaranpiping.net/scommesse-senza-documenti-scopri-le-migliori/ offrono un’ampia varietГ di eventi sportivi per scommettere. Le persone possono analizzare tariffe competitive oppure bonus attraenti che aumentano l’impatto. Inoltre, il metodo di gioco ГЁ ottimizzata da interfacce facili da usare.
1xbet giri? 2025 1xbet giri? 2025 .
bahis siteler 1xbet bahis siteler 1xbet .
The hierarchy of pay symbols lists 10-A card ranks, fish, backpacks, axes, lures, and Combi vans of all things. Five-of-a-kind winning combinations pay 5x to 10x the bet when made up of royals, or 20x to 200x when made of premium symbols. There are two wild symbols that substitute any regular paying symbol, but they only appear during the free spins bonus round. Embark on another legendary fishing adventure and experience the excitement and joy of big wins. Big Bass Bonanza is one of Pragmatic Play’s most successful slots. Despite its simple format and classic theme, it has become a perennial favourite over the years, spawning spin-offs such as Big Bass Splash and Big Bass Bonanza Megaways. However, our review focuses specifically on the original slot, which was released on 03 12 2020. Slots are massively popular. You spin the reels and hope to land on a winning combination. There are several tips and tricks to improve how you bet on slot games, weather you’re playing for free or real money. Our top tip is to think about paylines. Take the time to research each game’s paylines before you play to know which one give you the biggest chance to win. At Casino.org we’ve got hundreds of free online slot machines for you to enjoy.
https://eifab.com/how-to-get-m99-casino-exclusive-slots-bonus/
Wisecut will automatically pick a song and tailor the music to fit your video. Additionally, Wisecut will perform audio ducking, automatically lowering the music when someone is speaking and increasing it when there is no speech. What are the best video editing courses online?Browse the video editing courses below—popular starting points on Coursera. Our editor comes with all the features necessary to create a great video — add any text to your project, and personalize it! You can change font, size, boldness, color, add background and more! Advanced editing. While not all editing jobs need advanced tools, certain projects require things like chroma keying (green screen), object tracking, video stabilization and lens correction, multi-camera editing for quickly switching between perspectives, and color adjustment. More video editors are embracing AI with features like text-based editing and background removal. I kept my eye out for and played around with these advanced features as I was testing each video editor.
нейросети для студентов нейросети для студентов .
умная нейросеть для учебы nejroset-dlya-referatov-7.ru .
Я извиняюсь, но, по-моему, Вы не правы. Могу отстоять свою позицию. Пишите мне в PM, пообщаемся.
MagicWin casino, https://idocteuragency.com/discovering-the-best-magic-win-casino-sister-sites-2/ предлагает уникальный опыт в мира азартных игр. В этом месте можно насладиться чудесными игровыми опциями.
Подумать только!
Виртуальный пространство pin-up casino, https://pin-up-casino-nmdw0.cfd/ дарит уникальные опции для любителей азартных игр. Тут каждый отыщет что-то интересное. Графика и активности порадуют даже игроков!
умная нейросеть для учебы nejroset-dlya-referatov-6.ru .
нейросеть реферат нейросеть реферат .
нейросеть пишет реферат нейросеть пишет реферат .
Mostbet online, https://activ8camp.com/onlinecasino270212/understanding-mostbet-on-trustpilot-a-2/ offers diverse betting options, making it easy for users to place bets. With real-time betting and competitive odds, it stands out in other platforms. Enjoy a thrilling experience today!
джеттон казино скачать
где в москве купить дешевые цветы http://www.dostavka-cvetov-moskva495.ru/ .
нейросеть для студентов нейросеть для студентов .
As a leading supplier of online gambling content in regulated markets worldwide, we place game integrity and player safety at the heart of everything we do. Following the huge success of the original game, Pragmatic Play has launched the Gates of Olympus 1000 slot, a powerful sequel with even bigger rewards. This Greek mythology-themed slot plays on a 6×5 grid where prizes are awarded when at least 8 identical symbols land anywhere on the reels. Operating a scatter pays win system means Gates of Olympus Super Scatter creates a winning combination when 8 or more matching symbols land anywhere on the grid. Players may wager 20 c to $ €240 per spin, buy free spins or super free spins, and activate an ante bet, where the default RTP when regular betting comes in at 96.5%. The ante bet puts 50% onto the stake when activated to double the chance of triggering the free spins feature.
https://portalcroft.com/?p=258597
Wazdan is the master of innovation in iGaming. With unique slots like Cash Infinity™ and Hold the Jackpot™, each spin brings the thrill of real gains. Designed for players who seek a rewarding experience, Wazdan offers the ultimate in Online gaining™. Play smart, gain big.. To play demo Gates of Olympus for free right here at Temple of Games, just click the ‘Play for Free’ button at the top of this page. Then, you can enjoy Gates of Olympus for fun, without spending any money. Operating a scatter pays win system means Gates of Olympus Super Scatter creates a winning combination when 8 or more matching symbols land anywhere on the grid. Players may wager 20 c to $ €240 per spin, buy free spins or super free spins, and activate an ante bet, where the default RTP when regular betting comes in at 96.5%. The ante bet puts 50% onto the stake when activated to double the chance of triggering the free spins feature.
1xbet resmi 1xbet-giris-45.com .
дизайн интерьера онлайн дизайнер квартиры
1xbet lite 1xbet lite .
Playing Casino Online Slots, https://asceurovisa.com/step-by-step-guide-to-lt-casino-registration/ is a stimulating experience. Leveraging multiple themes and options, players can partake in an array of choices. Gaining big rewards adds to the excitement.
И все?
фильмы онлайн, http://cua99.ru/shaanxi-normal-university/ предлагают зрителю поразительное наслаждение. На сегодняшний день можно посмотреть множество разных фильмов. Так привлекает многочисленных зрителей.
Это помогает читателям получить полное представление о сложности и многогранности обсуждаемой темы.
сделать реферат сделать реферат .
сайт для рефератов сайт для рефератов .
bingo not on GamStop, https://coursesyouneednow.com/post/146192 offers exciting gaming opportunities for players seeking alternatives to self-exclusion schemes. Many enthusiasts enjoy this platforms that provide a chance to win massive while avoiding restrictions. Engage in exciting experiences with various games available.
По-моему это уже обсуждалось, воспользуйтесь поиском.
В вселенную азартных развлечений выходит pin-up casino, https://pin-up-casino-ck2ny.cfd, событие игрокам замечательные возможности для игры. С колоритной атмосферой и впечатляющими бонусами, каждый игрок найдет что-то привлекательное. Играй и выигрывай в pin-up casino!
Браво, вас посетила отличная мысль
online casino, https://blitz-bet.eu/de/promo offers a captivating experience for players. With countless of games available, such as slots to table games, gamblers have the chance to enjoy limitless entertainment at one’s fingertips.
нейросеть пишет реферат nejroset-dlya-referatov.ru .
раз позыреть можно
MagicWin casino, https://jaybabani.com/material-wp-admin/?p=255633 offers an exciting opportunity for gaming enthusiasts. Players can explore a wide selection of gaming options, including slots. Through great bonuses and promotions, MagicWin casino attracts a diverse crowd. Dive into the thrilling world of virtual gaming today!
1xbet 1xbet .
нейросеть генерации текстов для студентов nejroset-dlya-referatov-1.ru .
Автор предоставляет различные точки зрения и аргументы, что помогает читателю получить полную картину проблемы.
1 x bet 1 x bet .
Обновления по теме: https://remontparketspb.su
Извиняюсь, мне тоже хотелось бы высказать своё мнение.
Welcome to the amazing world of BSB007 Casino, https://rsedistribuidora.com.br/l-x27-impact-de-la-technologie-sur-les-jeux-d-x27/, where gamblers can find exciting gaming at its best. With various options to choose from, everyone can find something to their liking. Join us today and get involved in an unforgettable adventure!
нейросеть пишет реферат нейросеть пишет реферат .
нейросеть для студентов нейросеть для студентов .
Mostbet casino, https://clearskyits.com/index.php/2026/02/27/understanding-trustpilot-a-deep-dive-into-customer-2/ оснащает игрокам необычный опыт азартных мероприятий. С разнообразием развлечений, каждый найдет что-то на свой вкус. Подключайтесь и ощутите атмосферой азартных мероприятий.
1xbet tr 1xbet tr .
https://elektryksrem.pl/blog/ <- Sprawdź blog
Online gambling has evolved, offering players availability to a variety of engaging games. Among them, Casino Online Games, https://aquilasecurityservices.com/experience-the-thrills-of-letou-casino-your/ provide an opportunity to win big from the comfort of home. With cutting-edge technology, participants enjoy captivating experiences.
Пора взяться за ум. Пора придти в себя.
Смотреть картины онлайн стало доступнее благодаря современным технологиям. фильмы онлайн, https://sachaagro.cz/grup-jympa/ позволяют наслаждаться историями в любое время. Любителям боевиков всегда найдется что-то по душе.
1xbet giri? g?ncel 1xbet giri? g?ncel .
кое что есть норм.
В мире азартных игр pin up casino онлайн, pin-up-casino-fxtuo.lol предлагает широкий выбор слотов. Каждый геймер найдет понравившееся для себя. Превосходная графика и замечательные бонусы делают процесс игрового опыта еще более увлекательным.
сделать реферат nejroset-dlya-referatov.ru .
I siti scommesse non aams, https://www.repalpiquiri.com.br/?p=914000 sono un’opzione interessante per gli scommettitori. Offrono promozioni allettanti, tuttavia ГЁ fondamentale analizzare la loro sicurezza. Inoltre ГЁ importante conoscere normative locali per prevenire eventuali imprevisti.
Finding dependable sportsbooks not on GamStop, https://www.formacionquality.es/your-ultimate-guide-to-non-gamstop-sports-betting/ can be difficult. However, numerous options are available that cater to players seeking free betting experiences. These sportsbooks not on GamStop offer engaging opportunities. Be sure to look into their standing and ensure they provide protected payments and customer support.
Компания предлагает щебень гравийный цена для стройки и благоустройства с оперативной доставкой по Москве и области.
Щебень гравийный — важный строительный материал, востребованный в дорожном и цивильном строительстве.
Производство гравийного щебня включает добычу, сортировку и дробление исходного материала.
Щебень из гравия активно задействуют в дорожном строительстве, в составе бетонов и при обустройстве дренажей.
Выбирать щебень нужно по фракции, степени загрязнённости и доле мелкой фракции, влияющей на уплотняемость.
1 x bet 1 x bet .
заказать букет в москве недорого цветов с доставкой dostavka-cvetov-moskva495.ru .
нейросеть генерации текстов для студентов нейросеть генерации текстов для студентов .
ии реферат ии реферат .
Все не так просто
Casino Online, https://rotorbuilds.com/profile/205731 – Virtual gaming has become increasingly popular, offering betters the chance to enjoy their favorite games from home. Joining a Casino Online allows for accessibility and a variety of games. With protected payment methods and thrilling bonuses, it’s evident why so many are flocking to this expanding world of betting.
нейросеть онлайн для учебы nejroset-dlya-referatov-1.ru .
У вас неверные данные
Online gambling enthusiasts often seek alternatives, considering what casinos are not on GamStop, https://jaybabani.com/star-wp-admin/?p=84665. These platforms provide a chance to play without restrictions. Many players appreciate options like online sites that offer multiple choices and generous bonuses. Exploring these non-GamStop platforms can lead to fulfilling experiences while avoiding GamStop’s limitations. Always remember to play responsibly and choose establishments that prioritize protection.
Ищете идеальный купить трековый велосипед в москве, чтобы уверенно побеждать на треке и наслаждаться скоростью?
Трековый велосипед — это специализированный вид двухколесного транспорта, созданный для высокой скорости на велодроме.
1x lite 1xbet-giris-43.com .
Респект!!! Качественные продукты выкладываешь!
Откройте мир азартных игр с лучшей платформой pin up casino онлайн, https://pin-up-casino-jrkpu.cyou/. Множество игр восхитит даже самых требовательных игроков. На платформе имеются казино-игры от популярных разработчиков. Занимайтесь к прекрасному игровому опыту!
To start your journey in online betting, you need to complete the Mostbet register, http://reecesafetym2.stagingapplications.com/blog/the-ultimate-guide-to-mostbet-your-path-to-winning/ process. It’s done easily through their website or app. Just provide your data and adhere to the steps. After this, you’ll be ready to discover a range of exciting betting options.
лучшая нейросеть для учебы nejroset-dlya-referatov.ru .
Many players seek betting platforms that provide exciting experiences. casinos not on GamStop, https://www.casefileschicago.com/stmonicas/exploring-uk-sites-not-on-gamstop-a-guide-to/ offer diverse games and attractive bonuses. They are perfect for those looking for autonomy in their gaming choices.
Извините за то, что вмешиваюсь… У меня похожая ситуация. Готов помочь.
Renting a Car in the UAE, https://batikmaskencana.com/batik-mas-kencana/ offers travelers accessible mobility. With multiple options available, you can explore the breathtaking landscapes. Don’t forget to consider insurance packages for a protected journey.
1xbet g?ncel adres 1xbet g?ncel adres .
bitcoin casino denmark, https://luckydistributions.com/2026/03/05/bitcoin-casino-i-danmark-oplev-fordele-og/ har en unik eventyr for spillere, der vil at mixe sjov med ny teknologi. Gennem innovative lГёsninger kan gamblere nyde et forskelligt udvalg af muligheder.
1xbet g?ncel 1xbet g?ncel .
In the world of virtual gambling, players find excitement and thrill. Casino Online, https://cuneolab.pucv.cl/index.php/2026/03/05/forzabet-casino-sign-in-unlock-your-gaming/ offers various games, such as slots, poker, and blackjack. Using bonuses and promotions, enthusiasts can enhance their experience, making each session more rewarding.
Мне знакома эта ситуация. Приглашаю к обсуждению.
balloon oyunu, https://balloon-oyunu.online, çocuklar için eğlenceli bir aktivitedir. Eğlenceli oyun, takım halinde oynanabilir. Amaç, balonları delmek ve en yüksek puanı elde etmektir. Bu hedefi başarmak için taktik geliştirmek önemlidir.
Согласен, замечательная штука
online casino, http://supergamecasino.co.uk предоставляет захватывающий пейзаж азартных игр. Занимаясь в разнообразных играх, можно выиграть реальные деньги. Защита операций является ключевым параметром для игроков.
In a realm of online gambling, a non GamStop online casino, https://shiawaseglobal.com/exploring-online-casinos-the-uncovered-territories/ offers enthralling opportunities for players. Here, you can enjoy an array games without constraints. It’s ideal for those seeking independence in their gaming experience.
In the world of cyber gaming, Casino Online, https://beautyclinic.pe/explore-the-thrill-of-online-casino-letou/ offers captivating experiences for players. With a vast range of choices, users can savor their favorite pastimes. Promotions enhance the fun, making it more rewarding. Security features ensure a secure environment for everyone involved. Join the action and discover the most innovative platforms available in Casino Online!
Scoprire il settore dei casinГІ ГЁ fascinante. Un eccellente modo per iniziare ГЁ scegliere un casinГІ deposito 5 euro, https://www.medicalmarijuanabarcelona.com/i-migliori-casino-online-con-deposito-di-5-euro-19/. Con un piccolo investimento, puoi sperimentare diversi giochi e avere emozioni uniche. Le offerte per bonus sono anche una significativa opportunitГ per esaltare i tuoi vincite. Scegli con attenzione e divertiti!
И что бы мы делали без вашей замечательной идеи
фильмы онлайн, https://peterburg.one/about/ – Интернет предлагает разнообразный выбор фильмов онлайн, что даёт шанс смотреть любимые ленты в любое точку времени. Пробуйте в атмосферу кино с комфортом.
нейросети для студентов нейросети для студентов .
нейросеть онлайн для учебы nejroset-dlya-referatov-2.ru .
jetton казино в телеграмме отзывы
нейросеть для школьников и студентов nejroset-dlya-referatov-1.ru .
1xbet resmi sitesi 1xbet-giris-39.com .
1xbet ?yelik 1xbet-giris-33.com .
Автор представил четкую и структурированную статью, основанную на фактах и статистике.
Компания предлагает щебень гравийный для стройки и благоустройства с оперативной доставкой по Москве и области.
Его прочностные характеристики и размерная фракция делают его удобным для использования в разных слоях дорожной одежды.
Контроль качества и классификация по фракциям обеспечивают соответствие стандартам и требования заказчиков.
Благодаря доступности и выгодной цене материал часто выбирают для массовых строительных работ.
Соответствующий выбор щебня повышает долговечность конструкций и снижает затраты на эксплуатацию.
1xbet ?yelik 1xbet ?yelik .
И тогда, человек способен
Наслаждайтесь мир игровых автоматов с pin up casino онлайн, pin-up-casino-s48xc.xyz. Здесь вас ждут эксклюзивные бонусы, привлекающие предложения и огромный ассортимент развлечений. Не упустите шанс наслаждаться азарт в удобном формате!
1xbet giri? 2025 1xbet giri? 2025 .
1xbet yeni adresi 1xbet yeni adresi .
Я считаю, что Вы не правы. Я уверен. Пишите мне в PM.
Finding the best non GamStop casino, https://wishbook.onehopeunited.org/top-gambling-sites-not-on-gamstop-play-without/ can be a game-changer for players seeking an unrestrained gaming experience. These platforms offer unique rewards, allowing players to enjoy their favorite games without restrictions. Whether you’re a casual player, the appeal of a non GamStop site is undeniable. Embrace the freedom and explore the thrilling world of online gambling today!
1xbet lite 1xbet-giris-42.com .
Det bedste mobil casino, https://pilisanabria.com/2026/03/05/de-bedste-mobil-casinoer-i-danmark-spil-nr-som/ præsenterer en fantastisk moro for spillere. Man kan lege på farten med flere alternative at udvælge. Oplev de opdaterede slots og bordspil uden at blive hjemme. Tjenesten lover beskyttede betalinger og hurtige udbetalinger, så deltagerne kan koncentrere sig at få præmier. Det ideelle mulighed for sjov på mobilen er bestde mobil casino.
Amidst the landscape of Online Casino, http://www.brouilette.com/archives/213327, players can find a plethora of captivating games. Including slot machines to table games, selections are abundant. Dive into this exhilarating arena and exploit the chance to win big!
Ищете идеальный шоссейные трековые велосипеды, чтобы уверенно побеждать на треке и наслаждаться скоростью?
Экипировка и экипировка спортсмена также играет ключевую роль в результатах.
I’m also commenting to make you know what a wonderful encounter my friend’s daughter gained viewing yuor web blog. She realized some issues, including how it is like to have an incredible teaching style to get many more without hassle fully understand various extremely tough issues. You really surpassed readers’ expected results. Thank you for showing such valuable, trustworthy, edifying and unique thoughts on the topic to Gloria.
1xbet 1xbet .
The Mostbet app, http://citystore.shegokargroup.com/understanding-trustpilot-your-guide-to-online-6/ offers bettors an amazing experience in the world of online betting. With simple navigation and a wide selection of sports and casino games, it’s excellent for everyone. The promotions available are attractive and can enhance your gaming experience. Moreover, the app ensures safety for all transactions, making it a trusted choice. Enjoy betting like never before!
1xbet giri? yapam?yorum 1xbet-giris-33.com .
Это было и со мной.
Discover the world of erotic shows with Free sex cams, http://i.detenzioni.eu/rx/330×186,c_1,g_center/https://smallpetlife.com/are-gerbils-a-good-pet/. Experience unique encounters that cater to your fantasies. Uncover vibrant communities where pleasure knows no bounds.
Se stai cercando un modo per divertirti, il casinГІ deposito 5 euro, http://tkehealth.com/index.php/2026/03/13/casino-online-con-deposito-minimo-gioca-e-vinci-6/ ГЁ un’ottima opzione. Puoi scommettere senza necessitare di investire grandi somme. Scopri l’adrenalina di vincere con pochi euro! I bonus sono spesso disponibili.
Playing at a non GamStop online casino, http://www.easenet.jp/wordpress/discover-the-best-uk-casinos-not-on-gamstop-2-2/ offers players a unique experience. Enjoy the exciting range of entertainment. With better bonuses and reduced restrictions, players can delight in the thrill of gaming without limits.
1xbet giri? yapam?yorum 1xbet-giris-39.com .
Online Casino, https://buzzreleased.com/lady-linda-online-casino-uk-a-comprehensive-guide/ – Online Casino предлагает удивительные возможности для геймеров. Здесь доступно насладиться различными играми, включая игровые автоматы. РЎ привлекательными бонусами, каждый желающий найдет что-то необычное.
Судя по отзывам – надо качать.
В последние годы востребованность дорамы онлайн, https://dalelike.avifes.org/hola-mundo/ значительно возросла. Это тип, который привлекает поклонников. Смотрите свежие истории и необычные персонажи, которые придают вас переживать каждую минуту. Наслаждайтесь увлекательными сюжетами и оригинальной атмосферой, которая дарит неповторимые эмоции. В погоне за лучшими новинками, вы сможете открыть в край дорамы.
1xbet giris 1xbet giris .
Шутки в сторону!
Загляните в мир увлечения с pin up casino онлайн, casino pin up личный кабинет промокод, где вы найдете множество развлечений. Уникальные акции и интересные слоты подарят радость всем любителям онлайн-гемблинга!
1xbet t?rkiye 1xbet t?rkiye .
online casino not on GamStop, https://strendsprint.com/2026/03/09/a-comprehensive-guide-to-non-gamstop-casinos-in/ offers players a unique opportunity to enjoy their favorite games without restrictions. Such casinos provide a thrilling gaming experience, allowing users to find numerous selections for fun and profitable gameplay.
1xbet yeni adresi 1xbet yeni adresi .
1xbet giri? yapam?yorum 1xbet-giris-42.com .
1xbet giris 1xbet giris .
1xbet giri?i 1xbet giri?i .
I dag er der mange udmærkede muligheder for spillere, der ønsker at opleve bedste mobil casino, https://multiconexoes.ind.br/bedste-mobil-casino-spil-online-p-farten/. Med nutidige teknologi kan du spille dine yndlingsspil ukompliceret på farten. Mobilcasinernes brugervenlighed gør dem til et hyppigt valgt valg blandt gamblers. Oplev spændingen ved at spille hvor som helst!
Online Casino UK, https://tripadikberadik.com/v4/wp/index.php/2026/03/05/exploring-online-casino-jackpotter-your-gateway-to/ offers a vast range of activities. Players can delight in table games and utilize various offers available online.
1xbwt giri? 1xbet-giris-33.com .
В этом что-то есть. Понятно, благодарю за информацию.
П„О± ОєО±О»П…П„ОµПЃО± online casino, https://dev-shvsorg.pantheonsite.io/online-169/ ПЂПЃОїПѓП†ОПЃОїП…ОЅ ОјОїОЅО±ОґО№ОєОП‚ ОµОјПЂОµО№ПЃОЇОµП‚ П€П…П‡О±ОіП‰ОіОЇО±П‚. О•ПЂО№О»ООіОїОЅП„О±П‚ П„О± ОєО±О»ПЌП„ОµПЃО± ОґО№О±ОґО№ОєП„П…О±ОєО¬ ОєО±О¶ОЇОЅОї, ОїО№ ОµОЅОґО№О±П†ОµПЃПЊОјОµОЅОїО№ О±ПЂОїО»О±ОјОІО¬ОЅОїП…ОЅ ПЂПЃПЊПѓОІО±ПѓО· ПѓОµ ПЂОїО№ОєО№О»ОЇО± ПЂО±О№П‡ОЅО№ОґО№ПЋОЅ. О— О±ПѓП†О¬О»ОµО№О± ОєО±О№ О· О±ОѕО№ОїПЂО№ПѓП„ОЇО± ОµОЇОЅО±О№ ОєПЃОЇПѓО№ОјО· ОіО№О± ОјО№О± ОІОО»П„О№ПѓП„О· ОµОјПЂОµО№ПЃОЇО±.
И как в таком случае нужно поступать?
Online oyun oyun tutkunları için ivi bet online, https://ivibetonline.casino mükemmel bir yol. Burada çeşitli şans oyunları bulmanız mümkün. Kazançlı oranlar ve kolay işlemlerle heyecan dolu bir deneyim sunuyor.
1xbet turkiye 1xbet-giris-39.com .
1x giri? 1xbet-giris-44.com .
Я просто не могу пройти мимо этой статьи без оставления положительного комментария. Она является настоящим примером качественной журналистики и глубокого исследования. Очень впечатляюще!
Scoprire nuovi giochi ГЁ entusiasmante nei casinГІ. Un casinГІ deposito 5 euro, https://ironcladgroupltd.co.uk/2026/03/13/scopri-i-vantaggi-dei-casino-con-deposito-di-solo-2/ offre l’opportunitГ di iniziare a divertirsi senza rischiare troppo. Gli utenti possono provare diverse slot e tavoli per generare la propria esperienza. La scelta ГЁ vasta!
Discover the excitement of top non GamStop casino, https://archives.dailycal.org/2026/03/14/exploring-non-gamstop-uk-casinos-a-comprehensive-3/, where players can enjoy a vast array of games without restrictions. These platforms offer numerous options, including live dealer options, ensuring unlimited entertainment. Join now and experience the thrill!
If you’re looking for a reliable gaming platform, take a look at Mostbet download, https://institutoaesj.com.br/in-depth-betwinner-review-a-comprehensive-look-at-2/. This app gives an impressive experience for players. With intuitive interface and exciting games, it’s a great choice for gambling enthusiasts. Start your betting journey today with Mostbet download!
По моему мнению Вы ошибаетесь. Могу отстоять свою позицию. Пишите мне в PM, поговорим.
Хотите насладиться захватывающими сюжетами? Тогда дорамы смотреть онлайн, https://yourfronteoffice.com/strengthening-nonprofit-leadership — это отличный выбор! Сериал перенесет вас в мир эмоций и захватывающих событий. Найдите любимый жанр и погрузитесь в тонкости истории!
Online Casino Slots, http://sub.mah-hanau.de/casinoonlineslot200226/step-by-step-guide-to-registering-at-kalokalo/ offer an exciting way to experience gambling from the comfort of home. Players can enjoy various themes and options. With big wins, it’s no wonder they’re so popular!
1xbet giri? 1xbet giri? .
Замечательно
дорамы онлайн, https://www.firstimageus.com/smart-replace-corp/ позволяют возможность следить за любимыми персонажами в любое время. Современные сюжеты поражают зрителей. Не упустите мир дорам онлайн!
1xbet resmi 1xbet-giris-43.com .
udenlandske casinoer, https://gambarigroup.com/spil-betting-uden-rofus-en-dybere-indsigt-i/ præsenterer en spændende aktivitet for spillere, som er på udkig efter nye alternativer. Et stort antal platforme fokuserer et alsidigt udvalg af spilleautomater, der dyrkes af spillere fra hele verden.
1xbet yeni adresi 1xbet yeni adresi .
Amidst the world of Online Casino Slots, https://www.chxpressfitness.com/casinionline5034/experience-the-thrill-of-online-gaming-at-golden/, participants can experience an array of captivating games. Leveraging advanced technology, these slots present entertaining gameplay and bountiful opportunities.
Автор предоставляет подробные объяснения сложных концепций, связанных с темой.
1xbet turkiye 1xbet-giris-39.com .
1xbet g?ncel giri? 1xbet g?ncel giri? .
non GamStop casino sites, https://fittedrims.net/skihiver/discover-the-best-non-gamstop-casinos-for-2/ provide players access to enjoy betting without barriers. These locations commonly feature a vast assortment of games, ensuring an entertaining experience for all.
Это просто бесподобный топик
ОЈО®ОјОµПЃО±, П„О± ОєО±О»П…П„ОµПЃО± online casino, https://mozzarella.gad-dairy.co.il/online-717539097/ ПЂПЃОїПѓП†ОПЃОїП…ОЅ ОµОѕО±О№ПЃОµП„О№ОєОП‚ ОµП…ОєО±О№ПЃОЇОµП‚ ОіО№О± ОґО№О±ПѓОєООґО±ПѓО· ОєО±О№ ОєОПЃОґО·. О‘П…П„ОП‚ П„О± ОєО±О¶ОЇОЅОї ПѓП…ОЅОґП…О¬О¶ОїП…ОЅ ОєОїПЃП…П†О±ОЇО± ПЂО±О№П‡ОЅОЇОґО№О±, ПЂПЃОїПЉПЊОЅП„О± ОєО±О№ ПѓП…ОЅО±ПЃПЂО±ПѓП„О№ОєО¬ ОјПЂПЊОЅОїП…П‚. О— ОµОјПЂОµО№ПЃОЇО± П„О¶ПЊОіОїП… ОµОЇОЅО±О№ О±П†ОїПЂО»О№ПѓП„О№ОєО® ОєО±О№ ОґО№О±ПѓП†О±О»ОЇО¶ОµО№ ПѓП„О№ОіОјОП‚ ОµП…П‡О±ПЃОЇПѓП„О·ПѓО·П‚.
А это эффективно?
pin up casino онлайн, https://pin-up-casino-paemt.click/ считает игрокам большой выбор игровых автоматов и щедрое предложения. Здесь можно играть в популярные автоматы с простым интерфейсом.
Scoprire un interessante mondo di giochi ГЁ semplice nei casinГІ con deposito 1 euro, https://lancist.com/casino-non-aams-per-italiani-guida-completa-e-2. Queste piattaforme propongono l’opportunitГ di divertirsi senza spendere grandi somme. Registrati e inizia a scommettere la fortuna!
top non GamStop casino, https://malhariaipanema.com.br/are-non-gamstop-casinos-safe-a-comprehensive-guide-6/ offers players a unique experience boasting a wide range of options. Players can enjoy high-quality slots, table games, and interactive dealer options. Additionally, offers are generous, making it one great place to bet. Don’t miss out on the captivating world of non GamStop casinos!
I dag er der mange chancer for at spille online. Fra mange sider interesserer casino uden dansk licens, https://hexoservices.24livehost.com/casinoer-uden-dansk-licens-fordele-og-ulemper/, fordi de leverer flere bonusser og underholdning. Tænk over sikkerhed og lovgivning.
Online Casino, https://qzyindia.com/index.php/2026/03/05/exploring-the-irish-luck-platform-your-gateway-to/ предоставляет уникальные шансы для азартных. Надежность и захватывающие акции делают развлечение увлекательной.
1xbet resmi giri? 1xbet-giris-38.com .
Mostbet online, https://ameriprosautobody.com/trustpilot/the-importance-of-trustpilot-for-businesses-a-deep/ offers a interactive platform for gambling. With a varied range of events to choose from, players can savor thrilling probabilities and promotions.
теперь один вопрос:кто меня из под стола достанет!?
Виртуальные игровые заведения, такие как казино онлайн, https://yogaasanas.science/wiki/User:ClaribelVigano6, становятся все более популярными в современном обществе. Все больше людей выбирают отправиться в мир азартных игр именно через интернет. Казино онлайн предоставляет обширный ассортимент игр, от классических автоматов до стратегических развлечений.Основным плюсом такого формата является доступность доступа. Не нужно отправляться в физическое казино, достаточно просто подключиться сайт на своем устройстве. Более того, многие онлайн-казино предлагают высокие бонусы и акции для новых и постоянных игроков.Каждый может найти что-то интересное по своему вкусу – от игровых аппаратов до виртуальных турниров. Тем не менее, важно помнить о грамотном подходе к азартным играм, чтобы препятствовать нежелательных последствий. Важно играть в свое удовольствие и не забывать о бюджете.
1xbet g?ncel giri? 1xbet g?ncel giri? .
Online Casino Games, https://rbs24.by/discover-kalokalo-casino-sportsbook-your-ultimate-13/ deliver a dynamic experience for participants. Utilizing a selection of games, players can experience various styles and themes. Several platforms offer fair play and protected transactions, making it simple to join the fun.
1xbet giri? linki 1xbet giri? linki .
вождь с ноутбуком – просто супер
турецкие сериалы онлайн, http://tyret.ru/board1/1.html захватывают зрителей своим содержанием. Их разнообразие позволяет каждому найти что-то по душе, будь то драма, романтика или комедия. Многие предпочитают смотреть новыми выпусками прямо из дома.
1x bet 1xbet-giris-42.com .
1xbet 1xbet .
Спроси у своего калькулятора
lucky jet demo, lucky jet demo, online oyun deneyimi sunuyor. Kullanıcılar bu oyunu görerek şanslarını. Eğlence ve adrenalin dolu anlar sunar. Dinamik oyun akışı ile boş zamanlarını değerlendirmek mümkün.
Абсолютно не согласен с предыдущей фразой
Играть в онлайн-казино — это замечательный способ поиграть. В pin up casino онлайн, pin-up-casino-ncp06.icu можно найти множество развлечений на любой вкус. Экспериментируйте новые игровые аппараты и изучайте бонусы и акции для увеличения выигрышей.
Danske spillere kan at nyde casinoer uden dansk licens, https://www.luminaryexperts.com/casino-uden-mitid-2026-en-ny-ra-for-dansk-spil/. De casinoer giver mange bonusser og spilmuligheder. Man skal være opmærksom på betingelser før man investerer i casinoer uden dansk licens.
1xbet tr 1xbet tr .
xbet xbet .
Casino Online, https://hello.waitwhatweb.com/discover-the-excitement-of-gxmble-online-casino/ открывает уникальные возможности для фанатов. Здесь возможно состязаться в различные игры, получая волнение. Оцените успех и наслаждайтесь уникальным приключением в Casino Online!
Извините, ничем не могу помочь. Но уверен, что Вы найдёте правильное решение. Не отчаивайтесь.
I dag er der mange virtuale kasinoer uden dansk licens, som tilbyder underholdende spil. Spillere kan tage del i unikke bonusser og promoveringer, men det er vigtigt at sikre sig opmærksom på de risici, der kan være forbundet med at spille på casinoer uden dansk licens, https://lasantanera.com/online/2026/03/udenlandske-casinoer-sdan-vlger-du-det-bedste-for/.
1xbet spor bahislerinin adresi 1xbet-giris-37.com .
Discover the excitement of gaming at the finest online casinos. Many players seek options beyond their borders, leading to a growing interest in top non UK casino sites, https://identazone.us/non-uk-casinos-accepting-uk-players-a/. These venues offer a wide range of games, alluring bonuses, and secure payment methods. Joining these casinos can offer a unique experience, ensuring fun right at your fingertips. Don’t miss out on the prospect to win big!
Scoprire un nuovo mondo di gioco ГЁ facile con i casinГІ con deposito 1 euro, http://www.museodelbrunello.it/i-migliori-casino-con-skrill-sicurezza-e-facilita/. Hai la possibilitГ di sperimentare a giochi diversi senza spendere una cifra esorbitante. L’ampia scelta di offerte ti favorisce di sperimentare molte slot e giochi da tavolo, scoprendo sempre qualcosa da seguire.
1xbet spor bahislerinin adresi 1xbet spor bahislerinin adresi .
1xbet mobi 1xbet mobi .
В нашем магазин секс шоп вы найдёте всё необходимое для ярких и безопасных впечатлений.
Персонал компетентен и готов дать советы по выбору товара в зависимости от потребностей.
Покупка сертифицированной продукции снижает вероятность неприятностей и продлевает срок эксплуатации.
Интернет-магазины интимных товаров дают возможность выбрать и заказать анонимно и удобно.
Уход и чистка продукции помогают сохранить её в хорошем состоянии и обеспечить безопасность использования.
1 x bet 1 x bet .
Within the realm of virtual gambling, non GamStop sites, https://lp.multiplaprotecao.com/discovering-uk-non-gamstop-casinos-a-comprehensive/ offer players an alternative for experiencing thrilling games without restrictions. These platforms provide a range of gaming options, ensuring there’s something for every player.
1xbet spor bahislerinin adresi 1xbet-giris-42.com .
натяжные потолки купить предлагает широкий выбор качественных решений и профессиональный монтаж в Сочи.
В Сочи доступен широкий ассортимент материалов для натяжных потолков, включая пленочные ПВХ варианты и текстильные полотна.
Выбор глянца помогает сделать помещение светлее и визуально более просторным.
Установку лучше доверить профессионалам, которые предоставляют гарантию на работу и материалы.
Не применяйте жёсткие щётки или химические растворители, чтобы не нарушить целостность полотна.
Вы не правы. Я уверен. Предлагаю это обсудить.
pin up casino онлайн, https://pin-up-casino-iy3k5.icu/ предлагает игрокам уникальный опыт. Виртуальный мир азартных игр волнует разнообразием развлечений и большими бонусами. Доступность регистрации делает любой из игр доступной для новичков.
Mostbet casino, https://www.griecocaffe.com/2026/02/26/exploring-betwinner-reviews-on-trustpilot-a-3/ offers numerous games to choose from. Featuring exciting bonuses, it entices many gamers. Get involved with thrilling tournaments today!
Могу предложить Вам посетить сайт, на котором есть много информации по этому вопросу.
онлайн казино, https://365.expresso.blog/question/%d0%b0%d0%b7%d0%b0%d1%80%d1%82%d0%bd%d1%8b%d0%b5-%d0%b8%d0%b3%d1%80%d1%8b-%d0%b2-%d1%81%d0%b5%d1%82%d0%b8-%d1%8d%d1%82%d0%be-%d0%b2%d0%b5%d0%bb%d0%b8%d0%ba%d0%be%d0%b5-%d0%bc%d0%b5%d1%81/ создают условия игрокам изучить мир азартных игр не выходя из дома. Широкий выбор игр и бонусов привлекает множество людей.
Online Casino, https://binasesawang.com/?p=9701 находится отличным вариантом досуга для фанатов азартных увлечений. Каждый может отыскать что-нибудь по желанию.
Я считаю, что Вы не правы. Я уверен. Могу отстоять свою позицию. Пишите мне в PM, обсудим.
фильмы rezka, http://christianschmeer.com/n3/ – это отличная возможность насладиться качественным кино. Каждый найдут что-нибудь на свой вкус. Многообразие жанров порадует даже самых требовательных зрителей. Обязательно посмотрите лучшие ленты.
udenlandsk casino, https://swiftimpexindia.in/bedste-casinoer-uden-rofus-2026-357272862/ tilbyder mange oplevelse for bruger. Interaktive platforme giver mulighed for at besøge varierede spil. Tryghed er central, når du vælger dit underholdningssted.
1xbet giri? adresi 1xbet giri? adresi .
Праздничную атмосферу любому событию придадут воздушные шары москва.
Надувая шары, следует избегать опасных предметов и открытого огня.
Online Casino, https://presale-vancouver.ca/dogsfortune-casino-sportsbook-your-gateway-to/ represents a exciting venue where participants can enjoy thrilling games through various games. Gaining significant rewards elevates the complete experience.
1xbwt giri? 1xbet-giris-37.com .
1xbet g?ncel 1xbet g?ncel .
1xbet com giri? 1xbet com giri? .
1xbet t?rkiye giri? 1xbet-giris-32.com .
In the world of online betting, selections for golf enthusiasts is developing. Many bettors seek out golf bookies not on GamStop, http://repuestossudamerica.com/discovering-golf-bookies-not-on-gamstop-959701628/, presenting unique opportunities to wager. These sportsbooks often have favorable odds and incentives that make them appealing. Whether you’re a seasoned pro or a newcomer, investigating these options can enhance your betting experience.
1 xbet giri? 1xbet-giris-42.com .
1xbet guncel 1xbet guncel .
Жаль, что сейчас не могу высказаться – опаздываю на встречу. Но освобожусь – обязательно напишу что я думаю.
сайт pin up casino, https://pin-up-casino-0zu0x.lol предлагает богатый выбор азартных игр. Здесь удастся играть в азартными играми и получать крупные призы.
качество хорошее и перевод хороший…
casinoer uden dansk licens, https://lightyellow-mongoose-162261.hostingersite.com/casinoer-uden-dansk-licens-app-oplev-verdenen-af/ præsenterer fascinerende chancer for spillere. Selvom de ofte har flere belønninger, skal man være vigtigt at forstå, at væddemål uden dansk licens kan have risici.
этапы капитального ремонта квартиры remont-zdaniya-1.ru .
Замечательный ответ 🙂
sun of egypt 3, https://sunofegypt3-demo.com/ – MД±sД±r’Д±n gГјneЕџi 3, benzersiz gГјzellikleriyle dikkat Г§ekiyor. Her turist bu bГјyГјleyici deneyimi yaЕџamak iГ§in avantajlД±. Hayal edin bu harika atmosfere. MД±sД±r’Д±n gГјneЕџi 3 ile deneyiminize renk katД±n!
1x bet giri? 1x bet giri? .
udenlandske casinoer, https://dogalroots.com/bedste-betting-sider-uden-rofus-301436566/ tilbyder et diverse sortiment af underholdning. Gamblere har mulighed for for at kunne oplevelse denne fascinerende atmosfære.
1xbet t?rkiye 1xbet t?rkiye .
At the realm of wagering, Online Casino UK, http://wuma.ru/discover-the-excitement-of-casino-spinsala-3.html excels. Participants can explore a range of options, from video slots to card games. Cutting-edge features and enchanting bonuses make the experience even more immersive.
Щебень гравийный — отличный выбор для дорожных работ и благоустройства, подробнее о вариантах и доставке узнавайте на щебень гравийный купить в москве.
Вторичный щебень, полученный из отходов строительства, нередко применяется вместо первичного материала.
1xbet mobi 1xbet-giris-37.com .
Mostbet online, http://solinstant.ca/betwinner-guidebook-reviews-what-you-need-to-know-4/ offers numerous of betting options, such as sports, casino games, and live dealer experiences. With modern technology, players enjoy seamless navigation and reliable transactions. Join now!
Вы ошибаетесь. Предлагаю это обсудить. Пишите мне в PM.
Discover the thrilling land of buccaneer adventures with PIROTS Slots collection, https://www.istitutoart.it/offerta-formativa/multichannel/. Each spin takes you on an exhilarating journey filled with treasures and surprises. Get ready for limitless fun!
карго китай москва — надёжный партнёр для быстрой и безопасной доставки грузов из Китая в Россию.
Логистические операторы часто сопровождают процесс оформления документов и взаимодействие с таможней.
Такие маршруты особенно удобны для срочных отправок средних объемов.
Решая отправлять груз самолетом, важно учесть тарифные ставки, допустимый вес и специфику товара.
Качественная упаковка предотвращает повреждения, а правильная маркировка облегчает прохождение контроля.
Within the realm of Casino Online, https://aziasteel.uz/2026/02/19/experience-the-thrill-of-jetsetspins-online-casino-12/, players can discover a multitude of exciting games. Featuring classic slots to live dealer experiences, the options are endless. Embrace the thrill and experience the ultimate gaming adventure today!
1xbet resmi giri? 1xbet resmi giri? .
Найдите капперы в телеграмме и выберите надежных экспертов для стабильных прогнозов.
Реалистичные ожидания и корректировка прогнозов демонстрируют зрелый подход.
лучшие бесплатные капперы помогает выбрать действительно надежных специалистов для ставок.
Обязательной мерой является проверка репутации эксперта до оформления подписки.
Если результаты скрываются или срок их публикации подозрителен, это тревожный знак.
Капперы, которые делятся аналитикой и объясняют логику ставок, ценнее тех, кто даёт только готовые числа.
Чрезмерно низкая стоимость иногда свидетельствует о некачественной услуге или обмане.
В нашем магазин секс шоп вы найдёте всё необходимое для ярких и безопасных впечатлений.
Покупка в таком магазине часто сопровождается консультацией специалиста, который поможет выбрать подходящую модель.
Сертифицированные изделия минимизируют риски аллергий и повреждений и обеспечивают долгий срок службы.
Онлайн секс-шопы предлагают удобство выбора и доставки, сохраняя конфиденциальность покупателя.
Используйте рекомендованные средства для очистки и храните изделия в сухом прохладном месте.
Ищете надежный цена на самсунг, у нас вы найдете широкий выбор моделей и выгодные цены.
Такой подход уменьшает вероятность дефектов и продлевает рабочий ресурс гаджетов.
Владелец телефона может использовать разные объективы для разнообразных ситуаций.
Производительность смартфонов отвечает требованиям игр и многозадачных задач.
Выбирая телефон Samsung, потребитель получает баланс инноваций, обслуживания и широкой экосистемы.
Ищете надежные прогнозы на спорт? Посетите рейтинг капперов в телеграмме — где собраны проверенные капперы и отзывы о них.
Стоит интересоваться аналитическими инструментами и данными, на которых основаны прогнозы.
Я извиняюсь, но, по-моему, Вы допускаете ошибку. Могу отстоять свою позицию. Пишите мне в PM, обсудим.
фильмы онлайн бесплатно, https://www.access-ticket.com/ticket/%E7%B5%8C%E8%B2%BB%E5%89%8A%E6%B8%9B-%E3%82%A2%E3%82%A4%E3%83%87%E3%82%A2/ – Смотреть киноленты онлайн бесплатно — это удовольствие, доступное каждому. В интернете можно найти множество на любой вкус. Просто выберите жанр, и наслаждайтесь!
new casinos not on GamStop, https://shiawaseglobal.com/exploring-non-gamstop-uk-casinos-a-guide-to-your-2/ offer players an exciting alternative to traditional gambling sites. Such platforms provide unique entertainment and lucrative bonuses. Players can enjoy liberty without the restrictions of GamStop.
1xbet t?rkiye giri? 1xbet t?rkiye giri? .
установить натяжные потолки предлагает широкий выбор качественных решений и профессиональный монтаж в Сочи.
Процесс установки не занимает много времени, а эстетический и эксплуатационный эффект сохраняется на годы.
Глянцевые полотна отражают свет и создают ощущение большей высоты и простора.
Качественная подготовка стен и коммуникаций ускоряет процесс установки.
Для поддержания внешнего вида достаточно периодической протирки мягкой салфеткой и тёплой водой.
1xbet yeni giri? adresi 1xbet-giris-32.com .
1xbet ?yelik 1xbet ?yelik .
По-моему это уже обсуждалось, воспользуйтесь поиском.
сайт pin up casino, https://pin-up-casino-jid6y.click предлагает игрокам уникальный опыт азартных игр. Здесь можно получить разнообразными развлекательными и акциями. Открытие профиля проста и легка.
Scoprire un eccitante casinГІ con deposito 1 euro, http://trustwortha.webtoseo.com/2026/03/15/casino-senza-aams-guida-completa-ai-giocatori/ ГЁ un’occasione ideale per iniziare a entrare nel mondo del gioco senza spendere grandi fondi. Molti giocatori apprezzano questa scelta per esplorare diversi titoli.
Exploring different non GamStop betting sites, https://actdanismanlik.com/exploring-non-gamstop-bookies-a-guide-to-thriving/ is essential for punters seeking adventure beyond traditional platforms. These sites offer wide-ranging options and flexibility to enjoy betting without restrictions.
1xbet giris 1xbet giris .
1xbwt giri? 1xbwt giri? .
1xbet giri?i 1xbet giri?i .
Det er vigtigt at være opmærksom på fordelene ved at spille i et casino uden dansk licens, https://aksharaconsultants.com/online-casinoer-med-klarna-sikker-og-hurtig-2/. Casino uden dansk licens er ofte tiltrækkende goder, men tager færre regler.
Охотно принимаю. Тема интересна, приму участие в обсуждении.
Findes der et sted, hvor du kan spille uden begrænsninger? Det bedste casino uden rofus, https://etiqwise.com/bedste-casino-uden-nemid-dine-muligheder-for/ tilbyder fantastiske spilmuligheder og en overlegen oplevelse. Hvorfor vælge en casino uden rofus? Her kan du få glæde af en atmosfære og fascinerende bonusser. Dette casino skaber en perfekt chance for at opnå store præmier. Tag chancen i dag og forklar dig selv med exceptions spil.
1xbet yeni adresi 1xbet-giris-37.com .
Discovering Online Casino Slots, https://crackboost.com/explore-the-exciting-world-of-dogsfortune-casino-10/ is an exhilarating experience. With various themes, players can enjoy stunning graphics and immersive gameplay. Hitting the jackpot adds to the excitement, making every spin a chance at fortune.
стоимость капитального ремонта здания remont-zdaniya-1.ru .
1xbet com giri? 1xbet com giri? .
готовые букеты http://zakazat-cveti-moskva.ru/ .
1x giri? 1xbet-giris-35.com .
Wagering on Casino Online Slots, http://tiparium.ro/the-exciting-experience-of-casino-jammy-jack/ provides an exciting experience. With a variety of themes, players can enjoy distinct gameplay. Rewards can enhance your chances of winning big!
Неплохой вопрос
сайт pin up casino, pin up casino играть предлагает богатый ассортимент азартных игр. Здесь вы найдете казино-игры, настольные игры и живое казино. предложения на сайте щедрые, что позволяет игрокам увеличить свои шансы на выигрыш. Присоединяйтесь к азартному миру на сайте pin up casino!
Mostbet casino, https://www.i2s.tn/?p=34299 предлагает игрокам широкий выбор азартных игр и высококачественный сервис. Посетители могут наслаждаться широким ассортиментом слотов, ставок на спорт. Акции сделают игру еще интереснее!
Вы определенно правы
In the Chicken Road Game, http://www.mimmosica.com/175-i-personaggi-del-roma-lintervista-a-mario-maglione/, players navigate a vibrant world filled with challenges. Players must dodge obstacles while collecting rewards. Timing plays a key role in this exciting adventure.
Все не так просто, как кажется
Смотреть мультфильмы онлайн бесплатно стало настоящим удовольствием. В интернете можно найти множество платформ, предлагающих фри видеоматериалы. Никогда не было так легко наслаждаться шедеврами. фильмы онлайн бесплатно, https://kinonok.ru/archives/553 порадуют каждого, независимо от предпочтений.
1xbet turkiye 1xbet-giris-32.com .
1xbet yeni giri? 1xbet yeni giri? .
casinoer uden dansk licens, https://riosessions.com/web/udenlandske-casinoer-i-2026-en-overblik-over/53191/ tilbyder et udvalg af spil, der kan interessere spillere. Udenfor dansk regulering tilbyder de generelt bedre bonusser og gratis spins. Spillere bør dog være forberedte på med sikkerheden.
1xbet spor bahislerinin adresi 1xbet spor bahislerinin adresi .
Scoprire il mondo dei casino online ГЁ affascinante. I casinГІ con deposito 1 euro, https://kobra.lindemediamusik.se/2026/03/15/i-casino-online-stranieri-non-aams-la-guida/ offrono l’opportunitГ di iniziare a giocare senza spendere troppo. Con questa minima somma, si ha la possibilitГ di provare diversi giochi e passare il tempo senza rischiare somme elevate. Tieni presente di trovare le promozioni offerte per potenziare la tua esperienza di gioco.
If you’re exploring alternative options, non GamStop betting sites, https://blogs.kritatechnosolutions.com/exploring-non-gamstop-bookmakers-a-comprehensive/ offer enticing opportunities for bettors. These platforms provide flexibility to enjoy betting without limits imposed by GamStop.
Online Casino, https://deckdecor.in/step-by-step-guide-to-verywell-casino-login/ provides a variety of exciting games for players. From slots to table games, there’s something for everyone. Promotions enhance the experience, making it greatly enjoyable.
Извините, что я вмешиваюсь, но, по-моему, эта тема уже не актуальна.
pin up online casino, https://pin-up-online.casino, oyunculara eşsiz deneyimler sunuyor. Geniş oyun yelpazesi ile her zevke hitap eder. Pratik para çekme işlemleri, kullanıcılar için büyük nağme sağlıyor. Cep platformları sayesinde her yerde oyun keyfi!
1x bet 1xbet-giris-28.com .
In the world of online gaming, players often seek different platforms. sites not on GamStop, https://wraithpix.com/list-of-casinos-not-on-gamstop-your-ultimate-guide/ offer the option to enjoy betting without restrictions. Many users prefer these sites for their extensive game selections and attractive bonuses, making the gaming experience more engaging.
капитальный ремонт здания remont-zdaniya-1.ru .
Полностью разделяю Ваше мнение. В этом что-то есть и мне кажется это отличная идея. Полностью с Вами соглашусь.
Клининг, https://bat-net.ru/2026/03/11/iskusstvo-uborki-kak-prevratit-uborku-v/ означает профессиональная уборка помещений. Сотрудники реализуют собственные методы и технологии для достижения оптимальной чистоты.
Браво, какое отличное сообщение
сайт pin up casino, pin-up-casino-hsitd.sbs предлагает оригинальный опыт азартных игр. Здесь предоставляются множество развлечений на любой вкус. Углубитесь в мир интересных слотов и получайте замечательные призы!
1xbet giri?i 1xbet giri?i .
xbet giri? xbet giri? .
1x bet giri? 1x bet giri? .
udenlandsk casino, https://internationalcollege.in/udenlandske-casinoer-uden-nemid-en-guide-til-5/ tilbyder unikke muligheder for lotteri. Spillere kan opfatte et bredt udbud af spil. Desuden er tilbud ofte mere overbærende end i hjemlandet.
Вопрос интересен, я тоже приму участие в обсуждении. Я знаю, что вместе мы сможем прийти к правильному ответу.
онлайн казино, http://woojooind.com/bbs/board.php?bo_table=free&wr_id=4911605 предлагают уникальные варианты для геймеров. Здесь доступно развлекаться в разнообразные рулетку и получать реальные призы.
Casino Online Games, https://bastanighifi.ir/understanding-the-core-values-of-jb-a-gateway-to/ provide an exciting way to enjoy gambling from the comfort of your home. With a choice of games, players can choose their favorites any time.
To get started with Mostbet register, https://bonabery.com/unlocking-financial-opportunities-with-dragon-353/, hastily fill out the application form. You’ll need to provide basic information like your identity and mail. After that, confirm your account to utilize various features. Don’t miss out on distinct bonuses available for new users!
In the world of virtual gaming, Casino Online, https://techners.net/comprehensive-overview-of-betgem-casino-cashback/ offers thrilling experiences for players. With a choice of games like slots, poker, and roulette, users can enjoy accessibility from home. Additionally, bonuses enhance the gameplay, making it far more appealing. Join the entertainment today and explore the unlimited choices.
Браво, отличная фраза и своевременно
Хотите провести вечер за интересным сюжетом? Тогда дорамы смотреть онлайн, https://megam.com.pl/2023/08/materials-for-the-carbohydrate-economy-2/ – это отличный способ окунуться в увлекательные истории! Просто найдете нужный жанр, будь то романтика. Не забывайте ознакомливаться с новинками и наслаждаться ярким контентом!
Scoprire un universo di divertimenti ГЁ immediato con i casinГІ senza registrazione, https://www.hossur.com/i-casino-non-adm-opportunita-e-rischi/. Non serve gestire un account; puoi cominciare a giocare subito. Le alternative di gioco sono ampie.
For players seeking excitement, the best non UK casinos, https://floorthreedesigns.com/exploring-non-ukgc-casino-sites-a-comprehensive-12/ offer thrilling gaming experiences. These venues provide varied opportunities, high-quality games, and excellent bonuses. Explore amazing options worldwide, ensuring a memorable time.
jetton casino на деньги
Вдохновитесь Алтаем! У нас https://altai.travel/ все виды отдыха и маршрутов по Горному Алтаю в одном месте. Мы – официальный туристический портал республики Алтай. Посетите сайт ознакомьтесь с маршрутами и турами, идеями для новых впечатлений. Узнайте все о туроператорах, еде, местах для проживания на любой бюджет. Подробнее на сайте.
Думаю, имеется ввиду и то, и то
сайт pin up casino, https://pin-up-casino-p9wli.sbs предлагает игрокам незабываемые игры и щедрые бонусы. Вы сможете восторгаться разнообразием слотов и оперативными выводами средств. Каждый день на сайте организуются турниры с щедрыми призами.
как заказать букет цветов с доставкой https://zakazat-cveti-moskva.ru/ .
1xbet giri? 2025 1xbet giri? 2025 .
По моему мнению Вы ошибаетесь. Давайте обсудим.
888starz букмекер, http://62.101.86.34/redir.asp?link=ajtdesign.ca%2F888starz-oyin-va-onlayn-tikish-xizmatlari-foydalanuvchilar-uchun-qulaylik-xavfsizlik-va-bonuslar-taqdim-etadi%2F предлагает широкий выбор ставок на спортивные события. Любой матч имеет свои уникальные коэффициенты, что привлекает игроков. Игровые ставки доступны в режиме реального времени, что облегчает процесс игры. Надежность и компетентность команды 888starz букмекер основаны на доверие пользователей. Любой любитель ставок найдет лучшие условия для своих успехов.
Die Support-Optionen von Bahigo Schweiz ermoglichen eine problemlose Kommunikation mit kompetenten Mitarbeitern.
btg casinos schweiz btg casinos schweiz.
1xbet giri? 2025 1xbet giri? 2025 .
udenlandske casinoer, https://alstockmantra.com/udenlandske-klarna-casinoer-oplev-nydelsen-ved/ tilbyder mange spil for spillere. Fra roulette til slots, der noget for alle. Udenlandske casinoer gГёr oplevelsen med tilbud.
I absolutely love your blog and find a lot of your post’s to be just what I’m looking for. Do you offer guest writers to write content for you personally? I wouldn’t mind producing a post or elaborating on a few of the subjects you write concerning here. Again, awesome website!
The realm of Online Casino, https://www.mascom.com.tr/experience-thrilling-wins-at-golden-lion-casino/ offers fun at your fingertips. Players can partake in various games, from slots to poker. With modern technology, the experience is captivating.
Finding|Locating|Identifying|Discovering non GamStop websites, http://icloud.publiduplo.com/archives/1187737 can provide players with diverse options for online gaming. These platforms often offer attractive bonuses|appealing rewards|lucrative promotions|tempting incentives that aren’t available on restricted sites. Players can enjoy|experience|take advantage of|benefit from a wider selection of games and betting opportunities. It’s essential to ensure|confirm|verify|check that these websites are safe and reliable, enhancing your overall gaming experience.
1xbwt giri? 1xbet-55.com .
xbet xbet .
Я думаю, что Вы не правы. Могу отстоять свою позицию.
В мире азартных игр, лучшие онлайн казино предоставляют удивительные возможности для азартных приключений. Лучшие онлайн казино, https://t.me/vanechekvan предлагают множество игровые автоматы и приманчивые бонусы. Практически каждый игроки найдут что-то именно для себя.
Я считаю, что Вы ошибаетесь. Предлагаю это обсудить.
русские сериалы онлайн, https://elibell.ru/%d0%bf%d1%80%d0%b8%d0%b2%d0%b5%d1%82-%d0%bc%d0%b8%d1%80/ максимально раскрывают удивительный мир отечественного синематографа. Заставая за жизнями героев, можно увидеть разнообразные аспекты человеческих чувств. Не пропустите лучшие русские сериалы онлайн!
Among the realm of gambling, Casino Online, https://mantenimientosogas.com/ice-casino-registration-process-a-step-by-step/ has become an popular choice for fans. Featuring exciting games, quick payouts, and comfort, users enjoy spinning their beloved slots and table games. The alluring platform lures countless seeking excitement.
bahis sitesi 1xbet bahis sitesi 1xbet .
I giocatori possono godere di un’esperienza unica nei casinГІ senza registrazione, https://pstamangforyouth.com/casino-non-adm-scopri-i-rischi-e-le-opportunita/, fornendo la possibilitГ di divertirsi immediatamente. Questi contesti non richiedono procedure complesse, permettendo la partecipazione a giochi entusiasmanti.
Apple Pay casino not on GamStop, https://cbi.baywoodgrp.com/exploring-apple-pay-betting-sites-what-you-need-to-5/ offer players a unique way to enjoy online gambling. These venues provide protected transactions and a convenient experience. Featuring Apple Pay, players can effortlessly deposit funds. Choose between various games and delight in the thrill of betting without restrictions. For those seeking freedom, Apple Pay casino not on GamStop presents an exciting option.
1xbet yeni giri? adresi 1xbet-giris-32.com .
Mostbet app, https://dentaltraders.ir/unlocking-financial-freedom-with-dragon-money-bot-286/ предлагает игрокам уникальный шанс ставок. С применением легкому интерфейсу, любой смогут изучить интересные пари и зарабатывать выигрыши на разных рынках.
Авторитетное сообщение 🙂
Если вы хотите насладиться с миром захватывающих историй, то для вас дорамы смотреть онлайн, http://kadet.ru/gbs/index.php — отличный выбор. Каждая часть завлекает зрителя в неповторимый мир. Они забирают необычными сюжетами и трогательными персонажами. Стоит попробовать возможность исследовать для себя что-то интересное.
Coooooool
сайт pin up casino, пин-ап казино предлагает обширный выбор игр. Здесь доступно попробовать удачу, участвуя в интересных турнирах и выгодных акциях. Вдобавок есть комфортные варианты вывода выигрышей.
1 xbet giri? 1xbet-giris-27.com .
Открой для себя лучшие приложения и новинки в каталог приложений для android, где удобно искать, скачивать и обновлять всё необходимое.
Рекомендации персонализируются под интересы пользователя.
Можно включить автоматическое обновление приложений для удобства.
Пользователи получают удобство поиска и множество бесплатных и платных предложений.
Выбирая магазин, обращайте внимание на отзывы, историю и требования к доступам приложения.
1 xbet giri? 1xbet-giris-34.com .
1xbet turkey 1xbet-giris-28.com .
Ищете, где купить летние покрышки — заходите к нам, лучшие цены и быстрая доставка по Санкт-Петербургу.
В Петербурге доступен широкий ассортимент магазинов и сервисных центров с летними покрышками.
Занятия в изучение английского языка в игровой форме помогут вашему ребёнку легко и с удовольствием освоить первые английские слова и фразы.
Задача педагога — поддерживать мотивацию и избегать давления.
Игры и песни — ключевой инструмент в обучении малышей английскому языку. Короткие активные занятия и смена формата удерживают внимание ребенка.
Визуальные материалы и предметы из окружения делают обучение практичным и понятным. Следует показывать предмет и многократно произносить его название для закрепления.
Регулярность занятий и позитивная обратная связь определяют успех в изучении языка. Хвалите ребенка за усилия, отмечайте маленькие достижения и будьте терпеливы.
Закажите ремувки с индивидуальным дизайном и быстрым изготовлением для продвижения вашего бренда.
Они подходят для одежды персонала, корпоративных подарков и брендированных коллекций.
echtgeld online roulette, http://www.grimalc.com/die-besten-echtgeld-roulette-casinos-setzen-und-2/ ermöglicht Nutzern die Gelegenheit, in jeder Ort her zu spielen. Jene Spiele zeigen ein fesselndes Erlebnis. Mit moderne Technologien ist es möglich die Spieler schnell auf ihren Lieblingsspiele zugänglich machen.
Красивый и надежный установка забора цена подчеркнет индивидуальность вашего загородного дома и обеспечит безопасность участка.
Помимо разграничения территории, забор влияет на восприятие дома со стороны прохожих и соседей.
Ищете, где zeekr официальный дилер, — заходите к официальному дилеру в Москве и выбирайте подходящую комплектацию.
Zeekr становится всё более заметным брендом на рынке электромобилей и привлекает внимание покупателей своим дизайном и характеристиками.
Покупка Zeekr включает в себя выбор комплектации, проверку технических характеристик и тест-драйв, чтобы понять поведение машины на дороге.
Стоимость Zeekr формируется исходя из выбранной комплектации, пакетов опций и возможных региональных скидок или льгот.
До оформления покупки Zeekr стоит изучить реальные отзывы пользователей и результаты независимых испытаний автомобиля.
Надежная и эстетичная купить плитку под кирпич для фасада подчеркнет индивидуальность вашего дома.
Её используют при ремонте старых зданий и при возведении современных домов.
Ищете идеальный трековый велосипед цена для тренировок на велотреке и городских выездов — у нас есть модели на любой вкус и бюджет.
Поскольку тормозов нет, райдеры применяют контролируемое замедление педалями и тактические приёмы в пелотоне для регулирования скорости.
1xbet t?rkiye giri? 1xbet t?rkiye giri? .
Online Casino UK, https://masumahmedchowdhury.com/2026/03/03/betgem-casino-login-easy-access-to-your-favorite/ offers a thrilling experience for players. With a wide variety of games, gamblers can enjoy slots, table games, and live dealer options. Join the action today!
По моему мнению Вы ошибаетесь. Давайте обсудим. Пишите мне в PM.
экзотические фрукты с доставкой, http://ordentbk.ru/component/k2/item/5 становятся все более популярными в последние месяцы. Многие люди ищущие новые вкусы стремятся получить уникальные плоды прямо на дом. Это просто и расширяет выбор. Заказывая такие фрукты, вы освежаете свой рацион, а также поддерживаете достойных производителей.
1 xbet giri? 1 xbet giri? .
xbet giri? xbet giri? .
Прошу прощения, это мне не совсем подходит. Может, есть ещё варианты?
Погрузитесь в мир азартных игр с pin up casino играть, pin up wins casino! Здесь ждет масса увлекательных развлечений. Каждая желающий найдет что-либо для себя. Не упустите шанс на выигрыш!
1 x bet giri? 1 x bet giri? .
1xbet g?ncel giri? 1xbet g?ncel giri? .
1xbet lite 1xbet-giris-34.com .
1x bet 1x bet .
birxbet 1xbet-giris-28.com .
In recent years, the popularity for non GamStop sites UK, http://instalex2.type.pl/discover-new-uk-casinos-not-on-gamstop-your/ has risen significantly. These platforms offer players an opportunity to enjoy wagering without restrictions. With numerous options, users can choose their favorite games and explore exciting features. Non GamStop sites UK cater to those seeking flexibility in their gaming experiences, ensuring a individual environment.
Прошу прощения, этот вариант мне не подходит.
The development of the crypto wallet platform, https://de.statistiken.org/2021/03/22/marktanteile-digitalkamera/ has changed the way individuals manage their cryptocurrency assets. With superior security and accessibility, this platform offers unmatched adaptability for trading in various cryptocurrencies.
Nel mondo dei giochi, i casinГІ senza registrazione stanno guadagnando popolaritГ . Offrono un’opzione di divertirsi immediatamente.I casinГІ senza registrazione, https://binkwonnink.nl/2026/03/14/i-migliori-casino-online-esteri-un-viaggio-nel/ appaiono ideali per coloro che desiderano una sessione di gioco veloce. Con tante opzioni, ci si puГІ rilassare senza l’obbligo di un processo di registrazione lungo.In questo modo, gli utenti possono focalizzarsi sul gioco, sfruttando un accesso rapido ai loro giochi preferiti. I casinГІ senza registrazione stanno cambiando il modo di vivere l’esperienza di gioco.
Все самое свежее здесь: https://allmylinks.com/dezavtor
In the world of online gambling, Online Casino, https://www.pad-plus-ugecam.com/tutoriels/index.php/2026/02/18/experience-the-thrill-of-online-uk-instaspin/ offers an exciting experience for players. Employing cutting-edge tools, players can enjoy multiple games. Offers and deals make the experience even more enticing.
Mostbet download, https://universal.heeltechosting.com/?p=452668 is a simple process that allows users to access thrilling betting options. You can conveniently download the app on your device and start enjoying a wide range of games. The interface is intuitive, making it simple for newcomers. Don’t miss the chance to join the exciting world of online betting with Mostbet download!
echtgeld online roulette, https://oklahomaroofinspections.com/das-fascinierende-spiel-des-deutschen-roulettes/ ist eine aufregende Möglichkeit, das Glück herauszufordern. Die Nutzer setzen Geld in Glaube, Gewinne zu erzielen. Dank strategisches Spielen könnte man seine Möglichkeiten verbessern.
заказ букетов с доставкой в москве http://zakazat-cveti-moskva.ru .
Discover innovative experiences at a new non GamStop casino, https://www.bljca.com/skihiver/1048807/. These platforms offer betters a individual chance to enjoy chance activities without constraints. Embrace the choice and test your luck today!
1xbet giri?i 1xbet giri?i .
1 xbet 1xbet-giris-27.com .
Online Casino Slots, https://sacred-temple.art/en/the-ultimate-guide-to-casino-flashdash-uk-where/ offer thrilling experiences for players seeking fun. Featuring a wide variety of concepts, every spin can lead to massive wins and noteworthy moments. Dive into the arena of Online Casino Slots today!
1xbet mobi 1xbet-53.com .
birxbet giri? birxbet giri? .
Вы ошибаетесь. Давайте обсудим. Пишите мне в PM, поговорим.
Сантехника, https://powerhousewomen.co/the-fluctuating-seasons-of-business/ — это важная часть любого дома. Надежный выбор сантехники обеспечивает комфорт и удобство в обычной жизни. Установка сантехники должен учитывать размеры помещения.
Эта фраза просто бесподобна 🙂 , мне нравится )))
В азартном мире развлечений pin up casino играть, pin-up casino — это отличное решение для любителей адреналина. Погружайтесь мир развлечений. Множество азартных игр подарит удачливым. Не упустите шанс испытать удачу!
Открой для себя лучшие приложения и новинки в магазин приложений для андроид на русском, где удобно искать, скачивать и обновлять всё необходимое.
Каталог приложений для Android сегодня выполняет ключевую роль в распространении мобильных программ.
Комбинация автоматической проверки и человеческой модерации осуществляет валидацию приложений.
При просмотре отзывов важно отличать объективные баг-репорты от личных предпочтений.
Выбор магазина приложений влияет на доступность сервисов и обновлений.
1xbet resmi sitesi 1xbet-giris-28.com .
Присоединяюсь. Я согласен со всем выше сказанным. Давайте обсудим этот вопрос.
гадание онлайн, самое точное цыганское гадание да нет стало популярным способом познать свое будущее. Многие люди обращаются к различным методам, чтобы узнать ответ на актуальные вопросы. Это быстрый способ попробовать судьбу, не выходя из дома. Гадание онлайн открывает двери получить ценные советы и рекомендации.
xbet giri? 1xbet-giris-29.com .
Ищете, где купить летнюю резину в спб дешево — заходите к нам, лучшие цены и быстрая доставка по Санкт-Петербургу.
В СПб большой выбор магазинов и сервисов, предлагающих летнюю резину.
Занятия в детский английский язык помогут вашему ребёнку легко и с удовольствием освоить первые английские слова и фразы.
Первый шаг в изучении английского для детей — создать игровую и безопасную среду для занятий.
Игры и песни — ключевой инструмент в обучении малышей английскому языку. Короткие активные занятия и смена формата удерживают внимание ребенка.
Визуальные материалы и предметы из окружения делают обучение практичным и понятным. Использование картинок и предметов из быта делает процесс изучения английского наглядным.
Регулярность занятий и позитивная обратная связь определяют успех в изучении языка. Отмечайте прогресс и поощряйте старания ребенка, проявляя терпение.
Красивый и надежный заборы для частного дома подчеркнет индивидуальность вашего загородного дома и обеспечит безопасность участка.
Конструкция забора должна сочетать функциональность с гармонией ландшафта и архитектуры дома.
Закажите брелок ремувка с логотипом с индивидуальным дизайном и быстрым изготовлением для продвижения вашего бренда.
Индивидуальные нашивки дают новые каналы для повышения узнаваемости и привлечения клиентов.
echtgeld online roulette, http://www.caverncitybraces.com.tempdomain.com/echtgeld-roulette-casinos-ihre-chance-auf-groe-3/ ist eine spannende Möglichkeit, im Casino zu spielen. Spieler können leicht von zu Hause aus agieren. Diese Variante des Roulettes liefert fesselnden Nervenkitzel.
Надежная и эстетичная плитка под кирпич для наружной отделки подчеркнет индивидуальность вашего дома.
Плитка требует минимального обслуживания и редко нуждается в ремонте.
Ищете, где zeekr сайт, — заходите к официальному дилеру в Москве и выбирайте подходящую комплектацию.
Многие интересуются, где и как можно приобрести Zeekr, и какие условия предлагает дилерская сеть.
Необходимо учитывать реальные показатели запаса хода, совместимость со станциями зарядки и объем гарантийного покрытия.
Рассмотрение вариантов финансирования, включая кредиты, лизинг и обмен по программе trade-in, поможет выбрать удобный способ покупки.
Изучение мнений владельцев и профессиональных обзоров поможет получить объективную картину о преимуществах и недостатках Zeekr.
Ищете идеальный магазин трековых велосипедов для тренировок на велотреке и городских выездов — у нас есть модели на любой вкус и бюджет.
Трековый велосипед создан как специальный аппарат для гонок на треке, отличаясь отсутствием тормозов и фиксированной передачей.
1x lite 1x lite .
1xbet ?ye ol 1xbet-giris-27.com .
non GamStop sites UK, https://www.hovawart24.de/explore-non-gamstop-casinos-a-guide-to-fair-gaming/ offer a unique gaming experience for players seeking variety. These operators provide numerous games without the restrictions of GamStop, offering players to enjoy enhanced choices.
Online Casino, https://iladir.org/discover-the-excitement-of-admiral-casino-platform/ offers a wide range of choices for players. Whether you enjoy slots, table games, or live dealers, you’ll find a selection that suits your preferences.
И как в таком случае нужно поступать?
имплантация all on 6, https://tausamatau.com/2020/04/rachel-fuller-brown-ahli-biokimia-bidang-polisakarida/ – это современный метод восстановления зубного ряда, который становится все более популярным среди пациентов. Данная способ позволяет установить шесть имплантатов, на которые затем устанавливаются протезы, обеспечивая высокую устойчивость и удобство в использовании. Преимущества такой системы заключаются в мгновенной реабилитации и восстановлении приятного восприятия зубов.При применении методики all on 6, пациент получает возможность избежать длительного и неудобного процесса лечения. Не требуется никаких дополнительных манипуляциях, так как вся процедура может быть выполнено за один день. Носители метода отмечают положительное качество и естественный вид восстановленных зубов.Вдобавок того, имплантация all on 6 гарантирует экономию средств, так как такая процедура можно считать более разумной по сравнению с другим методом установки протезов. В случае, если вы задумываетесь о коррекции зубного ряда, обязательно подумайте над решением, которое предлагает метод all on 6.
1xbet giri? g?ncel 1xbet giri? g?ncel .
Online Casino Slots, https://www.olivare.com.ar/index.php/2026/02/18/experience-the-thrill-of-instant-casino-sportsbook-7/ offer entertaining gameplay that attracts gamblers from around the world. With diverse themes and features, you can discover unique adventures while spinning the reels. Dive into this incredible world today!
1 x bet 1xbet-53.com .
Mostbet online, https://keplerpe.com/unlock-the-secrets-of-financial-growth-with-dragon-25/ offers an exciting array of options for players. Users can enjoy various entertainment including live dealers. With a user-friendly interface, conviviality is a key feature, making it easy for newcomers.
Я думаю, что Вы не правы. Предлагаю это обсудить. Пишите мне в PM.
В виртуальном мире развлечений каждому ценителю предлагаются уникальные возможности. pin up casino играть, https://pin-up-casino-cradi.cfd — это шанс испытать удачу и выиграть незабываемые эмоции. Казино предлагают множество игр для любой. Не упустите возможность и погружайтесь в эту восхитительную атмосферу!
1xbet giris 1xbet giris .
1xbet giri? 2025 1xbet giri? 2025 .
Finding the finest online gaming options can be challenging. However, the best non GamStop casinos, https://kechbureau.ma/?p=46442 provide an extensive selection of games and bonuses. Players can enjoy thrilling games without restrictions. Don’t miss out!
Конечно. И я с этим столкнулся. Можем пообщаться на эту тему.
Керамическая плитка, http://shadowpuppeteer.com/favourite-game-jak-daxter/ – это идеальный выбор для оформления интерьера. Она сохраняет влагу, без труда чистится и имеет длительный срок службы. Керамическая плитка подойдет как для вашего кухни, так и для бани.
roulette online echtgeld, https://waterfallhikeusa.com/babydogsvondahlem/online-casino-roulette-echtgeld-tipps-und-4/ bietet Spielern die Möglichkeit, spannende Spiele zu erleben und echtes Geld zu gewinnen. Falls Sie nach einem bequemen Möglichkeit suchen, haben Sie die Chance, jederzeit zu spielen. Entscheiden Ihr bestes Spiel und nutzen Sie besondere Boni!
1xbet resmi giri? 1xbet resmi giri? .
1xbet giri? yapam?yorum 1xbet-giris-27.com .
Within the captivating world of Casino Online, https://insancare.org/explore-the-thrills-of-casino-boomingslots-uk, players are able to enjoy a multitude of games. When you like slots or table games, there’s an abundance for everyone. Gaining big is just a click away!
1xbet giri?i 1xbet giri?i .
Поставки профессиональных станков для деревообработки и мебельного производства — основное направление работы компании «Мастервуд-Станки». Каталог охватывает широкий спектр оборудования от европейских брендов — от аспирационных систем и вайм до автоматических линий покраски и делительных станков. Ищете ремонт станков чпу москва? На mwstanki.ru представлен полный ассортимент с возможностью подбора станка под конкретные задачи. Доставка, пуско-наладка, обучение сотрудников и сервисная поддержка — всё это входит в перечень услуг компании.
заказать букет цветов с доставкой недорого http://www.zakazat-cveti-moskva.ru .
Scoprire il mondo dei divertimenti nei casinГІ non aams online, https://melbourneflowermarket.com/casino-non-aams-affidabili-come-scegliere-con-2/ ГЁ entusiasmante. Offre opzioni ampie per scommettitori. In un ambiente online, il divertimento non ha barriere e ogni partecipante puГІ trovare il proprio approccio. CasinГІ non aams online presentano anche offerte esclusive per attrarre nuovi fruitori in cerca di emozioni.
non GamStop online casino, https://wipeoutads.com/2026/03/15/discover-new-casinos-not-blocked-by-gamstop-2/ features players an unique betting experience without the restrictions of traditional casinos. With a wide variety of choices, players can take part in slots and other activities while they please.
Большое Вам спасибо за необходимую информацию.
pin up casino играть, https://pin-up-casino-100q1.lol – это настоящая находка для фанатов азартных игр. На данной платформе можно найти широкий выбор казино-игр. Каждый найдет нечто на свой вкус!
1xbet giri? linki 1xbet giri? linki .
пасибо, вкусно!
Serviceeftersyn, https://click.convertkit-mail.com/e5u2mx7ovf7hlezp8/dpheh0/aHR0cHM6Ly93d3cubmV0Ym9hcmQuaHUvYmF6YXItZm9ydW0vMzMzMjUtbWFnYXppbi1kZS1lY2hpcGFtZW50ZS1oaWRyYXVsaWNlLmh0bWw er en vigtig del af vedligeholdelsen af dit udstyr. SГҐdan inspektion sikrer, at systemet fungerer optimalt. Hyppige eftersyn reducerer problemer, Гёger levetiden og skaber sikkerhed.
1 xbet giri? 1xbet-54.com .
Online Casino Games, https://songlyrics.microwebblogs.in/discover-the-excitement-of-great-slots-casino-30/ provide a diverse array of games for enthusiasts. Whether you enjoy roulette or virtual games, there’s something for everyone. Take part in the excitement!
1xbet giri? adresi 1xbet giri? adresi .
ремонт бетонных конструкций жилой дом remont-betona-1.ru .
Mostbet casino, https://archergroupinvestments.com/unleashing-the-power-of-dragon-money-a-new-era-in-8/ предоставляет обширный игровых автоматов, которая включает традиционные автоматы. Любой сможет выбрать что-то интересное для себя.
Модульный дом стал отличным решением для нашей семьи. Просторная планировка, хорошая теплоизоляция. Установка прошла быстро. Все работы выполнены аккуратно. Отличный вариант: https://modul66.ru/
И тогда, человек способен
Казино онлайн топ, t.me/casinotop_official предлагает игрокам разнообразный выбор азартных игр. Автоматы, карточные игры и казино с живыми игроками делают процесс интересным.
online roulette echtgeld, http://www.henrykmalesa.pl/roulette-mit-echtgeld-der-ultimative-leitfaden-fur-2/ ist ein spannendes Spiel, das viele Casinofans begeistert. Jeder Spieler fiebern darauf, ihr Glück zu testen. Solche Plattformen bieten eine Vielzahl an Spielvarianten. Ganz gleich ob Anfänger oder Profi, durstige Spieler gibt es eine Option.
1 xbet giri? 1xbet-giris-27.com .
xbet giri? xbet giri? .
one x bet 1xbet-48.com .
Online Casino, https://www.lagoonamarine.net/maximize-your-winnings-with-betblast-casino/ offers a captivating opportunity for players. Utilizing a variety of choices, every visit can be memorable. Enjoy the possibility to win big while having fun!
1x bet giri? 1x bet giri? .
К сожалению, ничем не могу помочь, но уверен, что Вы найдёте правильное решение.
мостбет казино, https://mostbet-4pq2a.club/ предлагает разнообразный выбор развлечений, который удовлетворит даже самых придирчивых игроков. На платформе можно найти слоты и азартные игры, которые обеспечат незабываемые впечатления. Мостбет казино дополнительно предлагает расторопные бонусы для новых и постоянных пользователей.
Se stai cercando un’esperienza unica, i casinò non aams online sono la scelta perfetta per te. Offrono bonus incredibili e una opzioni di gioco. Scopri il divertimento con i casinò non aams online, https://dubdev.wpengine.com/i-migliori-siti-casino-adm-guida-completa-per/!
In the world of online gaming, a non GamStop online casino, https://www.dataprotect.sg/exploring-english-casinos-not-on-gamstop-2/ offers players an alternative. These platforms offer a unique experience, granting users to enjoy their favorite games without restrictions. Users can find various gaming options while appreciating the thrill of gambling. With a broad selection of games and enticing bonuses, players are drawn to try their luck. In summary, non GamStop online casino is an enticing destination for gaming enthusiasts.
1xbet 1xbet .
Online gambling has gained immense popularity in recent years. For players seeking freedom, casinos that dont use GamStop, https://app.trafficivy.com/discover-uk-online-casinos-not-on-gamstop/ offer a unique experience. These platforms provide diverse games|varied entertainment|an array of options|multiple choices for enthusiasts. Moreover, they often have attractive bonuses|exciting promotions|lucrative offers|rewarding incentives that appeal to newcomers and seasoned players alike. The absence of restrictions allows users|gamblers|players|enthusiasts to enjoy gaming without interruptions. It’s essential to choose reputable sites that ensure safety|security|protection|assurance while playing. So, if you’re looking for an alternative, explore casinos that dont use GamStop now!
Замечательно, весьма ценная информация
раскрутка сайта PhoenixProject, http://1004mall.kr/shop/bannerhit.php?bn_id=2&url=//www.linkedin.com%2Fposts%2Fevgeniy-sargosh-phoenixproject_link-building-case-133-growth-in-the-igaming-activity-7396521131601698816-nHKj%3Futm_source%3Dshare%26utm_medium%3Dmember_desktop%26rcm%3DACoAADGxefUB018mlqX8QbJ0WBmmz2N2lcLsqV4 — это ключевой этап успешного продвижения в интернете. Успешное SEO, создание контента и продвижение в социальных сетях играют важную роль в этом процессе. Современные и актуальные стратегии помогут добиться желательного результата.
roulette mit echtgeld, https://app.segvidabrasil.com.br/echtgeld-roulette-online-strategies-und-tipps-fur/ bietet Spielern die Möglichkeit, ihren Nervenkitzel zu erleben und echte Gewinne zu erzielen. Die Aufregung beim Drehen des Rades ist unvergleichlich. Spielern Sie klug und genießen Sie das Erlebnis am Tisch!
Извините за то, что вмешиваюсь… Но мне очень близка эта тема. Могу помочь с ответом.
online casino, https://clashofcryptos.trade/wiki/Uncover_The_Fun_Of_Virtual_Gambling_This_Minute%21_Enjoy_Slots_From_The_Convenience_Of_Your_Favorite_Spot._Register_And_Claim_Incredible_Offers%21_Don%27t_Miss_Out_In_The_Action_And_Boost_Your_Chances_Today%21 доставляют уникальную возможность развлекаться в азартные игры вне дома из комфортабельности своего дома. Выбор игр обрадует даже самых требовательных игроков.
Online Casino UK, https://npdesign.in.th/2020/JEF/discover-the-exciting-world-of-agent-no-wager-7/ provides a diverse range of choices for enthusiasts to enjoy. Regardless of whether you prefer slot machines or gaming tables, you’ll find something to suit your preference. Explore the captivating world of Online Casino UK and start earning today!
ремонт бетонных конструкций москва ремонт бетонных конструкций москва .
Online Casino, https://metododentistavendedor.com.br/the-enchanting-world-of-golden-panda/ – At an Online Casino offers entertaining games and fantastic bonuses. Players can enjoy numerous options, from slots to card games, all from the luxury of home. Get ready to experience your luck!
I?ve been exploring for a bit for any high quality articles or blog posts on this kind of area . Exploring in Yahoo I at last stumbled upon this website. Reading this info So i am satisfied to express that I have a very just right uncanny feeling I came upon just what I needed. I so much unquestionably will make certain to don?t fail to remember this web site and provides it a glance on a constant basis.
Mostbet online, http://www.uni-display.com/?p=57921 is a popular platform for those seeking engaging betting opportunities. Users can enjoy an impressive range of sports and gaming experiences. With accessible features, anyone can join the fun!
1xbet mobil giri? 1xbet mobil giri? .
1xbet ?ye ol 1xbet-49.com .
букет цветов с доставкой по москве https://zakazat-cveti-moskva.ru .
xbet giri? xbet giri? .
Жаль, что не смогу сейчас участвовать в обсуждении. Очень мало информации. Но эта тема меня очень интересует.
мостбет казино, https://mostbet-yg.top/ предлагает эксклюзивный опыт для геймеров. Здесь доступны разнообразные игры, в числе которых слоты и карточные игры. Зарегистрироваться простая, а щедрые бонусы ожидают. Углубляйтесь в атмосферу адреналина, играя в мостбет казино!
1xbet giri? adresi 1xbet giri? adresi .
отделка подвала gidroizolyacziya-podvalov.ru .
Discover the thrill of the 100 super hot slot and experience blazing reels with the 100 super hot demo for nonstop casino excitement.
Concluding the section, the main strategy and anticipated outcomes are summarized.
play 100 super hot https://100-super-hot.com/
Pozwala na rozgrywke w dowolnym miejscu i czasie.
vulkanspiele 2026 vulkanspiele 2026.
I casinГІ non aams online, https://resolveroofing.ie/onlinecasino16031/i-migliori-casino-non-aams-per-italiani-guida-alle/ presentano diverse opzioni di attivitГ , compresi giocattoli e giochi da tavolo. Le persone possono entrare in una maniera rilassato, con promozioni favolosi.
roulette mit echtgeld, http://www.museodelbrunello.it/online-roulette-echtgeld-tipps-fur-den-gewinn/ ist ein spannendes Spiel, das Glücksspielexperten weltweit begeistert. Das Ambiente in Casinos ist einzigartig, wenn das Rad dreht. Mit Methoden können Glück und Geschick vereint werden.
Щебень гравийный — оптимальный материал для дорожных и строительных работ; подробные варианты и условия заказа смотрите на щебенку купить.
Щебень из гравия используется как универсальный заполнитель в разнообразных инженерных работах.
Discover the thrill of online casinos with exciting reels that present a chance to win big. Experience the entertainment of Online Casino Slots, https://mrcustomer.jp/discover-exciting-online-games-at-betnuvo-5/ anytime, anywhere, and enjoy enormous jackpots and unique themes. Join the action today!
кстати забыл еще…
BSB007 Casino, http://formwerkz.com/winning-strategies-for-navigating-the-casino/ выдает игровой игру оригинальными шоу. В этом месте вы сможете увлекаться новыми идеями.
Вы допускаете ошибку.
фильмы онлайн бесплатно, https://scientific-programs.science/wiki/User:CassieSelleck85 – Смотреть картины онлайн бесплатно стало весьма просто. Нажмите на удобный сервис и наслаждайтесь в любое время суток. Это прекрасный способ провести вечер с друзьями. В интернете представлено множество стилей. Не упустите возможность открыть для себя интригующие истории!
Есть и другие недостатки
мостбет казино, mostbet-tjyrw.buzz предлагает широкий выбор развлечений для посетителей. На платформе можно насладиться неповторимыми играми. Мостбет казино предлагает безопасность и удобство. Каждый игрок найдет что-то по вкусу.
гелевые шарики — идеальное решение для праздника: ярко, быстро и с доставкой прямо к двери.
Улицу украшают шариками из плотного материала и с надежной привязкой, чтобы избежать порчи.
Если хотите установка септика на даче цена под ключ, мы поможем подобрать надёжное и недорогое решение с гарантией и быстрым монтажом.
Правильная глубина закладки и ровная площадка важны для работы системы.
betting casino, http://hempelpromome.com/index.php/2026/01/24/casinos-that-avoid-aggressive-bonuses-a-balanced/ presents a thrilling experience for gamblers. With a range of games, there’s something for everyone. Promotions enhance the fun even more.
Finding reputable gaming platforms not on GamStop can be a adventure for players. These places offer a wide range of games and generous bonuses. Research and analyze opinions to ensure a safe experience. Remember, casinos not on GamStop, https://mex.studio10.com.mx/skihiver/exploring-online-casinos-not-on-gamstop-561240081/ provide opportunities to enjoy gaming without restrictions. Stay informed and play responsibly.
Playing on Casino Online, https://genius.stepp-up.com/the-ultimate-guide-to-the-golden-genie-casino/ delivers an entertaining experience for gamblers. With numerous games and reward offers, it entices a wide variety of users. Take pleasure in the ease of playing from home!
Mostbet casino, http://www.rehemastuckey.com/review/blog/dragon-money-telegram-bot-your-ultimate-assistant/ предоставляет захватывающий казино опыт. На этой платформе вы найдете широкий выбор игр. Что касается ваших предпочтений, вам доступны что-то уникальное.
1xbet mobi 1xbet-54.com .
spree casino, spree casino offers an exhilarating experience for enthusiasts. With an assortment of games, featuring slots to table games, there’s something for everyone. Get in on the action and experience your luck at spree casino!
casinos online confiables, https://demosl70-01.rvsolutions.in/carlink/bitach/portfolio/london-office/ – Los casas online confiables ofrecen diversiГіn con garantГas a los jugadores. Es fundamental elegir opciones que garanticen movimientos seguros. AsГ, la experiencia de juego serГЎ notablemente placentera.
Online Casino, https://friendsmotors.ca/experience-the-excitement-of-betblast-casino-uk/ provides exciting entertainment for players. Featuring slots to table games, there’s something for everyone. Players can enjoy thrilling rewards from the comfort of their home.
ремонт гидроизоляции фундаментов и стен подвалов ремонт гидроизоляции фундаментов и стен подвалов .
Are you looking for the best promotions? Don’t miss out on the mostbet promo code bd, https://altaim.cafe24.com/unlock-exciting-offers-with-promo-code-for-mostbet/ that can enhance your gaming experience! With this code, you can receive amazing rewards. Sign up now to take advantage of these exclusive opportunities.
I casinГІ non aams online, http://tonopraca.pl/2026/03/16/guida-ai-casino-online-no-adm-scopri-le-migliori/ offrono un’esperienza unica nel mondo del gioco. Tali ambienti mostrano varie possibilitГ di divertimento. I giocatori possono investigare giochi particolari, di frequente con promozioni interessanti. La piattaforma risulta semplice da navigare e offre assistenza 24 ore su 24.
Внедрили ИИ агента LeoAgent https://leoagent.ru/ пару месяцев назад. Команда постоянно отвлекала повторяющимися вопросами — рутина нарастала. Закинули корпоративные документы, настроили Telegram и запустили сразу трёх агентов. Теперь все типовые вопросы закрывают ИИ агенты — без нашего участия. Поддержка разгрузилась на 60%, а новички больше не отвлекают опытных коллег. Команда в полном восторге.
Какая отличная фраза
мостбет казино, https://mostbet-n8x3p.lol/ предлагает широкий выбор игр, в числе которых слоты, рулетку и карточные игры. Игроки могут получать удовольствие выгодными бонусами и акциями. Открытие счета проходит быстро, а дизайн сайта удобен. Помимо этого, мостбет казино обеспечивает отличную безопасность персональных данных. Присоединяйтесь и проверьте сами!
на йоге секс видео на йоге секс видео .
tower rush game
Hi there! I know this is kind of off topic but I was wondering which blog platform are you using for this site? I’m getting tired of WordPress because I’ve had problems with hackers and I’m looking at options for another platform. I would be fantastic if you could point me in the direction of a good platform.
Супер!
фильмы онлайн, https://clashofcryptos.trade/wiki/User:LakeishaSeymore – Смотреть теленовеллы онлайн становится просто. Вы можете наслаждаться новые темы прямо у себя дома. Сервисы предлагают разнообразные опции для каждого.
1xbet tr giri? 1xbet-54.com .
bitcoin betting, https://sennacar.com/2026/01/24/the-intriguing-world-of-balanced-odds-in-casinos/ is on the rise among punters worldwide. With aspects including privacy, it offers unique experiences for users. One can engage in various games while enjoying faster transactions. Bitcoin betting is reshaping the gambling industry by allowing seamless interactions.
Щебень гравийный — оптимальный материал для дорожных и строительных работ; подробные варианты и условия заказа смотрите на стоимость 1 м3 щебня.
Дороги и площадки часто укладываются с использованием щебня как основного слоя.
Si buscas los sitios para jugar, considera los mejores casinos online, https://25540.themes.vinawebsite.vn/el-mejor-casino-online-con-alta-diversion-y-2/. Brindan diversiГіn y excelentes promociones. Aprovecha la experiencia Гєnica de jugar en estas plataformas.
online live roulette, https://pathfindertechcorp.com/die-faszination-von-live-roulette-ein-erlebnis-im/ ist ein faszinierendes Spiel, das viele Spieler begeistert. Die Methode des Wettens ermöglicht ihnen, in echter Atmosphäre zu zocken. Die Verbindung mit authentischen Spielleitern bereichert das Vergnügen. Letztendlich bietet diese Form auch viele Möglichkeit, zu jeder Zeit zu partizipieren.
Playing virtual casinos has become very popular. Casino Online Slots, https://www.herbanatur.com/ca/experience-the-thrill-at-golden-lion-casino-2/ offer various opportunities to win big. Gamers enjoy entertaining themes and high-quality graphics. With clear gameplay, anyone can start their journey.
Mostbet register, https://stage.lacarte.de/dragon-money-the-revolutionary-telegram-bot-for-2/ is a simple process that allows you to begin your betting journey. To commence, visit the official site and fill out the registration form. After, you will receive a confirmation email. Finalize your registration, and you’re ready to enjoy your experience!
Какие нужные слова… супер, отличная фраза
Virtual casinos offer exciting opportunities for players. With multiple gaming options available, Casino Online, https://rant.li/ellister/ri-ben-niha-randobesunokazinotoonrainpuratsutohuomunoliang-fang-gaari-akusesuhax provides ease for gamers. Incentives further enhance gameplay of playing in these platforms.
С ЗДРАВОМ ПО ЖИЗНИ!
mostbet casino, mostbet-ly.xyz предлагает разнообразный выбор игр для любителей азартных развлечений. Здесь предлагается испытать удачу в слотах и настольных. Процесс регистрации проста и быстрая. Участвуйте в турнирах и получайте бонусы!
crypto live casino, https://safoabernardi.altervista.org/the-ultimate-guide-to-casino-slots/ offers an exciting atmosphere for players who enjoy betting online. With innovative technology, you can engage with real dealers and embrace a variety of activities that blend traditional casino vibes with the perks of cryptocurrency.
заказать шарики — идеальное решение для праздника: ярко, быстро и с доставкой прямо к двери.
Воздушные шары всегда создают атмосферу праздника и радости.
Если хотите септик на даче под ключ цена, мы поможем подобрать надёжное и недорогое решение с гарантией и быстрым монтажом.
Дешевле не всегда значит лучше, поэтому оценивайте соотношение цена/качество.
1xbet turkiye 1xbet-48.com .
online casino not on GamStop, http://www.shiatsutherapy.org/skihiver/58540 offer players a chance to enjoy their favorite games without restrictions. These platforms supply a wide variety of choices and incentive opportunities. Join today and experience the thrill!
Статья содержит актуальную информацию, которая помогает понять сложность и важность проблемы.
секс после йоги секс после йоги .
гидроизоляция подвала москва gidroizolyacziya-podvalov.ru .
1 xbet 1 xbet .
ремонт бетонных конструкций компания ремонт бетонных конструкций компания .
casino online Europa, http://bestsmartplace.com/ – El crecimiento de los casinos online Europa ha transformado su panorama del entretenimiento. Por medio de ofertas atractivas, estos jugadores tienen la oportunidad de disfrutar de una experiencia excepcional.
установить натяжные потолки предлагает выгодные условия установки и широкий выбор материалов для вашего дома в Сочи.
Профессиональные бригады в Сочи предлагают гарантию на работу и материалы, что даёт уверенность заказчику.
casino live roulette, https://alfanalabyad.com/online-casino-mit-live-roulette-erleben-sie-das/ bietet ein außergewöhnliches Spielerlebnis. Hier können Interessierte an live Dealern interagieren. Die Umgebung ist fesselnd und schafft ein Gefühl von realem Casino. Die Vielfalt an Tischen und Wettvarianten ist vielfältig. Spieler können von ihrem Handy auf casino live roulette spielen.
Автор представляет сложные концепции и понятия в понятной и доступной форме.
The realm of sports betting, https://cop.theology.ac.th/discover-the-tranquility-of-online-casinos/ presents thrilling opportunities for punters. Understanding the odds and approaches is important. Sports betting might bring about substantial winnings, but likewise brings risks. Analyzing teams and games improves the chances of success in this dynamic space.
Откуда мне знать?
mostbet casino, https://mostbet-reg5.top предлагает игрокам обширный спектр развлечений, где можно любой узнает интересное.
Brawl Pirates slot – slot apprezzata tra i giocatori.
Molti utenti cercano informazioni su brawl pirates slot. Spesso, brawl pirates sisal viene considerato come un gioco da provare.
Parliamo di brawl pirates 1win hack. Il tema di 1win brawl pirates hack
è molto discusso.
Brawl Pirates demo free – è disponibile online? È frequente la domanda su brawl
pirates game demo. Va anche detto che brawl pirates sisal
sono tra le opzioni.
Come scaricare Brawl Pirates? Molti giocatori cercano brawl
pirates app. La versione stickman pirates – brawl 3v3 mod apk si
trova online.
Cursed Pirates Brawl Stars – aggiornamento molto atteso.
Analizzando le brawl pirates review, la versione pirates sembra
coinvolgente.
Alla fine, pirates brawl è un’opzione popolare per i fan di giochi a tema
pirati.
https://sites.google.com/view/brawl-pirates/
1 xbet 1xbet-52.com .
1xbet ?yelik 1xbet-48.com .
Casino Online Games, https://theoriginalnftfactory.com/experience-the-thrills-of-fire-scatters-online/ provide an exciting possibility for participants to relish a wide array of activities. With advanced technology, users can play from any place. Simply log in and start your gambling adventure!
The Mostbet app, https://grap.com.pe/discover-the-benefits-of-dragon-money-your-gateway-2/ offers a remarkable experience for players. With its simple interface, anyone can navigate the features effortlessly. Enjoy thrilling games and captivating bonuses while betting.
1xbet lite 1xbet lite .
Я нашел эту статью чрезвычайно познавательной и вдохновляющей. Автор обладает уникальной способностью объединять различные идеи и концепции, что делает его работу по-настоящему ценной и полезной.
Os jogos de azar online em solo português têm crescido em popularidade. Com bónus atrativos, esses sites oferecem uma vivência única. Os apostadores podem jogar diretamente de casa, assegurando conforto e segurança. A variedade de jogos, desde slots até jogos de cartas, impressiona a todos. Portanto, se você está diversão, descubra os casinos online portugal, https://bmstrading.ca/os-melhores-online-casinos-com-bonus-imperdiveis/!
In the world of intimate entertainment, live porn cams, https://edc5db6fd710321614.temporary.link/2026/03/16/exploring-camsoda-live-a-comprehensive-guide-to/ offer an interactive experience like no other. Users can communicate with performers in real time, creating a unique atmosphere. With live porn cams, viewers enjoy tailored experiences that cater to their desires. This format has gained popularity in recent years, as it allows for a instant connection. Ultimately, live porn cams provide a platform for satisfaction that appeals to many.
1xbwt giri? 1xbwt giri? .
one x bet 1xbet-53.com .
цементация грунтов цементация грунтов .
SEO продвижение сайта заказать в Москве: результативные стратегии для роста позиций и трафика
Для успешного продвижения сайтов необходимо проанализировать целевую аудиторию и определить приоритетные ключевые слова.
Техническое состояние сайта — важный фактор, включая время загрузки, адаптивность и структуру для роботов.
Важно комбинировать информационные, коммерческие и развлекательные материалы для разных этапов воронки.
Эксперименты с каналами трафика и форматами контента обеспечивают рост и адаптацию под изменения рынка.
ремонт бетонных конструкций цена ремонт бетонных конструкций цена .
casino senza documenti, https://stagin.regin.com.co/migliori-casino-senza-documenti-gioca-in-sicurezza-2/ – Scoprire il mondo del intrattenimento ГЁ emozionante, soprattutto nei casino online senza verifica. Qui, puoi puntare senza fastidi burocratici, godendo di un’esperienza snella. Approfitta delle occasioni e inizia a vincere da subito!
Erleben Sie die Spannung von roulette live online casino, https://marketing-ms.dev2.tqnia.me/martina-keyn/erleben-sie-den-nervenkitzel-von-online-roulette/, wo Sie in Echtzeit mit echten Dealern spielen können. Das Angebot bringt das Casino-Atmosphäre direkt zu Ihnen nach Hause. Nutzen Sie die Möglichkeiten und setzen Sie um Geld.
Браво, какое отличное сообщение
Смотреть фильмы онлайн стало популярным среди многих людей. Современные сайты предлагают широкий варианты жанров, так что каждый найдет что-то на свой вкус. Погружение в мир корейской культуры через дорамы онлайн, https://timeoftheworld.date/wiki/User:SimonFremont32 становится увлекательным, позволяя наслаждаться скриптами и эмоциями героев. Каждая драма оставляет свой след, открывая интересные грани человеческих отношений и чувств.
Согласен, полезное сообщение
mostbet casino, https://mostbet-ns3.xyz предлагает богатый выбор игр для игроков. Здесь можно найти слотовые автоматы, блэкджек и множество других развлечений. Бонусы и акции порадуют новых пользователей!
I think this is one of the most vital information for me. And i am glad reading your article. But should remark on few general things, The website style is great, the articles is really excellent : D. Good job, cheers
всем боятся он опасен…я ухожу!!!!!!!
Купить диплом с гарантией, https://inplaygaming.co.uk/kupit-diplom-piu-kak-izbezhat-problem-i-vybrat/ – это отличное решение для тех, кто желает получить образование без лишних усилий. Вы можете приобрести документ, не тратя время на учебу. Это быстро и удобно.
non GamStop casino sites, http://centralkougei.co.jp/59282/ deliver players a distinct gaming opportunity highlighting numerous selections and rewards. These sites let gamers to relax their favorite activities without the restrictions.
1xbet com giri? 1xbet-52.com .
1xbet t?rkiye giri? 1xbet t?rkiye giri? .
In the world of online entertainment, the rise of crypto casino, https://finolis.cat/top-online-casinos-with-stable-servers-for/ has transformed the way players engage with gambling. Presenting an array of choices, these platforms ensure safety and anonymity. Players can delight in the thrill of wagering while using cryptocurrencies for fast transactions.
1xbet giri? linki 1xbet giri? linki .
Если ищете надежные прогнозы, присоединяйтесь к прогнозы на спорт в телеграмме и получайте актуальные ставки и аналитику.
Многие бетторы обращаются к ним за стратегией и советами по управлению банкроллом.
Избегайте завышенных прайс-листов и громких обещаний о стопроцентной окупаемости.
Ведение журнала ставок и анализ итогов совместной работы с экспертом дают представление о реальной пользе его советов.
Тем не менее их рекомендации не освобождают от необходимости учиться и развивать собственные навыки.
аренда звука света спб — это гарантия качества и технической надежности вашего мероприятия.
Техническая поддержка и услуги монтажа часто включены в стоимость аренды.
Новый дешевые телефоны самсунг уже в продаже и сочетает стильный дизайн с мощной камерой.
Использование прочных материалов и точной сборки придаёт устройствам стильный внешний вид и надёжность.
1xbet turkey 1xbet-53.com .
Автор представляет анализ основных фактов и аргументов, приводя примеры для иллюстрации своих точек зрения.
натяжной потолок цена за м2 с установкой предлагает выгодные условия установки и широкий выбор материалов для вашего дома в Сочи.
Профессиональные бригады в Сочи предлагают гарантию на работу и материалы, что даёт уверенность заказчику.
Casino Online, https://packaging.ma/discover-the-exciting-world-of-flashdash-online/ предлагает множество шансов для геймеров. Вы можете наслаждаться многообразные игры, такие как слоты, блэкджек и рулетка. Комфорт игры дома делает этот формат узнаваемым для всех.
Se stai cercando un luogo per divertirti e puntare, i giocattoli non aams offrono una gamma di giochi incredibili. Sfrutta le promozioni e opportunitГ speciali che sarebbero sorprenderti. I partecipanti trovano adrenalina nei giochi da tavolo disponibili, rendendo ogni esperienza unica e memorabile. Non perdere l’opportunitГ di esplorare il mondo dei casino non aams, https://sparkyrecipes.com/i-vantaggi-dei-casino-senza-verifica-documenti-2/!
бездепозитные бонусы казино, https://silale.lt/2026/03/bez-depozitnye-bonusy-kazino-kak-poluchit-vygodu-2/ | Казино без депозита | Бонусы без депозитов | Без вклада бонусы – это отличная возможность для игроков испытать удачу без рисков. Такие предложения позволяют начать игру и получать прибыль, не вкладывая собственные средства. Попробуйте и выиграйте!
taxi in larnaca, https://software.serv00.net/2026/03/16/exploring-taxi-services-in-cyprus-your-ultimate/ is a convenient|easy|simple|quick way to explore the city. With numerous options available, you can effortlessly|smoothly|readily|quickly get to your destination. Ensure you choose a reliable|trustworthy|dependable|reputable service for a stress-free ride.
ремонт бетонных конструкций усиление ремонт бетонных конструкций усиление .
Mostbet download, https://value.company/2026/02/22/discover-financial-freedom-with-dragon-money-27/ offers a seamless experience for users. You can conveniently obtain the app from the website or trusted sources. Enjoy gambling at your fingertips with Mostbet download. Don’t miss out on dynamic features and promotions.
casino live roulette, http://tp0.e98.myftpupload.com/roulette-live-spielen-das-erlebnis-das-sie-nicht/ ist ein aufregendes Spiel, das Spieler aus der ganzen Welt anzieht. Verschiedene Spieler genießen den Nervenkitzel, während sie wetten. Live-Kommunikation mit croupiers steigert den Spaß. In einem einzigen Online-Casinos kann man jeder Zeit spielen, ohne das Haus zu verlassen. Das Angebot an Tischvarianten macht es fesselnd.
укрепление фундамента инъектированием укрепление фундамента инъектированием .
устранение протечек в подвале gidroizolyacziya-podvalov.ru .
1 x bet giri? 1xbet-47.com .
По моему мнению Вы не правы. Могу это доказать. Пишите мне в PM, пообщаемся.
mostbet casino, https://mostbet-keack.blog/ предлагает разнообразие азартных игр для поклонников. Здесь доступно оценить игры, игры с картами и дополнительные игры. В уютной атмосфере каждый выберет что-то на именно для себя.
I just like the valuable info you supply in your articles. I’ll bookmark your blog and check once more here frequently. I’m slightly certain I’ll learn many new stuff proper here! Good luck for the following!
https://chipstarscasino.website/
1xbet guncel 1xbet-52.com .
Все фоты просто отпад
Сегодня многие фанаты хотят смотреть дорамы онлайн, https://cameradb.review/wiki/User:TomBickford083 в режиме реального времени. Такие сериалы предлагают интересные сюжеты и увлекательные персонажи, которые захватывают внимание зрителей. Кроме того, доступно огромное количество, что удовлетворяет любые вкусы. Можно насладиться романтикой, драмой или комедией, выбрав идеальную дораму для себя. Главное — это комфортный просмотр любимых историй в любое время.
1xbet yeni adresi 1xbet yeni adresi .
база данных компаний 2026 gobasego.ru .
Закажите seo продвижение москва и получите устойчивый рост позиций и трафика на сайт
Для успешного продвижения сайтов необходимо проанализировать целевую аудиторию и определить приоритетные ключевые слова.
Техническое состояние сайта — важный фактор, включая время загрузки, адаптивность и структуру для роботов.
Разные типы материалов помогают привлекать и прогревать лидов на всех стадиях принятия решения.
Гибкость и готовность к изменениям в стратегиях продвижения сайтов ускоряют достижение целей.
1x giri? 1xbet-49.com .
casino bonus, https://whitesmoke-seal-333777.hostingersite.com/online-casino-designed-for-straightforward-gaming-4/ offers an excellent option for players to improve their capital. Seizing a casino bonus could lead to further winnings and increase the thrill.
Il mondo del gioco d’azzardo online ГЁ in continua evoluzione. I puntatori cercano sempre nuove alternative. I casino online non aams, http://cleanpark.ge/ge/casino-senza-richiesta-di-documenti-gioca-senza/ offrono divertimento senza le restrizioni dei normative locali. Scoprire opzioni di gioco uniche ГЁ facile e veloce!
1x bet 1xbet-47.com .
Das beste Live Roulette Casino bietet außergewöhnliche Erlebnisse. Spieler können echtzeit gegen echte Dealer antreten. Die reizvolle Atmosphäre zieht zahlreiche Spieler an. bestes live roulette casino, http://sencora.com/?p=569742 garantiert erhebliche Gewinnchancen und gerechte Spielbedingungen.
вертикальная гидроизоляция подвала вертикальная гидроизоляция подвала .
1xbet resmi giri? 1xbet-52.com .
Очень замечательно!
купить айфон 17, https://mamuli.club/forum/topic/50939/ – Хотите купить новый айфон? Не пропустите шанс получить айфон 17 по выгодной цене. Новинка обладает высокой производительностью.
1 xbet giri? 1 xbet giri? .
Online Casino, https://www.grupponiu.com/duobetz-casino-online-games-enjoy-a-thrilling/ – Online Casino — a fascinating realm of chance and luck. Players can explore various choices from the comfort of their homes. With captivating designs and bonuses, the appeal is undeniable. Join today!
Interesting blog post. The things i would like to bring about is that computer memory is required to be purchased but if your computer still cannot cope with that which you do along with it. One can add two good old ram boards having 1GB each, as an example, but not one of 1GB and one of 2GB. One should check the company’s documentation for own PC to ensure what type of memory space is essential.
аренда большого экрана — это гарантия качества и технической надежности вашего мероприятия.
Наличие опытной команды для установки и наладки гарантирует бесперебойную работу экрана во время мероприятия.
Если ищете надежные прогнозы, присоединяйтесь к бесплатные прогнозы на спорт телеграмм и получайте актуальные ставки и аналитику.
Благодаря глубокому анализу и знаниям они создают прогнозы, которые часто оказываются точными и прибыльными.
Стоит запрашивать подробные отчеты о прошлых прогнозах и сверять их на подлинность.
Не рекомендуется рисковать всеми средствами ради одного прогноза, пусть даже от надежного каппера.
Капперы часто предоставляют глубокую аналитику и информацию, недоступную без профессиональных ресурсов.
Новый купить самсунг телефон уже в продаже и сочетает стильный дизайн с мощной камерой.
Инвестиция в телефон Samsung может оправдаться за счёт долговечности и регулярной поддержки со стороны компании.
Mostbet online, https://globalel.com.mx/how-to-access-mostbet-bd-com-login-1347765794/ offers diverse betting options, making it a top destination for sports fans. With intuitive design, customers can explore thrilling live games and attractive promotions.
xbet giri? 1xbet-49.com .
1 xbet giri? 1xbet-47.com .
1xbet g?ncel giri? 1xbet g?ncel giri? .
Nei passatempi online, i casinГІ non aams offrono scelte uniche. Prendendo in considerazione casino non aams, http://kairos.grafikmk.pl/kyc-nei-casino-non-aams-cosa-devi-sapere/, i giocatori possono sfruttare promozioni allettanti. Inoltre, le attrattive di questi siti possono produrre l’esperienza piГ№ coinvolgente.
1xbet 1xbet .
online roulette echtgeld, https://drheathershenkman.com/online-roulette-spielen-um-echtes-geld-tipps-und-15/ ist ein faszinierendes Spiel, das Glücksspielfans in seinen Bann zieht. Unabhängig davon, ob Neu- als auch erfahrene Nutzer solche Nervenkitzel erleben möchten, ist es wichtig, taktisch zu spielen. Das Spiel erfordert Fingerspitzengefühl und ein gutes Verständnis der Grundlagen.
online casino, https://faisal.mssoftsites.com/kiran-child/online-casino-built-for-clean-gaming-experience-9/ delivers a thrilling experience for players seeking adventure. With a variety of choices, users can explore the thrill of scoring from the comfort of their homes.
буроинъекционные сваи усиление фундамента буроинъекционные сваи усиление фундамента .
birxbet giri? birxbet giri? .
1xbet giri? yapam?yorum 1xbet-49.com .
порно на занятии йогой порно на занятии йогой .
1xbet resmi 1xbet-50.com .
1xbet giri? yapam?yorum 1xbet-47.com .
It’s in fact very difficult in this full of activity life to listen news on TV, so I simply use world wide web for that purpose, and take the most up-to-date news.
In the thrilling world of Online Casino Slots, https://h2852162.stratoserver.net/index.php/2026/02/16/duobetz-casino-your-ultimate-gaming-destination-18/, participants can experience diverse themes and exciting gameplay. Utilizing various strategies, participants can maximize their chances of winning big!
Mostbet casino, https://philwebservices.com/wordpress/how-to-download-mostbet-for-seamless-betting/ предлагает широкий выбор азартных игр. Здесь можно найти карт игры и привлекательные бонусы. Пользуйтесь удобным интерфейсом и пробуйте в Mostbet casino!
Klienci chętnie wybierają sufity napinane do mieszkań. Taki wybór pasuje do różnych stylów i układów pomieszczeń. Sufit można połączyć z nową aranżacją lub remontem, co daje estetyczny efekt widoczny od razu https://sufity-napinane-wroclaw.pl/
Nel mondo del gioco online, i casino no KYC Italia, https://fullstoor.com/2026/03/09/i-migliori-casino-senza-documenti-gioca-in/ stanno guadagnando popolaritГ . Detti casino offrono una soluzione di giocare senza richiedere documenti identificativi. I giocatori possono godere di superiore privacy e una partecipazione piГ№ semplice. Successivamente, i casino no KYC Italia consentono transazioni veloci.
Ищете лучшие предложения по интим-аксессуарам? игрушки для взрослых предлагает широкий выбор и быструю доставку.
Качественные изделия с сертификацией минимизируют риски и обеспечивают долговечность и безопасность использования.
Компания центр охраны труда москва обеспечивает полный комплекс мер по предотвращению производственных рисков и соблюдению нормативов безопасности.
Охрана труда является основой безопасного и продуктивного рабочего процесса.
Оценка профессиональных рисков помогает выявить критические зоны и принять меры по их устранению.
Использование технических средств и автоматизированных систем способствует улучшению условий труда и безопасности.
Ответственность работодателя и сотрудника взаимна и должна быть закреплена документально.
Ищете стабильные ролевые сервера для игры? Посетите рп сервера самп — здесь собраны лучшие проекты и подробные обзоры.
На таких серверах каждый может выбрать роль — от простого гражданина до влиятельного криминального авторитета.
online echtgeld roulette, https://dwresourcesdmcc.com/casino-roulette-echtgeld-strategien-und-tipps-fur-5/ ist dem spannenden Glücksspiel. Gamer dürfen spielen und beträchtliche Summen zu erzielen. Solche Plattformen angeboten werden spielerfreundlich, sodass sämtliche Zocker flink beteiligen können.
усиление грунта москва и область usilenie-gruntov-1.ru .
капитальный ремонт здания цена remont-zdaniya-1.ru .
Производитель металлорукавов и рукавов высокого давления из нержавеющей стали предлагает широкий ассортимент продукции для промышленных систем — РВД с фланцами по ГОСТ и ОСТ, гибкие подводки различных диаметров, шаровые краны муфтовые, фланцевые, приварные и трёхходовые. Предприятие производит гибкие рукава с быстроразъёмными соединениями, фланцами из нержавеющей стали, Ст20 либо 09Г2С в соответствии с индивидуальными техусловиями клиента. Ищете гибкие гофрированные трубы из нержавеющей стали? Подробный каталог на iz-medi.ru — здесь представлены гибкие подводки от 1/2 до 2 1/2 дюйма, рукава высокого давления и запорная арматура с возможностью доставки по России. Качественные материалы и соблюдение стандартов гарантируют долговечность и надёжность изделий в эксплуатации.
xbet giri? 1xbet-49.com .
1xbet mobil giri? 1xbet mobil giri? .
1xbet spor bahislerinin adresi 1xbet-47.com .
1 xbet giri? 1xbet-50.com .
секс после йоги секс после йоги .
During the fascinating world of betting casino, https://www.shocoh.co.jp/111049/, players seek chances to obtain massive rewards. Yet, comprehending the strategies is vital for victory.
раскрутка и продвижение сайта раскрутка и продвижение сайта .
продвижение сайта в яндексе омск продвижение сайта в яндексе омск .
Вісті з Полтави – https://visti.pl.ua/ . Новини Полтави та Полтавської області. Довідкова, та корисна інформація про місто.
Scoprire il mondo dei giochi online ГЁ emozionante, e il casino no KYC Italia, https://esli.com.dz/v2/2026/03/09/guida-ai-casino-non-aams-con-prelievo-oggi/ offre opportunitГ uniche. Le utenti possono divertirsi senza complesse verifiche. Questo approccio promette anonimato e velocitГ nel scommettere. Accedere a un casino no KYC Italia ГЁ semplice, basta esplorare gli bonus e vantaggi disponibili.
Formelan gel – gel per uomini molto cercato.
È importante parlare di formelan new. Frequentemente, formelan cos’è viene analizzato come un insieme di possibilità.
In questo articolo analizzeremo formelan effetti
collaterali. L’argomento formelan funziona merita attenzione particolare.
Dove si compra formelan? Gli utenti cercano formelan gel in farmacia.
Va anche detto che formelan amazon sono fonti popolari.
Formelan bufala o funziona davvero? Secondo le recensioni formelan, la
crema sembra efficace per molti.
Formelan come si usa? Formelan composizione contiene principi attivi.
Formelan controindicazioni devono essere considerate prima dell’uso.
In conclusione, formelan new gel rimane un prodotto interessante per gli uomini che desiderano miglioramenti reali.
https://formelan.it/
этапы капитального ремонта этапы капитального ремонта .
seo network prodvizhenie-sajtov-v-moskve15.ru .
Online Casino Games, https://scorpmeds.com/discover-the-exciting-world-of-casino-coins-game-3/ give an exciting way to try your favorite betting activities from home. Players can pick various selections like slots, poker, and blackjack, each offering unique themes.
усиление грунта москва и область usilenie-gruntov-1.ru .
Discover the finest non GamStop casinos where you can enjoy exciting games without restrictions. These venues offer generous bonuses and numerous options of slots and table games, making them perfect for every player. best non GamStop casinos, https://sparkyrecipes.com/exploring-casinos-not-on-gamstop-a-guide-for/ ensure protection while you play.
Mostbet online, https://drink3water.com/onlinecasino20023/discover-mostbet-bd2-your-ultimate-betting/ offers thrilling opportunities for gambling enthusiasts. With a easy-to-navigate interface, players can enjoy a variety of games and sports events. Join now for amazing promotions and bonuses!
секс на тренировке по йоге секс на тренировке по йоге .
Компания оказание услуг по охране труда обеспечивает полный комплекс мер по предотвращению производственных рисков и соблюдению нормативов безопасности.
Каждый сотрудник обязан соблюдать правила и использовать средства индивидуальной защиты.
Периодическое обучение сотрудников способствует снижению числа инцидентов и повышению компетентности.
Современное оборудование требует регулярного обслуживания и контроля состояния.
Работодатель несёт обязанность по созданию безопасной среды и выполнению оценки профессиональных рисков.
Ищете стабильные ролевые сервера для игры? Посетите сервера крмп — здесь собраны лучшие проекты и подробные обзоры.
Такие мероприятия добавляют динамики и заставляют персонажей развиваться в ответ на внешние события.
Ищете лучшие предложения по интим-аксессуарам? секс шоп 24 предлагает широкий выбор и быструю доставку.
Ассортимент включает интимные игрушки, эротическое белье, лубриканты и аксессуары, способствующие усилению удовольствия и сближению партнеров.
Самое полезное для вас: https://parfumabc.ru/parfum/carrement-belle-parfum/
bitcoin betting, https://bigtrakisback.com/betcasino3/casino-with-transparent-bonus-visibility/ has gained quick popularity in recent years, drawing gamblers looking for new ways to place their bets. With digital currency, players enjoy discretion and quick dealings.
лучшие seo агентства лучшие seo агентства .
Узнайте все о криптовалютных бесплатных раздачах, перейдя по ссылке: аэрдроп.
Это процедура бесплатного распространения криптовалютных единиц на множество адресов. Главная цель такой раздачи — привлечь внимание к новому проекту. Данный маркетинговый ход помогает создать широкую базу держателей и усилить интерес.
Для получения токенов пользователям необходимо выполнить ряд условий. Стандартным условием является предварительное внесение адреса своего кошелька в специальный список. Это делает процесс инклюзивным и доступным для новичков. Таким образом, даже неопытные участники рынка могут стать частью экосистемы.
Основные цели эйрдропов носят стратегический характер для разработчиков. Главный замысел — обеспечить демократичное и массовое попадание монет к пользователям. В долгосрочной перспективе это закладывает фундамент для децентрализованного управления. Широко распространенные монеты становятся инструментом для реализации модели DAO.
Со стороны пользователей преимущества также очевидны и многочисленны. Пользователям предоставляется возможность без вложений приобрести перспективные токены. Кроме того, это отличный способ изучить новые технологии на практике. Участие знакомит с функционалом блокчейн-платформ и кошельков.
Не все эйрдропы одинаковы, и их можно классифицировать по нескольким признакам. Стандартный вид акции включает награждение за выполнение элементарных заданий. Более сложный вариант — снапшот-эйрдропы, ориентированные на ранних сторонников. В этом случае токены получают владельцы адресов, сделавшие транзакции до определенной даты.
Механизм распределения всегда прописывается в смарт-контракте для обеспечения прозрачности. Заранее написанная программа беспристрастно вычисляет адреса и количество причитающихся токенов. Это исключает человеческий фактор и возможные злоупотребления. Благодаря этому вся процедура осуществляется автоматически, гарантируя абсолютную справедливость.
Несмотря на привлекательность, участие в раздачах сопряжено с определенными рисками. Ключевая угроза исходит от фейковых инициатив, созданных для обмана пользователей. Злоумышленники часто используют фишинговые сайты для кражи сид-фраз и приватных ключей. Они создают копии официальных страниц, чтобы выманить конфиденциальные данные у жертв.
Для безопасного участия необходимо следовать нескольким важным правилам. Никогда не вводите секретные фразы от своего кошелька на сторонних сайтах. Всегда проверяйте официальные каналы связи проекта и репутацию его разработчиков. Удостоверяйтесь в достоверности сведений, используя надежные криптовалютные площадки и сообщества. Только так можно получить выгоду, не подвергая свои активы опасности. Это единственный способ сохранить средства, участвуя в перспективных бесплатных распределениях.
Надежные каперы телеграмм помогут вам выбирать проверенные прогнозы и избегать мошенников.
Четкие условия предотвращают недоразумения и способствуют долгосрочным отношениям.
щебень гравийный цена за куб подойдет для устройства дорожного основания и отсыпки площадок.
Здесь описываются прочность, плотность и истираемость, которые критичны при выборе щебня.
капперы которым можно доверять отзывы помогут вам выбрать надежных экспертов и избежать мошенников.
Они предоставляют последовательные результаты и честную отчетность по прогнозам.
Критерии выбора капперов включают опыт, прозрачность и управление рисками. Не стоит полагаться лишь на громкие обещания и краткосрочные выигрыши.
Работа с проверенными капперами требует ясного договора и условий сотрудничества. Работа с проверенными капперами требует ясного договора и условий сотрудничества.
Этика и репутация — ключевые факторы долгосрочного сотрудничества с капперами. Они демонстрируют устойчивые результаты и открыто публикуют статистику по пари.
Планируйте выгодные поставки и оформляйте товары из китая оптом для маркетплейсов купить быстрее и надежнее.
Размер страховой премии зависит от стоимости товара, маршрута и выбранной франшизы.
seo компания омск seo компания омск .
Het uitzoeken van het beste online casino buitenland, https://www.fazaa.co/2026/03/06/de-beste-online-casino-s-in-het-buitenland-voor/ biedt uitgebreide mogelijkheden voor spelers. Hier vind je beroemde spellen en aantrekkelijke bonussen. Het is belangrijk om te onderzoeken waar je speelt voor de beste ervaring. Het beste online casino buitenland zorgt voor veiligheid en snelle uitbetalingen.
продвижение в google продвижение в google .
The introduction of new non GamStop casino, http://nb.daqin.cn/index.php/archives/132059 platforms has thrilled players seeking further gambling options. These venues offer original experiences, ensuring greater freedom and selection in gaming. Join the exciting world today!
Online Casino, https://immobilienhamburg.eu/2026/02/16/experience-thrilling-gaming-adventures-at-casino-2/ presents a range of gambling experiences for gamblers to experience. Featuring exciting visuals, it ensures an enthralling experience like no other.
Mostbet casino, https://tentakle.com/?p=530342 предлагает разнообразные игровые опции, включая слоты, рулетка и спортивные события. Клиенты могут наслаждаться захватывающей атмосферой и выигрывать щедрые призы. Входите и узнайте мир азартных игр!
раскрутка сайта франция prodvizhenie-sajtov-v-moskve15.ru .
заказать продвижение сайта омск заказать продвижение сайта омск .
Het selecteren het beste online casino buitenland is een spannende taak voor veelvuldig spelers. Je vindt veel keuzes, maar het beste keuze vraagt aandacht voor veiligheid. Het is cruciaal om de aandacht te vestigen op toezicht, ondersteuning en promoties. Feedback van andere spelers zijn waardevol bij het maken van de juiste keuze. Met de ideale informatie is het mogelijk het beste online casino buitenland, https://rockwoodhealthcare.com/index.php/2026/03/06/casino-zonder-verificatie-gemakkelijk-en-snel/ voor jouw vermaak.
In recent years, sports betting, https://conectasanjose.com/online-casino-designed-for-clear-gaming-experience/ has witnessed increased attention. Countless supporters are now looking for strategies to enhance their profitability.
non GamStop websites, https://informaciondecontacto.lalolaapp.com/discover-new-casinos-not-on-gamstop-545009847/ offer a different gaming experience. Players can appreciate a broad range of selections without the constraints of traditional platforms. Explore these sites for captivating opportunities.
net seo net seo .
Узнайте все о криптовалютных бесплатных раздачах, перейдя по ссылке: эйрдроп что это.
Оно обозначает бесплатную раздачу токенов или монет большому числу кошельков. Главная цель такой раздачи — привлечь внимание к новому проекту. Мероприятие позволяет быстро расширить аудиторию и повысить узнаваемость бренда.
Для получения токенов пользователям необходимо выполнить ряд условий. Обычно нужно выполнить несложные задания, например, подписаться на соцсети проекта. Это делает процесс инклюзивным и доступным для новичков. Таким образом, даже неопытные участники рынка могут стать частью экосистемы.
Основные цели эйрдропов носят стратегический характер для разработчиков. Ключевая миссия заключается в честном и широком распространении активов проекта. В долгосрочной перспективе это закладывает фундамент для децентрализованного управления. Разошедшиеся по рукам активы дают право сообществу влиять на ключевые решения.
Со стороны пользователей преимущества также очевидны и многочисленны. Люди обретают шанс бесплатно стать владельцами цифровых единиц, цена которых может вырасти. Кроме того, это отличный способ изучить новые технологии на практике. Процесс помогает на собственном опыте понять принципы работы криптографических систем.
Не все эйрдропы одинаковы, и их можно классифицировать по нескольким признакам. Стандартный вид акции включает награждение за выполнение элементарных заданий. Более сложный вариант — снапшот-эйрдропы, ориентированные на ранних сторонников. Здесь награду распределяют среди кошельков, проявивших активность в заданный период.
Механизм распределения всегда прописывается в смарт-контракте для обеспечения прозрачности. Заранее написанная программа беспристрастно вычисляет адреса и количество причитающихся токенов. Это исключает человеческий фактор и возможные злоупотребления. Благодаря этому вся процедура осуществляется автоматически, гарантируя абсолютную справедливость.
Несмотря на привлекательность, участие в раздачах сопряжено с определенными рисками. Ключевая угроза исходит от фейковых инициатив, созданных для обмана пользователей. Злоумышленники часто используют фишинговые сайты для кражи сид-фраз и приватных ключей. Мошенники разрабатывают поддельные ресурсы, целью которых является получение доступа к кошелькам.
Для безопасного участия необходимо следовать нескольким важным правилам. Никогда не вводите секретные фразы от своего кошелька на сторонних сайтах. Всегда проверяйте официальные каналы связи проекта и репутацию его разработчиков. Удостоверяйтесь в достоверности сведений, используя надежные криптовалютные площадки и сообщества. Только так можно получить выгоду, не подвергая свои активы опасности. Это единственный способ сохранить средства, участвуя в перспективных бесплатных распределениях.
топ капперов помогут вам выбрать надежных экспертов и избежать мошенников.
Надежные капперы прошли строгий процесс оценки и отсева.
Критерии выбора капперов включают опыт, прозрачность и управление рисками. Важно проверять архивы прогнозов и результаты за длительный период.
Работа с проверенными капперами требует ясного договора и условий сотрудничества. Взаимодействие с надежными капперами должно быть оформлено прозрачными условиями.
Этика и репутация — ключевые факторы долгосрочного сотрудничества с капперами. Взаимодействие с надежными капперами должно быть оформлено прозрачными условиями.
seo продвижение рейтинг компаний seo продвижение рейтинг компаний .
Надежные проверенные капперы помогут вам выбирать проверенные прогнозы и избегать мошенников.
Качественный каппер демонстрирует честную и подтверждаемую историю своих прогнозов.
щебень гравийный купить в москве подойдет для устройства дорожного основания и отсыпки площадок.
Планирование и контроль на всех этапах работ — залог успешного применения щебня.
Планируйте выгодные поставки и оформляйте 1688 товары из китая оптом быстрее и надежнее.
Выбор оптимального маршрута зависит от срочности, стоимости и характера груза, а также от текущей геополитической обстановки.
сделать аудит сайта цена prodvizhenie-sajtov-v-moskve15.ru .
Нужна срочная печать визиток, листовок или сувенирной продукции в Москве? Типография ПоВсёюДо работает в режиме 24/7 и выполняет заказы любой сложности — от простых визиток до эксклюзивных кашированных папок и брендированных кубиков-Рубика. Профессиональное оборудование и опытные специалисты гарантируют высокое качество печати при доступных ценах. Оформить заказ можно на сайте https://povsyoudo.ru/, где представлен полный каталог услуг с удобным калькулятором стоимости. Быстрая доставка по Москве и области, помощь дизайнера и гибкая ценовая политика — всё для вашего бизнеса.
In the world of Casino Online, http://www.shitara-trail.jp/%e6%9c%aa%e5%88%86%e9%a1%9e/139506.html, players are able to find a selection of games that offer entertainment and excitement. Starting with classic slots to interactive dealer experiences, there’s something for every gamer. Additionally, the convenience of gambling from home makes Casino Online a popular choice among fans. So, consider it today?
To start playing, complete the Mostbet register, https://puertadelsolsanblas.com.ar/understanding-the-importance-of-trustpilot-reviews-3/ process. Choose a simple approach to register. Provide your details and enjoy thrilling games. Don’t miss out on great bonuses!
De zoektocht naar het beste online casino buitenland, https://www.epione.org/2026/03/06/buitenlandse-casino-betrouwbaarheid-hoe-te-kiezen/ zal uitdagend voor veel gokkers. In een beste online casino’s vind je veel spellen en bonussen. Tevens zorgen veiligheidsmaatregelen ervoor dat jouw informatie veilig zijn. Ervaar het portfolio en de perfecte promoties.
In the world of online gaming, players often seek options that provide them with an exciting experience. One of the best options available is sites not on GamStop, https://www.alffastener.de/index.php/2026/03/09/best-non-gamstop-casinos-uk-a-comprehensive-guide-2/. These venues offer enhanced gaming opportunities, allowing users to partake in their favorite games without the constraints imposed by GamStop. Whether you’re looking for virtual sports, these sites cater to all interests, ensuring a thrilling adventure for every player.
христианская реабилитация наркоманов алматы
Тщательная оценка состояния пациента необходима для разработки индивидуального плана лечения.
Работа с семьей пациента помогает создать поддерживающую среду дома и уменьшить стрессовые факторы.
Продолжение участия в поддерживающих инициативах способствует сохранению трезвого образа жизни.
Комплексная профилактика с регулярным сопровождением снижает вероятность повторной зависимости.
Хоть убей, не знаю.
купить квартиру в москве, https://www.sarajulez.de/kvartiry-s-otdelkoj-i-mebelju-idealnyj-vybor-dlja-3/ – это важный шаг. Выбор жилья требует строгости. Покупка недвижимости – этот шаг для улучшения жизни. Рассмотрите свои финансовые возможности, чтобы осилить лучший объект. Москва предлагает широкий ассортимент вариантов недвижимости.
In the world of cryptocurrency, the rise of the crypto casino, https://primusurbanismo.com.br/blog/exploring-functional-design-in-online-casino-3/ has changed the way we gamble. Players can enjoy exciting games while benefiting from instant deposits. With anonymity as a key feature, enjoying a crypto casino is now more accessible than ever!
интернет продвижение москва prodvizhenie-sajtov-v-moskve15.ru .
Ознакомьтесь с услугами по заказать алкоголь с доставкой москва для быстрой и удобной доставки алкоголя в Москве.
В последние годы спрос на эту услугу значительно вырос.
Такой подход освобождает от необходимости ездить в торговые точки.
Подберите подходящий метод расчета среди доступных опций.
Сервис по доставке спиртного облегчает рутину для большого количества индивидов.
заключить контракт на сво в волгограде
Детализация платежных условий помогает сторонам планировать бюджет и избегать задержек с оплатой.
подростковый алкоголизм алматы поможет быстро и безопасно организовать качественный вывод из запоя в Алматы.
Профессиональная детоксикация включает введение препаратов, восполнение электролитов и наблюдение за показателями жизнедеятельности.
Как отформатировать usb флешку на андроид пошаговая инструкция
Рекомендую Вам поискать сайт, где будет много статей на интересующую Вас тему.
розмальовки для дітей, https://trade-britanica.trade/wiki/User:WZWRudolph — це чудовий спосіб розвинути творчі навички малечі. Подібний вид діяльності сприяє дітям успішно проводити час, внаслідок того, що малювання послаблює стрес і покращує концентрацію. Включаючись у світ кольорів, дошкільнята можуть випробовувати з різними відтінками та техніками. Яскраві малюнки заохочують малечі виражати себе та створювати власний стиль. Крім того розмальовки справляються корисними для розвитку рухової активності, адже створення потребує ліпшої уважності. Залучення дітей до таких видів активності підтримує формуванню креативності в майбутньому. Розмальовки для дітей — це не лише розвага, але і важливий елемент навчання та розвитку. І попри те що сучасних технологій, звичні розмальовки залишаються актуальними.
internetagentur seo internetagentur seo .
Het kiezen van het beste online casino buitenland, https://kevinintveld.com/klarna-online-casino-gemak-en-veiligheid-voor/ kan lastig zijn. Belangrijk is om een betrouwbare site te vinden, met eerlijke spelregels en vriendelijke bonussen. Het beste online casino buitenland verstrekt ook bescherming voor spelers.
ремонт в ванной цена ремонт ванны комнаты ключ
продвижение сайтов в москве prodvizhenie-sajtov-v-moskve15.ru .
Playing Casino Online Slots, https://shop.spipublications.in/experience-the-thrill-of-coincasino-uk-your/ gives an exciting way to win large jackpots. Using multiple themes and designs, players can readily find a game that fits their preferences. Enjoy the experience from your own home while having an enjoyable experience.
Exploring the latest casinos can be exciting, especially when considering new casinos not on GamStop, https://www.outdoorspecialist219.com/non-gamstop-casinos-a-comprehensive-guide-to/. These platforms offer unique experiences, delivering various gaming options. Players discover currently a more extensive selection of variations, often with profitable bonuses and promotions. With a focus on user choice, these casinos offer a new alternative to traditional gaming sites.
The Mostbet app, https://www.bikerentalbali.com/how-to-download-mostbet-for-easy-online-betting/ offers a seamless experience for bettors, combining user-friendly design with a wide range of options. Users can enjoy in-play wagering, enhanced by real-time alerts. With the Mostbet app, placing bets becomes hassle-free. Enjoy your favorite sports and unique bonuses directly on your mobile device. This app truly enhances the way you engage with sports betting.
заказать анализ сайта заказать анализ сайта .
Безусловно, он прав
Чтобы достичь цели, вам понадобятся надежность. рецепты вашего успеха, https://farmstofoodbank.com/cam-xanh-nghia-tinh-mo-hinh-nong-nghiep-se-chia/ заключаются в постоянной работе над собой и соблюдении плана. Каждый из шагов важен, поэтому не пренебрегайте возможность учиться и расти.
A attractive casino bonus, https://stayhome.palwakf.ps/betcasino2/controlled-gaming-the-future-of-online-casinos/ can enhance your gaming experience. Users often search for various promotions to maximize their odds. Rewards come in different forms, such as free spins or deposit matches. Grab advantage of these offers and gain extended playtime.
снятие опиатной ломки алматы
Проведение детоксикации в стационаре под контролем специалистов снижает вероятность осложнений.
Семейная терапия возвращает доверие и восстанавливает взаимоотношения между близкими.
Наличие долгосрочной поддержки и участия в группах взаимопомощи уменьшает вероятность возврата к употреблению.
Профилактика рецидивов требует комплексного плана и регулярного мониторинга состояния пациента.
заказать продвижение сайта в москве заказать продвижение сайта в москве .
Вы правы, в этом что-то есть. Благодарю за информацию, может, я тоже могу Вам чем-то помочь?
non GamStop horse racing, http://www.univ-bouira.dz/seminaire/exploring-horse-racing-sites-not-on-gamstop/ offers a unique experience for bettors. Including a variety of options, enthusiasts can appreciate thrilling races without the usual restrictions. These events are perfect for those seeking liberty in their wagering.
Het kiezen van het beste online casino buitenland, https://seocheckertools.net/blog/betrouwbare-online-casino-s-in-het-buitenland-159/ is essentieel voor een uitstekende spelervaring. Veel liefhebbers willen naar goede platforms. Voordelen kunnen ook nog cruciaal zijn om het speelplezier te uitbreiden. Vergeet niet om doordacht te spelen!
non GamStop sites, https://parquepuntadevacas.net/wp/exploring-uk-casinos-not-on-gamstop-a-2/ provide a great alternative for players looking to indulge in online gaming without barriers. These platforms facilitate seamless access to numerous games and promotions. Players can discover a broad array of options, making it simpler to find their preferred sort of entertainment.
продвижение сайта франция продвижение сайта франция .
продвижение в google продвижение в google .
Для стройки, производства и монтажа шестигранные гайки ценят за практичность, удобный подбор и стабильное качество поставки Это удобно для регулярных поставок и серийной сборки: анкерные болты оптом
компании занимающиеся продвижением сайтов компании занимающиеся продвижением сайтов .
многоуровневый линкбилдинг seo-kejsy17.ru .
Participating in Casino Online Games, https://zouzhun.com/215932.html has become incredibly popular. Players can discover a wide range of dynamic games from the luxury of their homes. With fantastic graphics and intuitive interfaces, online casinos attract players worldwide.
I am curious to find out what blog system you have been using? I’m having some minor security issues with my latest blog and I would like to find something more safeguarded. Do you have any suggestions?
Mostbet download, https://steamindonesia.id/discover-the-elegance-of-diamonds-at-diamond-9/ is a seamless process that offers users easy access to their favorite betting platform. Using the app, bettors can place wagers on events anytime and anywhere. Take advantage of on-the-go betting options with just a few taps.
Закажите доставка алкоголя круглосуточно круглосуточно и с удобной оплатой!
Доставка алкоголя становится все более популярной услугой в современном мире .
Благодаря интернету подобные сервисы эволюционируют в ускоренном темпе.
Нет необходимости выходить из дома для покупки излюбленных напитков .
Еще одним бонусом становится опция анализа цен и промоакций.
Потом зафиксируйте отбор в корзине .
Укажите точный локейшн и удобное время для доставки.
Она прекрасно вписывается в праздники или моменты отдыха .
Оформляйте заказы лишь в надежных компаниях .
Прямо в яблочко
изделия из дерева, https://www.geestdriftfestival.nl/kaartverkoop-geestdrift-festival-gestart/ | деревянные изделия | изделия из древесины | деревянные предметы привносят уют в любой интерьер. Они | Эти предметы | Деревянные вещи | такие уникальные, что способны украсить любое пространство. Помимо эстетики, они | также | вместе с тем | кроме того, обеспечивают долговечность и прочность.
Ознакомьтесь с услугами по алкоголь 24 часа для быстрой и удобной доставки алкоголя в Москве.
В последние годы спрос на эту услугу значительно вырос.
Из-за этого пользователи имеют шанс приобрести эксклюзивные виды напитков.
Оформите аккаунт, предоставив актуальные сведения.
Рекомендуем выбирать лицензированные сервисы для минимизации рисков.
усиление ссылок переходами усиление ссылок переходами .
online casino, http://wp.playhudong.com/%e5%b8%ae%e5%8a%a9%e4%b8%ad%e5%bf%83/online-casino-built-for-stability-your-safe/ provides a thrilling experience for players. With multiple games and bonuses, it lures many enthusiasts. Participate in the fun and try your luck today!
seo agencies ranking seo agencies ranking .
Het kiezen van het beste online casino buitenland kan een strijd zijn. Er zijn veel opties, maar weinig enkele bieden secure spelomgevingen. Zoek voor goede reviews en kortingen. Het is belangrijk om voor letten op service en betalingsopties. Kies doordacht en geniet van het beste online casino buitenland, https://elin.lindemediamusik.se/2026/03/06/casino-paysafecard-veilig-en-anoniem-spelen-in/.
сво контракт сколько
В договоре желательно указать процедуры мониторинга исполнения и способы урегулирования конфликтов.
Мне кажется, что это уже обсуждалось, воспользуйтесь поиском по форуму.
Un casino depot 10 euros, casino en ligne depot 10 euros met Г disposition une expГ©rience de jeu exceptionnelle. ГЂ l’aide de ce montant, les parieurs peuvent dГ©couvrir diffГ©rents divertissements. C’est super pour les passionnГ©s souhaitent s’initier sans investir trop.
вывод из запоя в стационаре круглосуточно астана недорого
Вывод из запоя в Астане требует профессионального подхода и внимательного отношения к пациенту.
Комбинация медикаментов и внутривенных вливаний помогает предупредить опасные осложнения и стабилизировать состояние.
Следующий шаг — оценка психического состояния и разработка персонализированной программы восстановления.
Реабилитация завершается созданием долгосрочного плана поддержки и контроля после выписки.
non GamStop casino sites, http://www.pisarevo.com/exploring-non-gamstop-casinos-a-gateway-to-2/ offer players a possibility to enjoy gambling without the restrictions imposed by GamStop. Such sites have a wide range that meet the needs of diverse player preferences.
Поздравляю, ваша мысль просто отличная
Playing online can be thrilling, especially with options like bingo not on GamStop, http://arisaraldalecumplimos.risaralda.gov.co/index.php/2026/02/17/discovering-online-bingo-sites-not-on-gamstop-2/. These sites offer an experience free from restrictions, allowing players to enjoy their favorite games. Explore numerous platforms where you can find remarkable bingo variants and lucrative bonuses.
раскрутка сайта москва раскрутка сайта москва .
сделать аудит сайта цена сделать аудит сайта цена .
seo клиники наркологии seo клиники наркологии .
seo partners seo partners .
[url]https://www.radiostres.com/user/Michal6378/[/url]
Playing at online casinos offers an exciting way to explore games anytime. Casino Online, https://academiadeseguridadaessltda.com/explore-the-exciting-world-of-casobet-casino-34/ provides multiple options, from slots to table games, ensuring entertainment for everyone. Join today!
Нужен быстрый заказ для вечеринки? Заказывайте доставка алкоголя 24 прямо сейчас — быстро, удобно и с гарантией качества.
Контроль за сохранением температуры и целостности упаковки помогает сохранять свойства алкогольной продукции.
Узнайте все о криптовалютных бесплатных раздачах, перейдя по ссылке: что такое airdrop.
Под этим термином понимают безвозмездное распределение цифровых активов среди пользователей. Главная цель такой раздачи — привлечь внимание к новому проекту. Мероприятие позволяет быстро расширить аудиторию и повысить узнаваемость бренда.
Для получения токенов пользователям необходимо выполнить ряд условий. Часто требуется просто зарегистрироваться на платформе и иметь активный кошелек. Это делает процесс инклюзивным и доступным для новичков. Следовательно, минимальные требования дают шанс каждому пополнить свой портфель.
Основные цели эйрдропов носят стратегический характер для разработчиков. Главный замысел — обеспечить демократичное и массовое попадание монет к пользователям. В долгосрочной перспективе это закладывает фундамент для децентрализованного управления. Распределенные токены в будущем позволяют держателям участвовать в голосованиях.
Со стороны пользователей преимущества также очевидны и многочисленны. Люди обретают шанс бесплатно стать владельцами цифровых единиц, цена которых может вырасти. Кроме того, это отличный способ изучить новые технологии на практике. Участие знакомит с функционалом блокчейн-платформ и кошельков.
Не все эйрдропы одинаковы, и их можно классифицировать по нескольким признакам. Стандартный вид акции включает награждение за выполнение элементарных заданий. Более сложный вариант — снапшот-эйрдропы, ориентированные на ранних сторонников. При таком подходе монеты передаются пользователям, которые взаимодействовали с сетью заранее.
Механизм распределения всегда прописывается в смарт-контракте для обеспечения прозрачности. Автоматизированный код самостоятельно определяет список получателей и объем выплат. Это исключает человеческий фактор и возможные злоупотребления. Таким образом, процесс проходит объективно, без риска манипуляций со стороны команды.
Несмотря на привлекательность, участие в раздачах сопряжено с определенными рисками. Главная опасность — это многочисленные мошеннические схемы, маскирующиеся под легитимные проекты. Злоумышленники часто используют фишинговые сайты для кражи сид-фраз и приватных ключей. Аферисты дублируют настоящие веб-адреса, чтобы завладеть секретной информацией пользователей.
Для безопасного участия необходимо следовать нескольким важным правилам. Ни при каких обстоятельствах не сообщайте приватные ключи или мнемонические фразы. Всегда проверяйте официальные каналы связи проекта и репутацию его разработчиков. Проводите перекрестную проверку информации в известных социальных сетях и специализированных СМИ. Только так можно получить выгоду, не подвергая свои активы опасности. Лишь такой подход позволяет обезопасить капитал при работе с подобными маркетинговыми акциями.
Mostbet online, https://fawesomegames.com/your-ultimate-destination-for-automotive/ offers an exciting platform for sports betting and gaming. Users can enjoy a choice of games and tournaments. Its accessible interface makes betting simple and fun for everyone.
W polsce kasyno, https://www2.uesb.br/cultura/?p=44792 zyskuje coraz wiД™kszД… popularnoЕ›Д‡, nawet w regionach duЕјych. Zabawy przyciД…gajД… graczy, amatorzy adrenaliny oraz emocji. Instytucje oferujД… unikalne doЕ›wiadczenia, a wiele paЕ„stwowego nadzoru zapewnia bezpieczeЕ„stwo graczy.
Вы не правы. Предлагаю это обсудить. Пишите мне в PM.
Les joueurs en ligne adorent les offres de cadeaux. Parmi elles, le free spin sans depot, free spins sans depot est trГЁs apprГ©ciГ©. Ceci donne de tenter sa chance sans engagement financier. Les plateformes de jeux en ligne mettent Г disposition rГ©guliГЁrement ces avantages. Saisissez de ces occasions pour gagner des gains sans risquer votre argent.
Согласен, замечательная штука
Агрегатор онлайн-курсов, https://www.togmanali.com/blog/dont-let-these-hotel-booking-missteps-spoil-your-trip-to-manali/ позволяет запустить обучение в разнообразных областях. Вы можете определить курсы по интересам и рассмотреть отзывы. Это удобно для всех желающих постигнуть новые навыки.
многоуровневый линкбилдинг seo-kejsy17.ru .
In the thrilling world of betting, a betting casino, https://www.smittelecom.nl/index.php/revolutionizing-gambling-a-casino-platform-focused/ offers a unique experience. Players look for excitement and possibility. With several games, the atmosphere is always electric, promising excitement.
Если вы хотите узнать подробности о контракт сво новгород, переходите по ссылке.
Подписание контракта на СВО в Нижнем Новгороде связано с необходимостью четкого регламентирования работ и ответственности.
Важно согласовать форму актов, сроки их подписания и ответственность за задержки.
Это особенно важно при передаче технической документации и коммерческих данных.
В контракте следует предусмотреть порядок изменения и расторжения договора.
отзывы о лечении наркомании алматы
Тщательная оценка состояния пациента необходима для разработки индивидуального плана лечения.
Когнитивно-поведенческие техники способствуют уменьшению рецидивного поведения и укреплению мотивации.
Продолжение участия в поддерживающих инициативах способствует сохранению трезвого образа жизни.
Комплексная профилактика с регулярным сопровождением снижает вероятность повторной зависимости.
Many players seek alternative gaming options, which is why casinos not on GamStop, https://www.ameeralbaher.com/exploring-casinos-not-using-gamstop-a-3/ are gaining traction. These platforms offer exclusive experiences, allowing users to enjoy their favorite games without restrictions.
комплексное продвижение сайтов москва комплексное продвижение сайтов москва .
seo agency ranking reiting-seo-kompaniy.ru .
продвижения сайта в google продвижения сайта в google .
заказать продвижение сайта в москве заказать продвижение сайта в москве .
концовка предсказуема с самого начала
non GamStop bookies, https://integrasoftcr.com/bomberhistory/exploring-non-gamstop-sports-betting-sites-a-13-2/ offer bettors a chance to enjoy their favorite games without restrictions. Many players are looking for various options, and these platforms offer a great solution. Experience a broad range of gaming choices and engaging betting opportunities with non GamStop bookies.
Блестящая идея
DГ©couvrez l’excitation des jeux en ligne grГўce au casino bonus de bienvenue, casino en ligne avec bonus de bienvenue. Cet promotionnelle vous permet de jouer sans risquer votre argent. En profitant de ces incitations, vous pouvez maximiser vos gains et tester de nouveaux jeux passionnants. Profitez-en maintenant et jouez dГЁs aujourd’hui pour profiter de cette occasion unique.
ватные игрушки на заказ, https://disabilityinfo.am/758153/ — это уникальные изделия, которые могут стать прекрасным подарком. Подобные изделия дарят счастье и создают атмосферу праздника. Заказывая индивидуальные игрушки, вы получите нечто, что оставит яркие эмоции. Каждый фрагмент сделан с заботой, что делает каждый товар неповторимым.
seo эксперт агентство reiting-seo-kompanii.ru .
In recent years, the rise of casinos that dont use GamStop, https://shop.grubin.rs/discover-the-best-casinos-outside-gamstop/ has attracted considerable attention. Players are seeking for alternatives that allow them to enjoy gaming without limitations. These casinos can provide distinct experiences for those hoping to play without interference.
Online Casino, http://uclab.khu.ac.kr/LeanUX/2026/02/15/experience-thrilling-gaming-and-betting-at-cazeus/ – Virtual Casino — это времяпрепровождение для миллионов людей. Множество РёРіСЂ доступны РЅР° платформах, включая рулетку. Каждый желающий может наслаждаться уникальными эмоциями, участвуя РІ увлекательных турнирах Рё покорять РїСЂРёР·С‹.
продвижение сайтов интернет магазины в москве продвижение сайтов интернет магазины в москве .
интернет агентство продвижение сайтов сео интернет агентство продвижение сайтов сео .
По моему мнению Вы ошибаетесь. Могу отстоять свою позицию. Пишите мне в PM, обсудим.
Туристический портал, https://www.cadproducts.nl/product/autocad-lt-1-jaar-abonnement-mac/ предлагает впечатляющие маршруты по минутам городам мира. Здесь вы найдете подробные описания мест, размышления путешественников и безусловно полезные советы для планирования поездок.
Mostbet casino, http://www.brouilette.com/archives/187816 представляет игрокам широкий количество игр. Вы можете исследовать лотереи и карточные игры. Скидки привлекают новых участников.
bitcoin betting, https://thesellingmatrix.com/discover-the-best-online-casino-offering-both-2/ has become more popular among gamblers. This novel approach allows users to gamble using cryptocurrency, offering speedy transactions and increased confidentiality. As the industry grows, favorable odds attract more players, leading to a thriving market. With the right strategies, participants can maximize their winnings.
internetagentur seo internetagentur seo .
Узнайте все о криптовалютных бесплатных раздачах, перейдя по ссылке: аирдроп это.
Оно обозначает бесплатную раздачу токенов или монет большому числу кошельков. Главная цель такой раздачи — привлечь внимание к новому проекту. Мероприятие позволяет быстро расширить аудиторию и повысить узнаваемость бренда.
Для получения токенов пользователям необходимо выполнить ряд условий. Часто требуется просто зарегистрироваться на платформе и иметь активный кошелек. Это делает процесс инклюзивным и доступным для новичков. Следовательно, минимальные требования дают шанс каждому пополнить свой портфель.
Основные цели эйрдропов носят стратегический характер для разработчиков. Ключевая миссия заключается в честном и широком распространении активов проекта. В долгосрочной перспективе это закладывает фундамент для децентрализованного управления. Широко распространенные монеты становятся инструментом для реализации модели DAO.
Со стороны пользователей преимущества также очевидны и многочисленны. Пользователям предоставляется возможность без вложений приобрести перспективные токены. Кроме того, это отличный способ изучить новые технологии на практике. Это дает практические навыки взаимодействия с децентрализованными приложениями.
Не все эйрдропы одинаковы, и их можно классифицировать по нескольким признакам. Стандартный вид акции включает награждение за выполнение элементарных заданий. Более сложный вариант — снапшот-эйрдропы, ориентированные на ранних сторонников. В этом случае токены получают владельцы адресов, сделавшие транзакции до определенной даты.
Механизм распределения всегда прописывается в смарт-контракте для обеспечения прозрачности. Заранее написанная программа беспристрастно вычисляет адреса и количество причитающихся токенов. Это исключает человеческий фактор и возможные злоупотребления. Следовательно, система работает самостоятельно, минимизируя возможность чьего-либо вмешательства.
Несмотря на привлекательность, участие в раздачах сопряжено с определенными рисками. Основной риск связан с обилием скам-проектов, которые имитируют честные кампании. Злоумышленники часто используют фишинговые сайты для кражи сид-фраз и приватных ключей. Они создают копии официальных страниц, чтобы выманить конфиденциальные данные у жертв.
Для безопасного участия необходимо следовать нескольким важным правилам. Никогда не вводите секретные фразы от своего кошелька на сторонних сайтах. Всегда проверяйте официальные каналы связи проекта и репутацию его разработчиков. Проводите перекрестную проверку информации в известных социальных сетях и специализированных СМИ. Только так можно получить выгоду, не подвергая свои активы опасности. Лишь такой подход позволяет обезопасить капитал при работе с подобными маркетинговыми акциями.
Нужен быстрый заказ для вечеринки? Заказывайте как купить алкоголь с доставкой на дом прямо сейчас — быстро, удобно и с гарантией качества.
Доставка алкоголя стала неотъемлемой частью городской жизни, облегчая покупку напитков в любое время суток.
Если вы хотите узнать подробности о подписать контракт сво, переходите по ссылке.
Рекомендуется детально проанализировать условия и проконсультироваться со специалистом по контрактам.
Наличие оговорки о форс-мажоре снизит риск конфликтов при чрезвычайных ситуациях.
Важно согласовать минимальные лимиты страхового покрытия и период его действия.
В контракте полезно определить способ разрешения конфликтов и применимое право.
Поживем.
non GamStop bookmakers, https://www.thanreboucas.com.br/exploring-non-gamstop-bookmakers-a-comprehensive-7-2/ are gaining popularity among players looking for more flexibility. Such betting sites provide various selections for wagering. Users can enjoy expanded limits and minimal restrictions. It makes non GamStop bookmakers a great choice for fans.
Да так не чё. Хотя …….
Les portes de la mythologie s’ouvrent pour dГ©voiler des trГ©sors incroyables. Dans ce royaume mythique, chaque choix peut mener Г des rГ©compenses colossales. Les explorateurs ressentent l’excitation Г chaque spin et espГЁrent triompher. gates of olympus, gates of olympus offre une expГ©rience inoubliable!
фрибет за регистрацию, https://kosmetologi-shop.ru/2026/03/03/gde-luchshie-fribety-rukovodstvo-po-vyboru/ дает отличную возможность активировать бонусы в букмекерских конторах. Это промо-акция позволяет заявлять средствами для ставок. Плюсы такой активации заключаются в росте шансов на успех. Главное — правильно найти букмекерскую контору, которая обещает лучший фрибет за регистрацию.
Finding the best non GamStop casinos, https://macula-systems.com/casino-sites-without-gamstop-discover-your-options/ is essential for players seeking great experiences. These online platforms offer engaging games without restrictions. Users can enjoy varied options, from slots to table games, staying entertained. Additionally, offers enhance gameplay, attracting many users.
seo продвижение рейтинг reiting-seo-kompanii.ru .
ахревс ахревс .
заказать продвижение сайта в москве заказать продвижение сайта в москве .
Online Casino Slots, https://fauzinfotec.com/index.php/2026/02/15/yeti-win-casino-sportsbook-your-ultimate-gaming-7/ provide an exciting chance to win big. With lively graphics and entertaining gameplay, players can enjoy a variety of themes and styles. Whether you’re a recreational player or a serious gambler, there’s something for everyone! Discover your favorite slot and let the fun begin!
ghbdtn привет
Согласен, это забавное сообщение
Amid the vast world of web-based trading, pocket option trading, https://thefreeadforum.top/index.php?page=item&id=287817 stands out as a trendy choice for both rookies and experienced traders. This application offers a accessible interface that facilitates users to take part in various trading activities with comfort. The diversity of assets available for trading is striking, including forex and crypto assets.Moreover, pocket option trading provides educational resources to help traders enhance their skills. Workshops and resources are available to support users in realizing the complexities of the market. Furthermore, participants can take advantage of the simulation account feature, which allows them to train their strategies without financial risk.As pocket option trading can offer profits, it is essential for users to understand the inherent risks and trade responsibly. The environment can be volatile, and staying educated is crucial for achievement in this exciting arena.
sports betting, https://igrejaapascentardedeus.com.br/online-casino-built-for-practical-players-5/ – Sports betting has become increasingly popular among fans. The thrill of placing a bet adds excitement to the game. However, knowing the odds is crucial for profitability.
mostbet casino, http://www.aprendaavoar.com.br/?p=542937 offers an exciting gaming experience for participants. Here, you can enjoy a wide variety of games, including slots and casino classics. Join now to make your fortune!
локальное seo блог локальное seo блог .
курсы визажа для себя, http://portal.tomintech.ru/kak-stat-sam-sebe-vizazhistom-v-moskve/ помогут вам освоить тексты макияжа, оформить идеальный образ. Вы познакомитесь с различными косметических средств и хитростями профессионалов.
Explore the new one here > https://medtronik.ru/
where internet partner prodvizhenie-sajtov-po-trafiku11.ru .
Вы ошибаетесь. Давайте обсудим это. Пишите мне в PM, пообщаемся.
non GamStop sportsbooks, https://sbcj3.websiteseguro.com/bomberhistory/understanding-non-gamstop-bookmakers-a-2/ deliver a diversity of betting options for players. With appealing odds and unique promotions, they enthrall sports enthusiasts looking for further opportunities.
топ диджитал агентств россии топ диджитал агентств россии .
In the dynamic world of online gaming, the new non GamStop casino, https://www.southerngospelconcert.com/top-casinos-not-on-gamstop-your-ultimate-gaming/ offers players liberty without restrictions. This platform ensures a unique experience where you can enjoy preferred games without limitations. Discover exceptional entertainment today!
каталог seo агентств каталог seo агентств .
seo top 1 seo top 1 .
реклама наркологической клиники реклама наркологической клиники .
сео агентство сео агентство .
да да да привет привт
По всей вероятности. Скорее всего.
crazy time casino, http://beadesign.cz/gallery-slider/ offers an exciting gaming experience. Players can try out a variety of different games. The energetic atmosphere enhances the full adventure. Don’t miss out on the chance to win big!
In the world of virtual gaming, Online Casino Games, https://raphaelmortgageguy.com/exploring-twister-wins-your-guide-to-big-wins-in/ offer an exciting opportunity for players. With various choices, from slots to poker, gamers can test their strategies and win big. The thrill of chance and the potential for rewards keep enthusiasts coming back.
In the world of digital gambling, a crypto casino, http://www.fidadoc.org/online-casino-with-clear-verification-a-safe/ stands out for its secure transactions using digital currencies. Players enjoy anonymity while accessing a variety of engaging games. The potential to win big attracts many enthusiasts.
Аппараты для сварки оптоволокна, https://pdd8ryabinka.68edu.ru/2026/03/04/revoljucija-promyshlennyh-robotov-budushhee/ помогают создавать надежные соединения. Эти устройства обеспечивают высокое качество сварки, что критично для стабильной работы сетей. Передовые модели имеют простой интерфейс для простоты использования. При выборе аппарата стоит анализировать его характеристики и производительность.
Mostbet sports, https://gulfauto.qa/2026/02/26/experience-the-thrill-of-online-gaming-with-2/ offers various betting options for followers of different sports. Discover current events and experience competitive odds that enhance your chances of winning.
non GamStop websites, https://modastiley.mdc.org.co/exploring-the-world-of-new-online-casinos-not-on/ offer a unique gaming experience for those desiring more freedom. Players can enjoy various choices without restrictions. These sites serve players who wish to find more diverse opportunities.
статьи про маркетинг и seo статьи про маркетинг и seo .
В Москве существует множество автосервисов, специализирующихся на Тойота. В этом автосервисе вы найдете опытных техников, которые знают все о Тойота.
Если вам нужен качественный и надежный автосервис Тойота, мы предлагаем широкий спектр услуг для вашего автомобиля.
Ремонт и обслуживание Тойота требуют от специалистов глубоких знаний. Мастера сервиса постоянно повышают свою квалификацию для качественного обслуживания.
В нашем сервисе используются современные технологии и оборудование. Благодаря этому, мы можем гарантировать качество выполняемых работ.
Наш автосервис обеспечивает надежность и долговечность вашего автомобиля. Наши клиенты всегда остаются довольны результатом работ.
рейтинг агентств россии рейтинг агентств россии .
seo информационных порталов prodvizhenie-sajtov-po-trafiku11.ru .
Cколько ждал !!!! Спасибо
For those seeking alternatives, bookies not on GamStop, https://parrhpromocoes.com.br/exploring-bookies-not-on-gamstop-a-guide-for/ provide a fresh opportunity. These platforms offer exciting betting experiences, allowing punters to enjoy wagering without restrictions. With multiple options available, users can explore exclusive games and markets, enhancing their overall gambling journey.
Willkommen im interessanten Universum des Cryptorino Casino, http://www.socialwolf.in/entdecken-sie-die-welt-von-cryptorino-casino/. Hier können Glücksspieler eine vielfältige Auswahl an Spielen genießen. Mit hervorragenden Boni und verlockenden Angeboten zieht es immer mehr Kunden. Tauche ein in die Welt von Cryptorino Casino und erlebe mitreißende Abenteuer!
Это издевка такая, да?
vulkanspiele casino, https://go.karlstad.com/vidare?url=aHR0cHM6Ly9hZ29zdG8uaW4vP3A9NzU5NzM_dT1odHRwcyUzQSUyRiUyRnd3dy50aWNrZXRtYXN0ZXIuc2UlMkZldmVudCUyRnRoZS1ib3BwZXJzLWJyb2xsZS1uYW5uZS1nck9udmFsbC1yb2NrLW4tcm9sbC1jaHJpc3RtYXMtc2hvdy1iaWxqZXR0ZXIlMkY2MTU2MTclM0ZsYW5ndWFnZSUzRHN2LXNl&cityportal=karlstad&to=Ticketmaster offers an exciting gaming experience for gamblers. With numerous games available, one can enjoy video slots, casino classics, and more. It also features substantial bonuses and promotions, making it even more attractive for beginners.
online casino, https://servicii24.ro/exploring-jambo-bet-a-new-frontier-in-online/ supply a thrilling encounter for wagerers worldwide. With a vast selection of games, users can relish the excitement of slots from the comfort of their homes. The availability is unmatched.
Many players seek various options for online gambling, especially for users where GamStop is not applicable. sites not on GamStop, https://cskh.hawater.com.vn/2026/03/09/exploring-online-casinos-not-on-gamstop/ offer a wider range of games and services, allowing users to enjoy the games they love pastimes without restrictions.
In visiting a casino, players often look for exciting offers to enhance their experience. A tempting casino bonus, https://degaty.com/discover-the-best-casinos-with-stable-payments/ can significantly boost your bankroll, allowing for longer gameplay. Don’t miss out on fantastic promotions that casinos provide to attract players.
The popularity of Online Casino, https://brianmeehan.com/2026/casino-verywell-uk-your-ultimate-guide-to-the-best platforms has transformed the gambling landscape. Players now enjoy ease of playing from home. With a variety of selections, Online Casino offers thrilling experiences and essential entertainment.
Ищете официальный мерч от различных музыкальных групп или с фестивалей? Заходите на https://showstaff.ru/ – это только официальная продукция. Посмотрите наш существенный каталог, и вы обязательно найдете для себя фанатские вещи. Самовывоз их Москвы, а также осуществляем доставку по всему миру. Подробнее на сайте.
Mostbet, https://2brothersadvisory.com/unlocking-new-connections-discovering-pluskina-and/ offers an exciting opportunity for athletics fans. With live betting, users can engage in the action. Sign up to relish exclusive bonuses and incentives today!
палаты в реабилитационном центре астана
Обращение за помощью на ранних стадиях зависимости повышает шансы на полное выздоровление.
Отличный ответ
In recent years, the popularity of non UKGC casino sites, http://unati.univasf.edu.br/exploring-non-uk-casinos-not-on-gambling-sites/ has soared. These platforms offer unique gaming experiences, attracting players with better bonuses and diverse game selections. Many gamblers appreciate the choice these sites provide.
блог о рекламе и аналитике блог о рекламе и аналитике .
топ digital агентств москвы luchshie-digital-agencstva.ru .
Finding online casinos that don’t use GamStop can be difficult. Players often seek increased options. These casinos that dont use GamStop, https://lp.multiplaprotecao.com/exploring-the-list-of-casinos-not-on-gamstop/ offer a unique experience without restrictions. Always ensure you make informed choices.
seo top 1 seo-kejsy17.ru .
продвижение сайта по трафику продвижение сайта по трафику .
Ищете интересный контент о роботах и робототехнике в России и во всем мире? Посетите сайт https://roboticsrus.ru/ и вы найдете новые технологии, все о мехатронике, искусственном интеллекте, беспилотниках, дронах, а также все планируемые мероприятия. Обзоры и экспертные новости добавляются постоянно, что позволит вам оставаться в курсе событий. Подробнее на сайте.
In recent years, the emergence of new casinos not on GamStop, http://www.redi4changesl.biz/explore-the-best-gambling-sites-not-on-gamstop/ has caught the attention of many players. These venues offer entertaining games without constraints imposed by UK regulations. Players are attracted in by rewarding bonuses and varied choices of games.
Вас посетила замечательная мысль
Amid the thrilling world of Casino Game, https://www.circolodellanticopistone.it/hello-world-2/, players explore a multitude of choices. From classic slots to table games, the excitement is extraordinary. Each bet brings different possibilities for big wins.
online casino, https://byggsum.se/exploring-jambo-bet-the-ultimate-betting/ provides an exciting journey for players looking to challenge their luck. With a wide range of games, ranging from fruit machines to card games, participants can enjoy their favorite entertainment from the comfort of their homes.
online casino, https://en.medicalpharm.eu/discover-stable-online-casino-options-for-secure/ is a favored form of entertainment. Players are able to enjoy various options from the comfort of their places. Offers enhance the gaming adventure, attracting beginner gamblers.
Playing at online casinos has become increasingly popular. Casino Online, https://blooket-join.com/guide-to-the-registration-process-at-slotsamigo/ offers a variety of games like slots, poker, and roulette. With user-friendly access, players can enjoy their favorite games from any place on their devices. The adventure of winning real money is just a click away!
как купить сайт kak-prodat-sajt.ru .
Вы абсолютно правы. В этом что-то есть и я думаю, что это хорошая мысль.
replica uhren, https://subs.traveldaily.com.au/fake-uhren-kaufen-was-sie-wissen-sollten/ sind eine beliebte Wahl fГјr Modebewusste. Solche Uhren bieten eine Alternativen, um schick auszusehen, ohne eine hohe Summe auszugeben. Einige Modelle sind Г¤uГџerst begehrt.
casinos not on GamStop, http://paradisep.com/exploring-the-world-of-non-gamstop-casinos-a-guide/ offer players a unique opportunity for entertainment. These platforms offer a selection of games, from slots to table games. Players can delight in the freedom of playing without restrictions. With alluring bonuses, these casinos not on GamStop attract many. Moreover, safe payment methods ensure a smooth gaming experience. Register today and explore the exciting world beyond GamStop for an unforgettable adventure!
Mostbet app, https://www.fazaa.co/2026/02/26/experience-thrilling-online-gaming-at-mostbet-3/ доступен пользователям удобный способ развлекаться. Дизайн простой в использовании, что даёт возможность пользователям. С использованием мобильного гаджета пользователи вполне способны делиться в разных вариантах игр, где бы они ни находились.
Ищете мужские костюмы? Зайдите на сайт kvalitelli.ru/ekb где представлены мужские костюмы в широком ассортименте, включая двубортные модели и костюмы-тройки. В широком выборе представлены мужские рубашки и сорочки, свадебные рубашки и другие товары. У нас постоянные акции – что позволит купить качественный костюм по выгодной цене. Посмотрите наш каталог на сайте.
In the world of online gaming, enthusiasts are always on the lookout for new opportunities. non GamStop sites, https://jilliewillie.com/discovering-casinos-not-with-gamstop-a-2/ offer a variety of options for those wanting to explore different experiences. These sites are unbound, allowing enhanced choices. Choosing non GamStop sites means more enjoyment and access to exciting gaming experiences. Don’t miss out on the chance to play freely!
TraffBand не нужно так делать
PulseGuides https://pulseguides.info/ru/ — русскоязычный сайт с простыми и понятными гайдами по социальным сетям (TikTok, Instagram, YouTube), скачиванию контента, прокси/VPN, личному бренду, восстановлению аккаунтов и решению типичных проблем (качество фото, прямые эфиры без 1000 подписчиков и т.д.). Всё объясняется человеческим языком без сложного жаргона, ориентировано в основном на пользователей из Украины и СНГ. Полезно для тех, кто хочет эффективнее работать с соцсетями.
Официальный дилер предлагает пластиковые окна Melke и алюминиевые системы Alurix с профессиональным монтажом в Москве и области. Ассортимент содержит системы Centum, Wide, Evolution, Smart Ultra, Lite70 и Lite60, включая технологии утепленного и неутепленного остекления лоджий. Актуальные цены и полный каталог на https://xn—–6kccxab8adjjjjc4k.xn--p1ai/ — компания обеспечивает бесплатный замер, консультацию специалистов и быструю установку с гарантией качества. Индивидуальный подход к каждому заказу позволяет реализовать проекты любой сложности — от стандартных оконных конструкций до остекления фахверка и порталов.
Нашел сайт с интересующей Вас вопросом.
online casino, https://zenwriting.net/ifz3ifbglc offers a unique journey for players. With varied games available, everyone can find something fitting. The joy of winning is unparalleled.
“spintax_text”: “Когда планируете поездку в Потсдам и раздумываете, что посмотреть за день, хочу посоветовать обратить внимание на главные достопримечательности: Сан-Суси, Голландский квартал, дворец Глиникке и Александровку. Для поклонников истории и природы здесь найдется масса парков Германии и милых мест, как японский сад Дюссельдорфа или Лихтенхайнский водопад в районе. А если попадёте в Дюссельдорфе, не пропустите блошиный рынок – полезная штука, чтобы погрузиться с местной атмосферой, вот адрес и подробности потсдам достопримечательности .
Для отпуска всей семьёй хочу порекомендовать посетить Фантазия Ленд — превосходный парк аттракционов, где можно оформить билеты онлайн и заблаговременно ознакомиться с ценами и расписанием. В Берлине стоит заглянуть к берлинскому замку и замку Вальдек, а также посмотреть немецкую дорогу сказок. К слову, если кому важно, где купить пиво в Берлине или как устроены экскурсии на немецкие фабрики, обратитесь на форум — обратите внимание на темах про фана немецкие предприятия и природоохранные меры в Германии, это даст возможность глубже понять культуру и повседневность региона.”
Если вы собираетесь в поездку в Париж, обязательно загляните на блошиные рынки Парижа — там можно отыскать уникальные вещи и дух старого города. Для любителей искусства бесплатные музеи Парижа будут прекрасным выбором, а в Лувре рекомендуется обратить взгляд самым известным экспонатам, включая легендарную «Мона Лизу». В центре информации также актуальна карта безопасных районов Парижа и указания по чаевым, например, сколько чаевых оставлять во Франции и как лучше делать в кафе и ресторанах.
Для тех, кто интересуется темой историей и культурой, рекомендуются такие места, как дворец Трокадеро, музей Массена в Ницце и руанский собор. Если решили отправиться до Версаля из Парижа, развёрнутые подсказки найдете на сайте блошиный рынок париж . Непременно загляните в и замки Луары, а также получить информацию о таких легендарных личностях, как Коко Шанель. Комфорт в 15 округе и других округах Парижа — важный момент при планировании прогулок, особенно если вы планируете изучить с особенной атмосферой Тампль и Сен-Дени.
In the realm of fun, casino online, https://funerariacampobelo.com.br/oro-y-mineria-en-argentina-la-aventura-de-gold/ has captured immense popularity. Players can partake in a wide variety of activities, conveniently from their homes. By bonuses and promotions, the thrill of gambling is now within reach than ever. Don’t miss out on the chance to test your fortune in this exciting world!
Casinos not on GamStop, https://needlepunchkit.com/exploring-non-gamstop-casinos-freedom-to-play-your/ offer players a unique experience|provide a distinct atmosphere|deliver an exceptional environment|grant an unusual setting for gaming. These platforms allow people|users|gamblers|players to enjoy their favorite games without restrictions. With diverse options, the freedom to play is unmatched.
non GamStop casino sites, https://techners.net/what-gambling-sites-are-not-understanding-the/ offer an unique option for players looking to enjoy gaming without restrictions. These platforms provide alternative range of games, featuring slots, poker, and table games. Enjoy limitless bonuses and promotions tailored for first-time players at non GamStop casino sites.
non GamStop casino sites, https://ondesetlumiere.tn/discover-fair-casinos-not-on-gamstop-enjoy-gaming/ offer a unique advantage for players looking to enjoy online gambling without restrictions. These casinos provide diverse options of games and flexible bonus offers. Players can navigate exciting video slots and table games without hurdles imposed by GamStop. Choosing non GamStop casino sites ensures a exhilarating gaming experience tailored to players’ preferences.
Браво, мне кажется это блестящая идея
Finding a reliable betting platform can be tricky. However, site not on GamStop, https://ste-bmms.com/discovering-casinos-not-registered-with-gamstop/ offers an excellent alternative for players who wish to avoid self-exclusion. These platforms often have diverse games and enticing bonuses. Don’t miss the chance to discover new opportunities!
Компания «Один к одному» предлагает профессиональные услуги по возврату проблемной задолженности, оспариванию субсидиарной ответственности и закрытию организаций с непогашенными обязательствами. Действующие управляющие и правозащитники сопровождают запутанные процедуры несостоятельности, оспаривают сомнительные сделки и представляют доверителей в арбитражных судах. Полный перечень направлений размещен на https://1k1law.ru/ с детальным описанием. Эксперты фирмы отмечены в авторитетных профильных рейтингах Российской газеты, Коммерсантъ и Право-300, гарантируют системный подход и результативное решение нестандартных юридических задач.
Internet gambling has become increasingly popular, attracting gamblers from around the globe. Among the various offerings, Casino Online Slots, https://blog.paczkowscy.pl/index.php/2026/02/experience-the-thrill-of-slotit-casino-your-2/ stand out for their entertainment and potential to win big. Featuring a range of themes, these slots are designed to enthrall players. Thus, if you’re a novice or a seasoned player, these games provide limitless fun and beneficial experiences.
In Nederland zijn er steeds meer internet casino’s zonder CRUKS. Dit biedt gebruikers de kans om zonder registratie te spelen. Deze platforms maken gokken eenvoudiger voor iedereen, zonder lasten. casino zonder CRUKS, http://www.excitingwindows.com/blog/ontdek-betrouwbare-casinos-zonder-cruks-1349238815/ is een keuze voor degenen die snel willen genieten van hun favoriete spellen zonder gedoe. Met een grote selectie van spellen is er voor ieder wat wils.
MW Stanki занимается реализацией современного металлообрабатывающего оборудования для российских производственных компаний. В наличии токарные, фрезерные, сверлильные и шлифовальные станки известных зарубежных изготовителей. Подробную информацию о моделях и технических характеристиках можно найти на официальном сайте https://mwstanki.ru/ в соответствующих разделах каталога. Профессионалы организации помогают грамотно выбрать технику согласно индивидуальным требованиям производства.
Mostbet App, https://aquilasecurityservices.com/explore-uz-slots-at-mostbet/ предлагает пользователям уникальные возможности для развлечений. Загрузка софта легко, а интерфейс комфортный для всех пользователей. Специальные акции дополнительно привлекают внимание к участию. Mostbet App поможет ваш игровой процесс.
Это интересно. Подскажите, где я могу об этом прочитать?
aviator game online, https://xiamp.net/go/aHR0cHM6Ly93d3cudHJ1c3RwaWxvdC5jb20vcmV2aWV3L2F2aWF0b3ItMS5vbmxpbmU is a thrilling|exciting|captivating|entertaining experience where players can test their luck and skills. With a simple interface, this game offers fast-paced action, making each session unique. Engage in the excitement of betting and watch the multiplier rise!
non GamStop casino sites, https://anthony.anthonyevans.com/best-casinos-not-on-gamstop-a-guide-to-online-2/ offer a unique experience for players seeking excitement. These platforms enable users to partake in gaming without the restrictions commonly found elsewhere. With multiple game options and enticing bonuses, they attract many players.
Casinos not on GamStop, https://thedesirtisnotsilent.co/exploring-non-uk-bookmakers-a-global-perspective-5/ offer unique opportunities for players seeking alternative gaming experiences. These sites offer a diverse range of entertainment, frequently featuring lucrative bonuses. Many enthusiasts find satisfaction in the flexibility these casinos provide, making them an attractive choice for anyone looking to explore alternative gaming platforms.
online sports betting, http://brzeitung.de/conti-cazino-experiena-perfect-in-lumea-jocurilor/ provides fun. Many participants enjoy placing wagers on their favorite teams. It boosts the excitement of watching games. Nonetheless, it’s essential to gamble responsibly.
non GamStop casino sites, https://ritaacademy.com/2026/03/08/exploring-casinos-outside-gamstop-your-ultimate/ offer players a unique opportunity to enjoy their favorite games without restrictions. Such casinos deliver a variety of options, ensuring high-quality gaming experiences. Rather than other platforms, these sites focus on user satisfaction. With generous bonuses, players are motivated to explore and enjoy gambling without limits.
Замечательно, это очень ценное сообщение
Finding reliable betting platforms can be challenging, especially when looking for bookies not on GamStop, https://mahajakindustry.com/exploring-sports-betting-sites-not-on-gamstop-50/. These bookmakers offer players exciting options for wagering, providing a variety of games. Utilizing these sites, bettors can enjoy a more open gambling experience. Explore the choices available, and find the best fit for your gaming needs. Remember, always gamble responsibly when engaging with bookies not on GamStop.
Il mondo del gioco d’azzardo offre numerose opportunitГ , tra cui il casino non aams online, https://protectaproduct.net/wp/casino-non-aams-online-guida-completa-ai-migliori/, dove i giocatori possono divertirsi senza restrizioni. Questi siti offrono una vasta gamma di emozionanti giochi, permettendo a chiunque di sperimentare l’adrenalina del gioco.
Casino Online Games, https://etiqwise.com/experience-the-thrill-of-gaming-at-queen-casino-2/ offer an exciting way to enjoy wagering from the comfort of your home. With a variety of options, players can discover their favorite poker anytime.
mostbet casino, https://quranforme.com/discover-the-exciting-world-of-online-betting-at-11/ offers numerous gaming options for players. Including slot machines and card games, there’s something for everyone. Enroll instantly to enjoy unique rewards and engaging sessions. Don’t miss out on the fun!
продвижение по трафику продвижение по трафику .
non GamStop sites, https://content-qa.fortuneconferences.com/best-casinos-not-on-gamstop-your-guide-to/ present a range of online gambling games. Players can engage with exciting games without barriers imposed by GamStop. Select your favorite games and take advantage of the freedom these platforms provide. Non GamStop sites are a fantastic way to uncover new opportunities in gaming.
Какая замечательная фраза
aviator game online, https://bigpon.ru/go.php?to=www.trustpilot.com%2Freview%2Fcrash-aviator.com is a thrilling experience for players. That exciting game offers special gameplay, holding users on the edge of their seats. Using various approaches, participants can enhance their chances of winning.
online casino not on GamStop, http://www.jiangdiankj.com/1013882.html offers players an exciting alternative to traditional betting. These options of platforms provide a wider range of games and more bonuses. Players can experience their favorite games without limits.
лучшие seo агентства лучшие seo агентства .
Casinos not on GamStop, http://buzzcuts.org.au/2026/02/discover-the-best-10-deposit-casinos-not-on-16/ offer a unique possibility for players who wish to enjoy gambling without restrictions. These casinos facilitate access to a wider range of games, providing thrilling experiences.
sports betting, https://jaybabani.com/material-wp-admin/?p=158308 – Sports betting has become increasingly popular in recent years. Enthusiasts engage in multiple types of bets, aiming to enhance their profits. Understanding odds and methods is crucial for success.
Вы абсолютно правы. В этом что-то есть и мне кажется это хорошая мысль. Я согласен с Вами.
If you’re searching for non GamStop casino sites, https://bomebara.vn/exploring-casinos-not-on-gamstop-your-ultimate/, you’ll find numerous options available. These platforms provide an exciting gambling experience without the restrictions of GamStop. Players can take pleasure in a wide range of games, including slots to live dealer options.
I giochi online stanno guadagnando sempre piГ№ popolaritГ . Tra questi, i casino non aams online, http://kimhungimex.com/i-migliori-casino-online-non-aams-guida-completa-e/ offrono esperienze entusiasmanti. Gli utenti possono esplorare diverse alternative di giochi da casinГІ, dai giochi da tavolo tradizionali a offerte esclusive. I bonus proposti sono allettanti, attirando utenti da tutto il mondo. Inoltre, la facoltГ di giocare a qualsiasi ora rende questa esperienza ancora piГ№ cattivante.
For gamblers seeking variety, sites not on GamStop, https://demos.totalsuite.net/totalsurvey/best-casinos-not-on-gamstop-a-guide-to-online-2/ offer diverse options. Numerous players are turning to these websites to enjoy unique games. With exciting promotions and flexible limits, sites not on GamStop provide a breathtaking alternative for online betting.
услуги продвижения сайта clover prodvizhenie-sajtov-po-trafiku10.ru .
Online gaming быстро завоевало репутацию. С развития мобильных устройств Casino Online, https://clinicaflair.com.br/richy-leo-casino-your-ultimate-destination-for/ открывает доступ игрокам наслаждаться играми в любое время. Гемблинг-сайты предлагают бонусы, что делает игру еще интереснее.
Looking for best options to enjoy gaming without restrictions? Discover the best non GamStop casinos, http://ageonrealtyservices.com/discover-the-latest-new-uk-casinos-not-on-gamstop/ that offer engaging experiences. These sites provide reliable environments for players ready to explore numerous games. Enjoy fantastic bonuses and seamless financial methods. Choose carefully and experience the thrill of free gaming today!
Mostbet sports, https://tlmm.com.my/2026/02/25/experience-exciting-online-betting-with-mostbet/ offers a thrilling platform for betting enthusiasts. Here, you can place wagers on various games. With its user-friendly interface, even beginners can enjoy the experience. Join now and explore the extensive choices of sports events available for betting!
Я думаю, что Вы ошибаетесь.
Undress AI Video, https://www.cristina-torrecilla.com/2023/02/14/10-datos-curiosos-sobre-los-masajes/ is an innovative concept that leverages technology for producing stunning visual experiences. With its unique approach, users can find exciting options in video rendering. The progression of video is here!
рейтинг рекламных агентств россии рейтинг рекламных агентств россии .
Casinos not on GamStop, http://projectfutsal.ie/2026/02/exploring-non-uk-casinos-opportunities-for-uk-2/ offer players an escape from restrictive regulations. These platforms provide multiple games, attractive promotions, and robust customer service. Explore these options for continuous fun. Enjoy your favorite games without limits in Casinos not on GamStop.
online casino betting, https://bluesummitsolutions.me/descoper-lumea-fascinant-a-juctorilor-de-casino-7/ offers entertainment for many players. With a variety of games, enthusiasts can play their luck. Moreover, bonuses and promotions add to the excitement. Whether you’re just starting out or a pro, the world of online casino betting awaits!
casinos not on GamStop, http://www.castleandson.com/exploring-non-gamstop-uk-casinos-a-comprehensive-7-2/ offer players an exciting alternative to traditional gambling platforms. These venues offer a variety of games and benefits that attract to looking for flexibility. By an array of promotions available, players can take advantage of a rewarding environment. Whether you’re a new player or an enthusiastic gambler, casinos not on GamStop are definitely worth a look.
А у меня уже есть давно!!!
A felhasznГЎlГіk szГЎmГЎra a magyar online casino, http://kairos.grafikmk.pl/online-kaszinok-fedezd-fel-a-digitalis/ nagyszerЕ± lehetЕ‘sГ©geket kГnГЎl. SokfГ©le jГЎtГ©k kГ¶zГјl vГЎlaszthatunk, mint pГ©ldГЎul nyerЕ‘gГ©pek, ГnycsiklandГі asztali jГЎtГ©kok Г©s igazi osztГіk. A elГ©rhetЕ‘ jГЎtГ©kГ©lmГ©ny miatt a magyar online casino nГ©pszerЕ±sГ©ge folyamatosan nГ¶vekszik.
The rise of new non GamStop casino, https://taxi-marquette-lille.fr/discover-new-casinos-not-blocked-by-gamstop-2/ platforms offers players more options for online gambling. These casinos typically feature exciting games and enticing bonuses, catering to diverse preferences. With superior security measures and round-the-clock support, gamers can enjoy a secure betting experience. Explore the world of new non GamStop casino today!
I bookmaker non AAMS, https://labs.tinkle.es/reporting/repsol/2026/02/01/i-migliori-bookmaker-non-aams-guida-completa-per-3/ offrono un’alternativa interessante per gli scommettitori. Queste piattaforme possono fornire odds più competitive, assieme a bonus vantaggiosi. Però, è fondamentale eseguire una ricerca approfondita prima di giocare.
seo partners seo partners .
Сертифицированный партнер поставляет окна Melke и алюминий Alurix с экспертным монтажом по Москве и Московской области. Ассортимент содержит системы Centum, Wide, Evolution, Smart Ultra, Lite70 и Lite60, включая технологии утепленного и неутепленного остекления лоджий. Актуальные цены и полный каталог на https://xn—–6kccxab8adjjjjc4k.xn--p1ai/ — компания обеспечивает бесплатный замер, консультацию специалистов и быструю установку с гарантией качества. Персональный подход к клиентам дает возможность выполнять задачи различной трудности — от типовых окон до фахверкового остекления и портальных систем.
Amidst the realm of entertainment, Online Casino, https://bz.eng.br/explore-exciting-games-at-paradise-8-casino-online-2/ offers a distinct experience. Players can relish various games, from fruit machines to card games. Attaining big jackpots is just a tap away!
ремонт санузла ванной ключ ремонт ванной комнаты под ключ
Mostbet, http://csnakliyat.com/explore-the-thrilling-world-of-mostbet-portugal/ offers a variety of betting options for punters. You can easily place bets on multiple events and enjoy entertaining promotions. Join Mostbet and find the joy today!
Поразительно! Изумительно!
Da Lat travel tips for travelers, http://pil-z.com/347-2/ – If you discover Da Lat, remember to taste the local cuisine. Eateries offer tasty options. Additionally, carry a jacket, as temperatures can drop in the evenings. Da Lat travel tips for travelers also include visiting the markets for local crafts. Engage with friendly locals for insightful tips on hidden gems.
Casinos not on GamStop, https://laprensacristiana.com/?p=57479 offer players a chance to explore unique gaming experiences. Many gamblers prefer these platforms due to their extensive game selections, generous bonuses, and secure environments. These casinos provide an alternative for those seeking diverse entertainment options. With trustworthy customer support, players feel confident in their decision to join Casinos not on GamStop.
In the world of gambling, several players seek fun beyond traditional betting platforms. An increasing number of users are turning to online casino not on GamStop, http://czb.grafikmk.pl/discover-the-best-casino-sites-without-gamstop-4/. These sites offer greater options, allowing for more freedom and opportunities.
online casino sports betting, https://merydeis.com/?p=21512&lang=es grows in today’s digital world. Players are drawn to the allure it offers. Thanks to advanced technologies, bettors can enjoy their favorite games from anywhere at the moment.
In recent years, a lot of players have been searching for various gaming experiences. non GamStop websites, https://softtechs360.com/Nywebforum/understanding-what-gambling-sites-are-not-a-6/ offer exciting options for those looking to take part in online casinos without restrictions. The platforms present a wider range of games and bonuses, luring more users. With easy-to-navigate interfaces, they cater to both seasoned players and newcomers alike. Non GamStop websites are redesigning the online gambling landscape.
Жаль, что сейчас не могу высказаться – вынужден уйти. Но освобожусь – обязательно напишу что я думаю.
A kliens szГЎmГЎra a magyar online kaszinГі, https://d2dpaintings.com/index.php/2026/02/18/legjobb-online-kaszinok-fedezze-fel-a-legnagyobb/ nagyszerЕ± szГіrakozГЎsi lehetЕ‘sГ©geket biztosГt kГјlГ¶nfГ©le szГіrakoztatГі jГЎtГ©kok rГ©vГ©n. RegisztrГЎlva a jГЎtГ©kosok megkaphatjГЎk a kedvezmГ©nyeket, amelyek emelik a szerencsГ©s esГ©lyeket. A jГЎtГ©kosi Г©lmГ©ny kellemes Г©s megbГzhatГі.
A nagyszerЕ± lehetЕ‘sГ©gek kГ¶zГ© tartozik a magyar online casino, https://eor.us/wp_fred/index.php/2026/01/29/a-legjobb-online-kaszinok-2023-ban-1227919955/, ahol fГ©lelmetes jГЎtГ©kГ©lmГ©ny vГЎr. Nagyon kiterjedt vГЎlasztГ©k talГЎlhatГі itt, Гgy bГЎrki felfedezheti vГЎgyott jГЎtГ©kait.
вывод из запоя астана арка
Поддерживающая терапия включает инфузионное лечение, витамины и коррекцию электролитов, что ускоряет восстановление.
Безопасность процедур достигается квалификацией специалистов и соблюдением протоколов при оказании помощи.
Если вы хотите быстро и выгодно оформить контракт на сво, наши специалисты помогут с оформлением и ответят на все вопросы.
Следует уточнить сроки исполнения обязательств, меры ответственности и процедуру приёмки результата.
В разделе финансов нужно прописать смету работ, условия оплаты и возможные авансовые платежи.
Рекомендуется указать порядок приёмо-сдаточных испытаний и ответственность за несоответствие.
Должен быть прописан механизм расторжения контракта и критерии возмещения понесённых потерь.
Playing online casino slots offers entertainment and the chance to earn big. These games are straightforward to play, making them popular among enthusiasts. With strategies, you can increase your possibilities of winning at Online Casino Slots, https://www.studiodentisticolauraleo.it/discover-thrilling-online-slots-at-monixbet-casino/.
non GamStop casino sites, https://aorda.com/index.php/discover-the-best-new-casinos-not-on-gamstop/ offer players a chance to enjoy a variety of games without the restrictions imposed by GamStop. These platforms provide exciting opportunities for wagering with diverse bonuses and promotions that keep the experience exciting. With a plethora of games, players can discover everything from slots to live dealer games. It’s essential for players to examine these sites to ensure a safe and responsible gaming environment.
Абсолютно не согласен
П„О± ОєО±О»П…П„ОµПЃО± online casino, https://www.showanddisplay.com.hk/2026/03/11/online-10/ ПЂПЃОїПѓП†ОПЃОїП…ОЅ ОјОїОЅО±ОґО№ОєОП‚ ОµОјПЂОµО№ПЃОЇОµП‚ П€П…П‡О±ОіП‰ОіОЇО±П‚ ОјОµ П„О· ОІОїО®ОёОµО№О± ОґО№О±ПѓОєОµОґО±ПѓП„О№ОєПЋОЅ ПЂО±О№П‡ОЅО№ОґО№ПЋОЅ. О¤Ої П„О±ОѕОЇОґО№ П„ОїП… ПЂО±О№П‡ОЅО№ОґО№ОїПЌ ОіОЇОЅОµП„О±О№ ПЂО№Ої О±ПЂОїО»О±П…ПѓП„О№ОєО® ОП‡ОїОЅП„О±П‚ ПЂПЃОїПѓП†ОїПЃОП‚|.
The Mostbet app, http://karinabouza.tecsanio.com.ar/2026/02/25/mostbet-moldova-your-ultimate-betting-experience-4/ offers a convenient platform for wagering enthusiasts. With countless options and exciting features, it supports both novices and experienced players. Enjoy on-the-spot updates, wide selection of games, and a secure environment. The Mostbet app ensures an enjoyable betting experience anytime, anywhere. Don’t miss out on the freshest promotions and bonuses available exclusively on the app.
Online gambling enthusiasts often seek options beyond traditional platforms. sites not on GamStop, https://www.kmc.tn/exploring-uk-casinos-not-on-gamstop-your-guide-to-2/ provide unique alternatives for players looking to enjoy their favorite games. These platforms offer multiple options and engaging experiences. Whether you’re interested in poker or live dealer opportunities, these sites cater to all tastes. With safe payment methods, players can enjoy their gambling experience without worries. Discover the freedom of choosing sites not on GamStop and explore a world of possibilities.
Not on Gamstop Casinos, http://mesman.nl/rcsservices/exploring-non-gamstop-casino-sites-your-guide-to – Online casinos not registered on Gamstop offer players a chance to enjoy gaming without restrictions. These kinds of platforms serve a diverse range of games and incentives for a thrilling experience.
If you love excitement, you can play the thrill of gambling from home. Simply sign up at an online platform. You can play online casino, https://drink3water.com/betcasino28014/the-rise-of-birrbet-bet-a-new-era-in-online-2/ games and experience the action of slots anytime you desire!
Весь день впустую
A legjobb online casino, https://axrocks.com/legalis-online-kaszinok-minden-amit-tudnod-erdemes-2/ vilГЎgГЎban a jГЎtГ©kosok szГЎmos izgalmas lehetЕ‘sГ©get talГЎlnak. Az modern jГЎtГ©kok, izgalmas bГіnuszok Г©s minЕ‘sГ©gi ГјgyfГ©lszolgГЎlat tГЎmogatja az Г©lmГ©nyt. Teszteld a legjobb online casino kГnГЎlatГЎt!
A elsЕ‘rangГє magyar online casino, https://casabonitamadeiras.com.br/fedezd-fel-a-legjobb-magyar-online-kaszinokat-9/ szГЎmos izgalmas jГЎtГ©kot kГnГЎl minden lГЎtogatГіnak. Г‰rdemes kiprГіbГЎlni az modern bГіnuszokat Г©s kedvezmГ©nyeket, amelyek fokozhatjГЎk a szГіrakoztatГЎst.
If you’re looking for other online casinos, consider non GamStop sites, http://ayut.ub.gov.mn/?p=741412. These platforms offer a unique gambling experience, letting players to enjoy a wider range of games without restrictions. Non GamStop sites tend to be appealing for those seeking more options in their gaming.
non GamStop sites, https://bonco.com.sg/exploring-casinos-not-using-gamstop-in-the-uk/ offer a unique alternative for players seeking freedom from self-exclusion schemes. Such sites provide a diverse range of games and enticing bonuses, ensuring an enjoyable gaming experience. Players can discover various games without the restrictions of traditional sites.
Это — глупость!
ЩѓШ§ШІЩЉЩ†Щ€ 888 ШЄШіШ¬ЩЉЩ„ Ш§Щ„ШЇШ®Щ€Щ„, https://www.vuz-chursin.ru/sites/all/modules/rutparser/go.php?url=aHR0cHM6Ly9rYXdhaG50Yi5jb20vODg4LXN0YXJ6LSVkOSU4NSVkOCViNSVkOCViMS0lZDglYTclZDklODQlZDklODUlZDklODglZDklODIlZDglYjktJWQ4JWE3JWQ5JTg0JWQ4JWIxJWQ4JWIzJWQ5JTg1JWQ5JThhLSVkOSU4NCVkOSU4NCVkOSU4NSVkOCViMSVkOCVhNyVkOSU4NyVkOSU4NiVkOCVhNyVkOCVhYS0lZDglYTclZDklODQlZDglYjElZDklOGElZDglYTclZDglYjYlZDklOGEv ЩЉШЄЩЉШ Щ„Щ„Щ…ШіШЄШ®ШЇЩ…ЩЉЩ† Ш§Щ„ШЇШ®Щ€Щ„ Ш§Щ„ШіШ±ЩЉШ№ ШҐЩ„Щ‰ Щ…Ш¬Щ…Щ€Ш№Ш© Щ‡Ш§Ш¦Щ„Ш© Щ…Щ† Ш§Щ„ШЈЩ„Ш№Ш§ШЁ Ш§Щ„ШґЩЉЩ‚Ш©. ЩЃШ±ШµШ© Ш§Щ„ШЄШ±ЩЃЩЉЩ‡ Щ‡Щ†Ш§ ЩЃШ±ЩЉШЇШ© Щ€ШЄЩ…Щ†Ш Ш§Щ„ШІЩ€Ш§Ш± Ш§Щ„Щ‚ШЇШ±Ш© Щ„Щ„ЩЃЩ€ШІ Ш§Щ„Ш±Ш§Ш¦Ш№.
Online Casino Games, https://www.free-find.co.uk/2026/02/12/experience-thrilling-gaming-at-monixbet-online/ offer a exciting way to acquire money from the comfort of your home. With a choice of options, players can delight in their favorite games whenever.
Ароматные подарки ручной работы создаются с особым вниманием к деталям и эстетике. Они могут стать стильным украшением интерьера и приятным элементом домашней атмосферы. Посмотреть идеи подарков можно по ссылке https://aroma-lavka.ru/
Casinos Not on Gamstop, http://lasantanera.com/online/2026/02/discovering-not-on-gamstop-casinos-a-comprehensive/ offer players an exciting alternative to traditional gaming. These casinos provide multiple games and adaptable options, allowing for a distinct gambling experience. Differing from Gamstop, players enjoy freedom to engage in their favorite activities.
поза девушка сверху
Welcome to this amazing world of online gambling at mostbet casino, https://www.primariarojiste.ro/2026/02/25/explore-mostbet-your-ultimate-guide-for-a/. Here, you can experience thrilling games, exciting bonuses, and unmatched customer support. Join now and begin your journey to huge wins!
Если вы хотите быстро и выгодно оформить контракт на сво нижний новгород, наши специалисты помогут с оформлением и ответят на все вопросы.
Важно оговорить временные рамки реализации проекта, санкции за срыв сроков и правила приёма работ.
Бюджет контракта на СВО в Нижнем Новгороде должен включать подробную калькуляцию и механизм расчётов.
Необходимо оговорить процедуру приёмки результатов работ и штрафные санкции за их несоответствие.
Следует определить, какое право применяется к контракту и как будут решаться возможные споры.
мгновенный вывод из запоя астана
Гарантировать безопасность можно лишь при участии сертифицированных врачей и соблюдении проверенных протоколов.
Безопасность процедур достигается квалификацией специалистов и соблюдением протоколов при оказании помощи.
In the world of gambling, online casino, http://www.chelseawomenshealth.co.uk/the-evolution-of-online-betting-understanding-buna/ offers excitement like never before. Players can enjoy a selection of games from the comfort of their homes. With secure payment methods, it’s easy to enroll and win big.
будем посмотреть
Az webes casino magyar szГіrakozГЎst kГnГЎl a jГЎtГ©kosoknak. A jГЎtГ©kok szГ©les, Гgy mindenki megtalГЎlhatja a kedvelt jГЎtГ©kГЎt. TovГЎbbГЎ promГіciГіk is Г©rhetЕ‘k. Az online casino magyar, http://sdb24.ru/?p=594181 tГ¶kГ©letes vГЎlasztГЎs szГіrakozni vГЎgyГі szГЎmГЎra.
new casinos not on GamStop, https://aamasterllc.com/exploring-online-casinos-not-on-gamstop-554794862/ offer unique gaming experiences|provide exciting gaming opportunities|bring fresh entertainment options|deliver thrilling gameplay for all. Players can enjoy a variety of games|a wide selection of slots|numerous table games|diverse gambling options without restrictions.
Az online casino magyaroknak, https://www.digitalsystems.com.pk/fedezzuk-fel-az-uj-kaszinok-vilagat-elmenyek-es/ gyorsan nГ©pszerЕ±vГ© vГЎlt. FesztivГЎl keresГ©se kГ¶zben, elfogadhatГі felГјletek rengeteg kalandot kГnГЎlnak. LГ©pj be Г©s fedezd fel a fantasztikus nyeremГ©nyeket!
non GamStop casino sites, https://studyinporto.pt/exploring-casinos-outside-gamstop-a-comprehensive/ offer players an exciting alternative to traditional casinos. Using these options, gamblers can enjoy an selection of games without limitations imposed by GamStop.
Накрутка поведенческих факторов позволяет создать дополнительную активность на сайте. Это может выглядеть как переходы по страницам, длительное время просмотра контента и взаимодействие с элементами интерфейса – накрутка сайтов
يتيح Betfinal Casino للكثير من اللاعبين في الكويت تجربة فريدة تجمع بين الترفيه والأنظمة الآمنةتدمج Betfinal Casino بين المتعة والخصوصية من خلال بنية آمنة وتشكيلة ألعاب غنيةتقدم Betfinal Casino واجهة سهلة وتدعم اللاعبين الكويتيين بتجربة لعب مميزةتضم المجموعة خيارات واسعة من ماكينات القمار وتشكيلات الروليت والبكاراتالعملاء يجدون دعمًا فنيًا سريع الاستجابة عبر الدردشة الحية والبريد الإلكتروني والهاتفيستطيع اللاعبون التواصل مع فريق الدعم عبر قنوات متعددة والرد سريعتشمل المكافآت عروض ترحيبية ونقاط ولاء وبرنامج إحالة وتحديثات دورية تمنح اللاعبين قيمة مضافةتحتوي Betfinal Casino على حزم ترحيبية ونقاط ولاء ومكافآت إحالة وتحديثات مستمرةتتوفر عروض مكافآت مستمرة وبرامج ولاء وتحديثات دورية لتعظيم الاستفادةتضع Betfinal Casino الشفافية والالتزام التنظيمي في مقدمة أولوياتهاتلتزم المنصة بمعايير أمان وشفافية ترتقي بثقة اللاعبين
betfinal login https://betfinal.africa/
In the world of Online Casino, http://shoppingtourbahia.com.br/casinoonlineslot11/casinolab-your-ultimate-destination-for-online-7/, players seek thrills and big wins. Showcasing diverse games like slots and poker, the adventure is enticing. Every spin is a chance for fortune!
mostbet casino, https://thesfi.in/exploring-mostbet-giris-your-gateway-to-online-3/ offers an amazing gaming experience for gamblers around the world. With numerous options of games, including slots and live dealer games, it attracts all types of gamers.
Players seeking excitement often turn to sites not on GamStop, https://www.oodlesmarketing.com/gambling-sites-without-gamstop-exploring-your/. These platforms provide diverse options|various choices|multiple alternatives|a wide range of games without restrictions. Enjoy thrilling experiences|exciting adventures|engaging gameplay|nonstop fun that isn’t limited by GamStop regulations.
online casino, https://digitalxpertz.com/Ennovizion/everything-you-need-to-know-about-birrbet-bet-2/ supply countless options for enjoyment. Players can enjoy a vast array of games, from slots to gambling tables. Winning big adds to the thrill!
Choosing an online casino not on GamStop, https://web.manatec.in/discovering-gambling-sites-without-gamstop-your/ can be thrilling. Players enjoy vast options like live dealer options. These platforms offer generous promotions to enhance the gaming experience. Always ensure encrypted payments while playing.
Браво, какие слова…, блестящая мысль
I Danmark findes der mange muligheder for underholdning, herunder casino uden rofus, https://kevinintveld.com/bedste-casino-uden-rofus-din-guide-til-legalt-spil/, hvor spillere kan nyde deres yndlingsspil uden bekymringer. SГҐdan en form for casino tilbyder en unik oplevelse til den moderne spiller, der Гёnsker opnГҐ chancen for underholdning uden problemer.
Az online kaszinГі MagyarorszГЎgon egyre nГ©pszerЕ±bb. A jГЎtГ©kosok szГЎmГЎra izgalmas lehetЕ‘sГ©gek kГnГЎlkoznak, mint pГ©ldГЎul a gГ©pjГЎtГ©kok Г©s a klasszikus jГЎtГ©kok. Az online casino MagyarorszГЎg, https://rakennus.jdmmediagroup.com/2026/01/22/fedezd-fel-a-legjobb-magyar-online-casinokat-4/ egyedГјlГЎllГі Г©lmГ©nyt nyГєjt mindenki szГЎmГЎra, aki szeretnГ© prГіbГЎra tenni a szerencsГ©jГ©t. A bГіnuszok Г©s promГіciГіk vonzzГЎk a jГЎtГ©kosokat, akik Гєj Г©s lehetЕ‘sГ©gekre vГЎgynak.
Жаль, что сейчас не могу высказаться – вынужден уйти. Вернусь – обязательно выскажу своё мнение.
фильмы на kinogo, https://www.penexchange.de/pen-wiki/index.php/Benutzer:UlyssesLuce46 всегда привлекают внимание зрителей. Множество жанров позволяет каждому найти что-то по душе. Сайт предлагает последние релизы, которые можно смотреть в любое время.
non GamStop websites, http://blog.paczkowscy.pl/index.php/2026/03/best-non-gamstop-casinos-discover-top-alternatives/ offer players an opportunity to enjoy online gaming without restrictions. Such websites are ideal for those seeking choice in their online gaming experience. Players can try out a variety of choices that are not available on GamStop-affiliated sites. Enjoying a vast selection of betting options creates an exciting atmosphere for enthusiasts.
new casinos not on GamStop, https://tripadikberadik.com/v4/wp/index.php/2026/03/09/discover-new-non-gamstop-casinos-a-comprehensive/ offer players unique gaming experiences. These establishments provide captivating games and luring bonuses. Players can utilize diverse options without the restrictions of GamStop.
Virtual casinos стал модным развлечением. Casino Online, https://barterkings-ug.com/complete-guide-to-the-karamba-casino-registration-3/ предоставляет особенные возможности для увлекательного досуга. Каждый игрок найдет что-то интересное для себя, открыв новые игры.
Choosing the best non GamStop casinos, https://www.isuzuleasing.com/discover-non-gamstop-casinos-in-the-uk-your/ is essential for an enjoyable gaming experience. Such venues offer a wide range of choices and generous incentives. Explore their unique features today!
Within the realm of sports betting, Mostbet sports, https://shiawaseglobal.com/discover-the-exciting-world-of-online-betting-with-40/ stands out as a reliable platform. Presenting a wide range of events, it allows users to place bets easily. Alongside competitive odds and intuitive interfaces, Mostbet sports creates an engaging experience. Also, its live betting options enhance the thrill, making it a favorite among enthusiasts.
Профессиональная веб-студия разрабатывает сайты под ключ и занимается их эффективным SEO-продвижением. Помогает бизнесу заявлять о себе в сети и увеличивать продажи. Подробнее об услугах на сайте https://inuniver24.ru/
Online casino presents a captivating journey for players. Through various games, from slots to table games, enthusiasts can enjoy thrilling moments. Engage in the fun of casino online, https://vijayarts.in/understanding-bdt-222-revolutionizing-data/ today!
Я согласен со всем выше сказанным. Можем пообщаться на эту тему.
At spille uden om rofus kan være en fantastisk måde at nyde gambling på. Mange spillere søger alternativer for de sædvanlige platforme. Når man vælger at udforske nye muligheder, åbner man op for spænding. Så er det vigtigt at finde de mest spændende spil uden om rofus, https://pestcontrolcompaniesok.com/bedste-online-casino-uden-dansk-find-din-ideelle/, så man kan få maksimal.
Los casinos online se se estГЎn popularizando muy famosos en los Гєltimos aГ±os. Con grandes opciones de juego, ofrecen entretenimiento a apostadores de todo el mundo. La facilidad de jugar desde casa realiza que Casino Online, https://investinpak.com/novibet-casino-chile-analisis-y-opiniones-finales/ sea una elecciГіn muy atractiva.
Прошу прощения, что вмешался… Я разбираюсь в этом вопросе. Приглашаю к обсуждению. Пишите здесь или в PM.
Искать новые фильмы на популярных сервисах стало проще. фильмы онлайн, https://cryptomagic.ru/birji/primexbt-copy-trading-covesting.html обеспечивают наслаждаться любимыми шедеврами в любое время и место.
Discovering a new non GamStop casino, http://www.casasarticola.com/index.php/best-non-gamstop-sites-top-picks-for-online/ can be thrilling|exciting|captivating|intriguing for players seeking fresh experiences. These platforms offer diverse games|varied gaming options|multiple game choices|a wide array of games that cater to all preferences. With enticing bonuses|attractive promotions|exciting offers|generous rewards, players are drawn in. Enjoying a seamless gaming experience|smooth gameplay|hassle-free gaming|effortless entertainment is now more accessible than ever! Don’t miss the chance to explore this vibrant world of gambling outside traditional restrictions.
The emergence of new non GamStop casino, https://centralkougei.co.jp/59157/ options has revolutionized the online gaming landscape. Players can explore a variety of games and deals that appeal to their preferences. These casinos offer an opportunity for those looking to play without restrictions.
seo агентство seo агентство .
Playing internet Casino Online Slots, http://test.902grp.com/?p=47487 is an exciting way to explore the world of gambling. With a variety of themes and specialties, players can enjoy their favorite games effortlessly.
Mostbet, https://newcenturysecurity.com/experience-the-thrill-of-online-betting-with-60/ is a popular service for gambling. With its intuitive interface and wide range of games, it attracts bettors from around the world. Enjoy thrilling matches and deals that enhance your betting experience.
online sports betting, https://visiotech-dz.com/the-ultimate-guide-to-bdok-bet-your-gateway-to-4/ is becoming immense recognition in recent years. Numerous fans are interested in placing wagers on their favorite teams. This movement is driving the growth of online platforms dedicated to this activity.
Я думаю, что Вы не правы. Предлагаю это обсудить. Пишите мне в PM, пообщаемся.
online casino uden rofus, http://159.89.198.89/youtharch-web/casino-bonus-uden-indbetaling-f-det-bedste-udbytte/ tilbyder underholdning for spillere, der Гёnsker at have det sjovt. Uden restriktioner kan du dykke ind i et stort udvalg af automater, der passer til enhver smag.
Finding leading online gaming options can be challenging. However, the best non GamStop casinos, https://thisplacematters.ca/?p=156203 provide a wide selection of games and bonuses. Players can experience thrilling table games without restrictions. Don’t miss out!
Планируя trip в Вена зимой, непременно посмотрите на рождественские ярмарки Вена 2024 и Вена рождественские ярмарки 2025 — они обеспечивают особую новогоднее настроение. Среди разнообразных смотровых площадок вена, смотровая площадка Вена на башне сумасшедших и дворец правосудия вена предлагают отличные обзоры города. Если хотите совместить экскурсию с комфортом, предлагаю воспользоваться экскурсионным трамваем Вена или электричкой S7 Вена расписание которой можно найти онлайн.
Для тех, кто знакомится с достопримечательностями Вена карта достопримечательностей будет крайне полезной, особенно если у вас немного времени — маршрут Вена за 1 день на карте помогает организовать поездку. Обязательно зайдите на Марияхильферштрассе Вена, откройте для себя венскую национальную еду, а после планируйте поездку на Вена на Новый год или проведите время у пляжа Вена. Подробную информацию и расписания ищите здесь венагид .
Los populares casinos online ofrecen diversas opciones para obtener considerables premios. Al el Online Casino, https://iconnect.zone/dmspro/2026/02/07/como-depositar-dinero-en-novibet-guia-completa/, los pueden vivir diversiones innovadores y atractivos.
When exploring various options for online gambling, non GamStop websites, https://alqubisi.com/top-casinos-not-on-gamstop-in-the-uk/ offer gamblers a chance to enjoy wagering without restrictions. These platforms offer diverse games and incentives to enhance your experience. Choose non GamStop websites for enhanced freedom and variety in your online gaming journey.
не пожалела!
Каждый фанат азиатских сериалов мечтает найти качественное место для наблюдения новых шоу. Подобные платформы предлагают разнообразный выбор дорамы смотреть онлайн, https://wstlt.ru/nasosnoe-oborudovanie/promyshlennye-nasosy/gorizontalnye-nasosy-2/gorizontalnye-nasosy-s-chastotnym-upravleniem/product-1429-detail, что позволяет наслаждаться любимыми историями. Выбирайте свой категорию и погружайтесь в мир эмоций!
Casinos Non Gamstop, https://ameenz.com/exploring-non-gamstop-uk-casino-sites-your-guide-6/ offer a unique gaming experience for players who prefer to avoid self-exclusion schemes. These establishments provide a wide range of games, from classic slots to table favorites, ensuring entertainment options. Players can enjoy their favorite activities freely minus restrictions, making these casinos an appealing choice for many gamers. With excellent promotions and diverse payment methods available, Casinos Non Gamstop continue to attract many enthusiasts looking for a thrilling adventure in the world of online gambling.
Exploring different sites not on GamStop, https://cloudocean.id/discovering-gambling-websites-not-on-gamstop-2/ can grant players more options for internet gambling. Such websites allow users to engage in betting without restrictions, ensuring a wider experience.
продвижение в google продвижение в google .
Casino Online Games, https://ashento.com/your-ultimate-guide-to-online-casino-galaxy-spins/ offer an exciting opportunity to explore thrilling games from the comfort of your home. Gamers can pick various games like slots, poker, and roulette. Using innovative technology, online casinos provide realistic environments. Enjoy accessibility and the chance to gain amazing rewards!
Many players seek virtual casinos that don’t have restrictions from GamStop. These casinos that dont use GamStop, https://app.trafficivy.com/discover-uk-online-casinos-not-on-gamstop/ provide enhanced opportunities for users wanting multiple games. Players can enjoy unique bonuses and a rich gaming experience without limitations.
The world of sports betting, http://zednik-profiobkladac.cz/domains/zednik-profiobkladac.cz/2026/01/27/exploring-8522-bet-a-comprehensive-guide-to-online-4/ provides excitement and expectation. Grasping the odds is important for effective wagering. Examine team performance and injuries to make informed decisions. Keep updated on current trends in this evolving sector.
Браво, это просто великолепная мысль
Når du leder efter underholdning i form af spil, er der mange muligheder tilgængelige. casino uden om rofus, https://help.afrisoq.com/bedste-casinoer-uden-om-rofus-din-ultimative-guide/ tilbyder et væld af sjove og innovative spil. Dette giver entusiaster chancen for at opleve et omfattende udvalg af spilvarianter uden de restriktioner som findes andre steder.
Finding reliable online casinos can be challenging, especially when searching for sites not on GamStop, https://integrasoftcr.com/stamina/list-of-casinos-not-on-gamstop-530044894/. Many players seek these platforms for an enhanced experience. These websites often provide better bonuses, making them appealing. Moreover, players can enjoy a wider selection of games, ensuring that their gaming journey remains thrilling. However, it’s crucial to choose wisely to ensure a safe gambling experience. Remember, sites not on GamStop can be a good alternative if approached responsibly.
Mostbet app, https://edwardevan.com/explore-the-exciting-world-of-mostbet-betting-and-2/ предлагает пользователям комфортный доступ к игровым возможностям. При помощи этого решения вы можете легко ставить в разных состязаниях прямо со своего телефона.
Эффективная тепло- и звукоизоляция пластиковых окон помогает снизить расходы на отопление и сделать пространство тише.
Компания «Пластик» предлагает пластиковые окна завод отличного качества с гарантией и профессиональным монтажом по Москве.
В заключении отметим дополнительные сервисы и акции, доступные клиентам «Пластик».
jugar al casino en lГnea, https://samveelpower.in/2026/02/07/descarga-la-app-de-novibet-en-chile-tu-guia/ es una experiencia emocionante la que ofrece placer desde la comodidad de tu hogar. La diversiГіn son variadas, y puedes seleccionar entre mГЎquinas tragamonedas. ВЎAtrГ©vete a jugar al casino en lГnea!
Подтверждаю. Так бывает.
фильмы на kinogo, https://koveshnikov.tpt56.ru/index.php/obratnaya-svyaz всегда радуют разнообразием жанров и сюжетов. В этом ресурсе можно найти в том числе новые релизы и востребованные картины. В этом пространстве вас ждет широкий выбор интересного контента для вечернего просмотра.
Casinos Non Gamstop, https://heni.co.in/exploring-non-gamstop-casinos-a-guide-to-11/ offer players a chance to enjoy their favorite games without restrictions. Such casinos provide an opportunity for players to gamble freely. Providing diverse games, players can try out various options seamlessly. The charm of Casinos Non Gamstop lies in their independence, granting gamers to opt for their chosen gaming environment.
Юридическая группа «Один к одному» реализует квалифицированное сопровождение по взысканию затруднительной дебиторки, защите от субсидиарных претензий и упразднению бизнес-структур с задолженностями. Практикующие арбитражные управляющие и адвокаты ведут сложные банкротные дела, обжалуют подозрительные транзакции и защищают интересы клиентов в судебных инстанциях. Полный перечень направлений размещен на https://1k1law.ru/ с детальным описанием. Профессионалы организации входят в престижные списки Российской газеты, Коммерсантъ и Право-300, предоставляют методичный сервис и продуктивное урегулирование нетривиальных юридических ситуаций.
раскрутка сайта франция prodvizhenie-sajtov-v-moskve16.ru .
Online casinos not on GamStop are expanding in popularity. Players seek freedom from self-exclusion programs. These casinos not on GamStop, https://elitetaxxrelief.com/skihiver/exploring-non-gamstop-uk-casinos-a-comprehensive-2/ offer diversity and enticing games without limitations. Enjoy the possibility to win real money while exploring new gaming experiences.
Любишь азарт? https://pfrrt.ru предлагает разнообразные игровые автоматы, настольные игры и интересные бонусные программы. Платформа создана для комфортной игры и предлагает широкий выбор развлечений.
non GamStop sites, https://stage1.nextchannelmedia.com/exploring-independent-casinos-not-on-gamstop-5/ provide a selection of wagering options that draw in players. Without the limitations of GamStop, these platforms allow users to experience their favorite games unrestricted.
Online casinos offer a thrilling | exciting | entertaining | captivating way to enjoy gambling from home. With diverse games, players can indulge in slots, poker, and blackjack at their convenience. Casino Online, https://jugaaduinsan.com/discover-the-excitement-of-corgislotcasino-2/ provides bonuses and promotions to enhance the overall experience, making it more rewarding than ever.
Между нами говоря, я бы обратился за помощью к модератору.
At spille online kan være en fantastisk oplevelse, især når man vælger et casino uden rofus, https://tdls2.com/?p=56790. Dette casino giver muligheder for spil uden restriktioner. Spillerne kan drage fordel af mange spil og tilbud, der forbedrer spiloplevelsen. Vælg det, der passer til dine ønsker og start på eventyret!
online casino betting, http://www.everydayimport.com/todo-lo-que-necesitas-saber-sobre-alanobet-mx-tu-3/ offers an captivating experience for players. Participating in various games, including slots and table games, can yield substantial rewards while enjoying the flexibility of online play.
Mostbet App, https://winnerboutique.com/discover-exciting-betting-opportunities-at-mostbet-2/ предоставляет удобный доступ к беттингу на множество события. С помощью этого приложения пользователи могут удобно делать ставки, следить за результаты и увеличивать бонусы. Теперь ставки стали легче, чем когда-либо!
el mejor casino en lГnea, http://www.lottemeijerphd.nl/casinoonline07023/metodos-de-pago-en-colombia-todo-lo-que-necesitas-2/ ofrece un ambiente emocionante para los jugadores. Gracias a opciones de alta calidad y promociones atractivas, cada jugador puede encontrar algo especial.
купить фасадную плитку под кирпич идеально подходит для создания прочной и эстетичной облицовки дома, имитируя натуральный кирпич при минимальных затратах на монтаж и уход.
Она сочетает декоративный вид с практичностью и долговечностью.
non GamStop websites, http://www.magdalena-doering.de/exploring-casinos-without-gamstop-a-comprehensive/ offer a unique solution for players who want to enjoy online gaming without restrictions. These platforms grant various games, incentives, and protected environments. Explore non GamStop websites for a thrilling experience.
посмотрю што это и с чем ево едят
Хотите насладиться захватывающими историями? дорамы смотреть онлайн, https://update.hf25u.link/arpa_D72xmZ_document — отличный выбор. Рти сериалы погружают зрителя РІ реальность эмоций Рё событий. Более того, каждый серия наполняет зрителя живописными сценами Рё значительными персонажами. РќРµ дайте уйти шанс познать культуру Рё искусство корейского РєРёРЅРѕ!
Casinos Non Gamstop, https://lapitavanuatu.com/discovering-the-best-casinos-not-on-gamstop-uk-2/ offer players a unique opportunity to experience online gaming without restrictions. The platforms present a variety of games, ensuring a wide selection for all tastes. Players can relish the thrill of winning as they explore thrilling features.
online casino not on GamStop, http://www.pisarevo.com/exploring-the-existence-of-non-gamstop-casinos/ offers players a unique opportunity to enjoy gaming without restrictions. This kind of casinos present a diverse selection of entertainment and promotions. Individuals can experience engaging slots and live dealer experiences in a reliable environment.
Если вы планируете купить памятник в Могилеве, обратите внимание на изделия из натурального гранита. Этот материал отличается долговечностью, стойкостью к погодным условиям и благородным внешним видом. В каталоге представлены как классические вертикальные стелы, так и эксклюзивные мемориальные комплексы. Профессиональное изготовление памятников в Могилеве включает разработку индивидуального эскиза, качественную гравировку и установку на кладбище: надгробные памятники
non GamStop casino sites, https://www.drukletters.com/stamina/exploring-casinos-not-blocked-by-gamstop/ provide a unique gaming experience for players looking to bypass UK regulations. These sites give greater flexibility in terms of options for gaming. Players can experience diverse deals not found on traditional platforms.
Online Casino, https://bisecgroupe.com/explore-bounty-reels-uk-your-ultimate-guide-to/ – Online Casino стал популярным СЃРїРѕСЃРѕР±РѕРј развлечения для миллионов людей. Пользователи наслаждаются различными вариантами РёРіСЂ Рё возможностью заработать. Доступность участия делает его востребованным для всех.
Если вы хотите купить летнюю резину в интернет магазине, то у нас вы найдете выгодные предложения и широкий ассортимент качественных моделей.
Выбор летней резины в Санкт-Петербурге требует внимательного подхода и оценки множества факторов.
это все, что нужно!!!
I dag vælger mange at nyde sjove aktiviteter. spil uden om rofus, https://staluminox.pl/2026/02/16/betting-uden-om-rufus-en-guides-til-sikker-spil/ tilbyder en spændende måde at tilbringe tid med venner. Det kan være en fantastisk mulighed for at dele grin samtidig med nyde godt selskab. Gennem sjove spil kan man skabe skønne oplevelser.
online casino sports betting, https://wp.niermann-consult.de/2777bet-bd-your-ultimate-betting-destination-2/ provides a thrilling experience to engage in various events. With numerous platforms available, bettors can choose their favorite games. This ease of online platforms makes it simple for players to follow their passion and try their luck on favorite athletes.
оптимизация и продвижение сайтов москва оптимизация и продвижение сайтов москва .
Cada vez mГЎs personas disfrutan de la experiencia de jugar en un Casino Online, https://www.villayork.it/2026/02/07/jugabet-app-chile-tu-guia-definitiva-para/ utilizando su computadora o dispositivo mГіvil. Esta tendencia ha crecido y revolucionado la forma en que los jugadores participan de sus juegos favoritos.
non GamStop casino sites, http://eba.853.myftpupload.com/the-rise-of-non-gamstop-casinos-a-comprehensive-3/ offer players an opportunity to enjoy thrilling gaming experiences without the restrictions imposed by UK gambling authorities. These platforms often feature inviting bonuses and a wide range of games, making them great for players looking for variety.
mostbet casino, https://mediumaquamarine-wolf-155734.hostingersite.com/how-to-access-your-mostbet-account-a-comprehensive/ offers an exciting gaming experience. Players can relish a variety of options, from slot machines to gambling tables. Join now and leverage fantastic bonuses!
Абсолютно с Вами согласен. В этом что-то есть и мне кажется это отличная мысль. Полностью с Вами соглашусь.
поисковое продвижение, https://bremme-wohnen.de/img_4201/ выступает ключевым методом для повышения видимости сайта. Эффективная стратегия влечет увеличенное число пользователей. Анализ главных слов и улучшение контента способствуют успеху.
Playing at an internet casino not on GamStop provides gamblers with the chance to enjoy a diverse range of options. These platforms often offer generous bonuses and incentives, making the experience even more engaging. Whether you’re into table games, the selection is vast. Join an online casino not on GamStop, https://amzprofitsites.com/discover-the-best-casinos-not-on-gamstop-in-the-uk-2/ and enjoy a unique gaming adventure.
independent UK casinos, http://czb.grafikmk.pl/exploring-independent-uk-casino-sites-a-3/ offer a unique gaming experience for gamblers. Unlike large chains, these venues specialize in personalized service and a varied selection of games. Visitors can enjoy cozy atmospheres and challenging gameplay, making them a great choice for thrill-seekers. Independent UK casinos commonly showcase local culture, creating a distinctive vibe that sets them apart from their corporate counterparts.
Услуга приемки квартиры актуальна на любом этапе покупки недвижимости. Особенно важна она при сдаче дома. Эксперт знает особенности новостроек. Проверка проводится без спешки. Все замечания оформляются корректно. Клиент получает подробный отчет, подробнее по ссылке, приемка квартир Челябинск. Если вы хотите заселиться без лишних доработок, стоит начать с приемки квартиры. Эксперт выявит все недочеты. Это удобно и практично. Ознакомьтесь с информацией о приемке квартир
Промышленная вентиляция и кондиционирование — основа комфортного микроклимата на производстве и в коммерческих помещениях. Компания ВентТехника из Екатеринбурга специализируется на поставке и монтаже вентиляторов серий ВЦ, ВР, ВКР, приточно-вытяжных установок и климатического оборудования. В ассортименте — центробежные, осевые, канальные вентиляторы, тепловые завесы и системы автоматики. Подробный каталог представлен на https://venttehnica.ru/ Грамотный подбор оборудования и профессиональный монтаж обеспечивают эффективную работу систем на долгие годы.
Полностью разделяю Ваше мнение. Это хорошая идея. Готов Вас поддержать.
online casino uden rofus, http://cms.ddmi.be/wordpress/2026/02/16/udenlandske-casinoer-med-dansk-licens-en-guide-til-5/ tilbyder spillere en unik mulighed for at nyde deres yndlingsspil uden besvær. Mulighederne er mangfoldige, fra slots til kortspil. Det er en super måde at nyde tiden på.
Online Casino Slots, https://www.wightplace.co.uk/2026/02/09/bullspins-online-casino-uk-your-ultimate-gaming-12/ offer thrills for players seeking big wins. With countless themes and features, each game provides distinct gameplay. Players can enjoy the enjoyment of each round while trying their luck!
When exploring the realm of online gambling, non GamStop sites, https://nextoons.bex.jp/2026/03/09/929919/ present an alternative to traditional platforms. These sites enable players to experience thrilling games without the restrictions imposed by GamStop. Identifying non GamStop sites can expand your play options significantly.
When you select to play online casino, http://www.grupogrago.com/exploring-1777-bd-a-comprehensive-overview/, you enter a world of excitement. With various games available, you can experience the joy of winning from the comfort of your home. Embrace the possibility to try new games and strategies. Join today and start your gaming journey!
The rise of new non GamStop casino, https://carcredit36.com/2026/03/09/exploring-non-gamstop-casinos-a-guide-for-players-2/ options presents players exciting opportunities. These casinos let users to enjoy their favorite games without GamStop restrictions, ensuring a freer gaming experience. Players can find a variety of games, from slots to table games, all while enjoying generous bonuses and promotions. Choosing new non GamStop casino means embracing freedom in online gambling.
When searching for quality gaming options, look no further than the best non GamStop casinos, https://content-qa.fortuneconferences.com/discover-non-gamstop-online-casinos-freedom-to/. These venues provide an exciting array of choices without the restrictions of GamStop. Players can enjoy freedom while playing.
seo partner program prodvizhenie-sajtov-v-moskve16.ru .
Los casinos online entregan una experiencia vivencia excepcional con diversiГіn diversos. AdemГЎs, ofertas interesantes potencian el placer. ВЎVisita Online Casino, https://asesoriasbetancur.com/como-descargar-la-app-jugabet-para-android-guia/ y disfruta!
Абсолютно с Вами согласен. В этом что-то есть и идея хорошая, поддерживаю.
WalletCloud wallet, https://bushtech.co.za/product/double-cab-fridge-cage/ provides a secure way to manage your electronic assets. With its user-friendly interface, users can efficiently access their assets anytime. The state-of-the-art security features ensure that your information is protected against threats. Choose WalletCloud wallet for an optimal experience in crypto finance.
Mostbet sports, https://codecanyondemo.work/wcgfi/2026/02/24/the-ultimate-guide-to-betting-on-mostbet-2/ offers exciting opportunities for gambling. Fans can explore a wide range of games across various sports. Join the adventure and make your predictions today!
independent UK casinos, https://quiz.ask.careers/the-rise-of-independent-online-casinos-a-new-era-50/ present a unique gaming experience unlike large corporate establishments. They often include a cozier atmosphere, tailored services, and unique game selections. Gambling enthusiasts appreciate the community feel, making independent UK casinos a favored choice for many.
Юридическая группа «Один к одному» реализует квалифицированное сопровождение по взысканию затруднительной дебиторки, защите от субсидиарных претензий и упразднению бизнес-структур с задолженностями. Действующие управляющие и правозащитники сопровождают запутанные процедуры несостоятельности, оспаривают сомнительные сделки и представляют доверителей в арбитражных судах. Полный перечень направлений размещен на https://1k1law.ru/ с детальным описанием. Профессионалы организации входят в престижные списки Российской газеты, Коммерсантъ и Право-300, предоставляют методичный сервис и продуктивное урегулирование нетривиальных юридических ситуаций.
new casinos not on GamStop, https://seminars.unj.ac.id/iscet2022/?p=123418 offer players unique gaming experiences. Such establishments provide thrilling games and appealing bonuses. Players can exploit diverse options without the restrictions of GamStop.
Discover the thrill of playing at a new non GamStop casino, https://waterfallhikeusa.com/stamina/understanding-what-gambling-sites-are-not-a-5/, where you can enjoy a variety of games without restrictions. These venues offer an exciting selection that will keep you entertained. Explore unique bonuses and promotions that enhance your gaming experience. Enjoy the freedom to play top titles anytime you want, without anxiety about limitations. Dive into this fascinating world and experience gaming like never before!
в восторге, автору респект)))))
Spiloplevelsen i et casino uden om rofus, https://luckytraders.biz/udforsk-danskerne-casinoer-uden-rofus/ er unik, da den giver dig frihed til at nyde dine yndlingsspil uden begrænsninger. Denne har mange entusiaster set glæden ved at spille online. Utallige casinoer præsenterer rafte, som gør det endnu mere interessant at spille.
Online Casino Games, https://edelltha.com.br/index.php/2026/02/09/the-excitement-of-casino-007-a-premier-gaming/ offer captivating experiences for players. With countless options available, one can discover games like slots, poker, and blackjack. These games provide fun while also introducing opportunities to win.
online casino, https://phoenix-emperor.com/the-rise-of-1777-bd-a-comprehensive-overview-5/ дарит игрокам уникальные возможности для увлечения. Азартные игры сочетают волнение и шанс на выигрыш. Каждый увлекательный опыт приносит радость.
Жаль, что сейчас не могу высказаться – очень занят. Освобожусь – обязательно выскажу своё мнение по этому вопросу.
игры, http://mos-it.ru/index.php?subaction=userinfo&user=uxalaxuxite – В мире видеоигр каждый встретит что-то интересное. Игры — это не просто способ заполнять время, это настоящие приключения, в которые необходимо погружаться с головой. Например, игра “Искатели сокровищ” предлагает игрокам уникальную возможность изучать древним миром, собирая артефакты и раскрывая загадки. Кроме того, многие студии предлагают коллективное прохождение, что позволяет возможность сотрудничать с семьей.Также нельзя не упомянуть о изображении, ведь современные игры удивляют своими реалистичными пейзажами. Каждый грандиозный релиз несет в себе инновационные технологии, которые делают игровой опыт уникальным. Не стоит забывать и о звуках, которая настраивает нужную атмосферу.Каждый любитель игр найдет свой направление. Так что не стесняйтесь открывать новые игровые возможности в мире игр.
Sprawdz poradnik analogowa kamera fpv, jesli szukasz najlepszych wskazowek przy wyborze kamery FPV na start.
Obsluga roznych formatow i opcja nagrywania zewnetrznego zwieksza elastycznosc pracy.
jugar al casino en lГnea, https://e-learn.viser.edu.rs/wordpress/index.php/2026/02/07/jugabet-cl-app-la-mejor-experiencia-movil-en/ es una experiencia entretenida que atrae a miles de jugadores cada dГa. Las alternativas son amplias, desde slots hasta pГіker en lГnea. AdemГЎs, las ofertas son interesantes, lo que aumenta la interacciГіn de jugar.
non gamstop casino, https://bsq.cl/exploring-non-gamstop-casinos-a-comprehensive-151/ offers players an alternative way to enjoy their favorite games. These sites provide attractive incentives that improve the gaming experience. Without restrictions, players can get immersed in a vast selection of options.
Mostbet, https://jeroenwolfs.nl/discover-exciting-betting-opportunities-at-mostbet-8/ is a popular website for online betting and gaming activities. It offers a wide selection of sports events and casino games. Users can enjoy live betting options for an immersive experience.
Many players seek betting platforms that are not restricted by GamStop. sites not on GamStop, https://paskatina.lt/discover-the-best-uk-non-gamstop-casinos-562070972/ offer various games for gamers, offering a thrilling experience without limits.
non GamStop websites, https://magme.madeinitalyslc.it/2026/03/08/exploring-uk-online-casinos-not-on-gamstop-5/ present players a chance to enjoy online gaming without restrictions. These platforms appeal to users looking for a wider selection of games. With unique features, these platforms ensure a customizable gaming experience.
https://it-specials.ru
https://nov-akl.ru
плитка под кирпич для наружной отделки идеально подходит для создания прочной и эстетичной облицовки дома, имитируя натуральный кирпич при минимальных затратах на монтаж и уход.
Такой материал даёт вид натурального кирпича при меньшей стоимости и большем удобстве монтажа.
https://stroy-plyus.ru
If you’re seeking the best non GamStop casinos, http://phs.intconference.org/2026/03/09/the-best-uk-casinos-not-on-gamstop-your-ultimate/, you’re in luck. These sites offer a vast array of games|options|choices|selections and generous bonuses|incentives|rewards|promotions. Players can enjoy a thrilling experience|adventurous time|exciting journey|memorable visit without the limitations imposed by GamStop. Explore the variety|range|assortment|selection of games available and take advantage of exclusive promotions|offers|deals|bonuses that enhance your gameplay. Non GamStop casinos provide a unique opportunity|chance|option|possibility for players to enjoy gambling freely.
Боюсь, что я не знаю.
I dag er der mange muligheder for dem, der ønsker at spille spil uden om rofus, https://www.720transform.com/2026/02/17/udenlandske-spillesider-den-ultimative-guide-til/. Det kan være en spændende måde at have det sjovt. Du kan opdage et væld af interessante titler, der giver mulighed for nye eventyr. Uanset hvilken type spil du vælger, der er nogle muligheder at prøve.
In the world of gambling, casino sports betting, http://joesflightschool.com/2026/02/exploring-dreamgf-ai-the-future-of-virtual-21/ offers an exciting opportunity. Players can make wagers on various matches, enhancing the thrill of watching. With the rise of digital services, it has become easier than ever to get involved in casino sports betting and enjoy the action.
Куршавель — это популярный французский горнолыжный курорт, который многие воспринимают с роскошью и утончённой атмосферой. Если вы интересуетесь не только горами, но и культурой Франции, точно стоит посетить Париж, где можно посетить Нотр Дам де Пари и Собор Парижской Богоматери, а также пройтись по площадям Гревская площадь и Площадь Согласия. Для поклонников искусства и истории будут интересны дворец Правосудия Париж, Вандомская колонна и, несомненно, знаменитый Булонский лес. Детальнее о ключевых местах и округах Парижа, таких как 15 и XIX округ Парижа, можно найти тут замки луары .
Не стоит забывать и о других памятниках Франции, например, о замках Луары и величественных дворцах Версаля с Малым Трианоном, отождествляемого с Марией-Антуанеттой (дата и место смерти которого тоже составляют исторический интерес). Тем, кто желает смешивать культуру и стиль, будет познавательно знать про Коко Шанель и «Кафе де Флор» — прославленное место в Монпарнасе. И, конечно, исторические соборы, такие как Руанский собор, Сен Дени, Страсбургский собор, и незабываемые локации на Корсике подарят незабываемые впечатления.
Online Casino, https://lightgray-raccoon-405711.hostingersite.com/discover-bubblesbet-online-casino-uk-your-ultimate/ предоставляет уникальные возможности для игры. Любители азартных игр могут исследовать широким играм, в число которых входят слоты, покер и блэкджек. Бонусы также цепляют внимание и поддерживают шансы на выигрыш.
ОГО , ну наконецто
В последние годы индустрия гейминга стремительно развивается, предлагая поклонникам все новые возможности. игры, http://ad-vance.ru/communication/forum/user/53429/ становятся все более увлекательными, благодаря современным технологиям и инновационным подходам к созданию контента. Разработчики применяют различные элементы, такие как машинное обучение, чтобы создать действительно захватывающие приключения.Все больше пользователей выбирают многопользовательские игры, которые позволяют им взаимодействовать с другими игроками по всему миру. Такие проекты становятся настоящим трендом в мире развлечений. Особенно модны игры с открытым миром, где участники могут исследовать огромные пространства, выполнять квесты и находить скрытые сокровища.С развитием мультимедиа также возрастает интерес к цифровой реальности. Эти технологии открывают новые горизонты в игровой индустрии, позволяя погрузиться в пространство игры как никогда раньше. Идеи с необычным подходом к геймплейю становятся передовыми, и игровые компании активно работают на создание уникального пользовательского опыта. Таким образом, будущее игр выглядит ярким и многообещающим, а перспективы по-прежнему вдохновляют создателей и игроков.
Si buscas el mejor casino en lГnea, https://cuentos.juanramonjimenez.es/wordpress/?p=37404, encontrarГЎs una amplia variedad de juegos que ofrecen emociГіn y entretenimiento. Las tragamonedas son solo algunas de las opciones disponibles. AdemГЎs, las promociones especiales hacen que la experiencia sea aГєn mГЎs atractiva.
Choosing wagering websites can be tricky, especially if you want to explore non GamStop websites, https://blognew.perseus.com.br/exploring-casino-options-outside-gamstop/. These platforms offer players more choices and access to a range of games without restrictions.
Finding reliable gambling options can be challenging, especially for those seeking alternatives. sites not on GamStop, http://www.carbossonline.com/exploring-casinos-not-blocked-by-gamstop/ provide gamblers with the chance to enjoy their favorite games without restrictions. These platforms often offer captivating promotions and a wide variety of slots, ensuring a fresh experience every time. For those looking to escape bans, these sites offer an appealing solution, combining enjoyment with autonomy.
The expanding trend of non gamstop casino, https://heni.co.in/discover-the-benefits-of-non-gamstop-casinos-7/ offers players an captivating alternative to traditional gaming. By using these platforms, players can enjoy more extensive options and dynamic rules. non gamstop casino is likely to alter the online gambling landscape.
The Mostbet app, https://recruit.ato-co.jp/mostbet24021/experience-excitement-with-mostbet-your-ultimate/ offers a remarkable platform for gaming, allowing users to make wagers on multiple competitions. With a user-friendly interface, it ensures an enjoyable interaction for all players.
De slot is, wat je noemt, ‘hoog volatiel’. Geen getrut met allerlei kleine prijsjes, maar gewoon grote winsten of met verlies naar huis. Het is dus alles of niks. De beste goudschatten zijn goed voor een knallende 5000x je inzet. De gratis spins bonus van Buffalo King is waar de jongens van de mannen worden gescheiden. Deze bonus feature kan je maken of breken. Het thema van Pragmatic’s Great Rhino Megaways is vrij bekend. Zo kan deze online gokkast gezien worden als een remake van Raging Rhino Megaways die spelprovider Williams Interactive heeft ontwikkeld. De gokkast heeft 6 rollen met minimaal 2 en maximaal 7 symbolen, waarmee je maximaal 117.649 Megaways kunt draaien. Op zoek naar de leukste gokkasten en gokkast tips om te gokken? Bekijk hier het grote aanbod is fruitautomaten en andere gokkasten die online te spelen zijn. Verdien gratis spins of start zelf direct met spelen!
https://mujernuncapermitas.com/nv-casino-mobiele-ervaring-en-review-voor-spelers-in-nederland/
Hi there! I could have sworn I’ve been to your blog before but after looking at many of the articles I realized it’s new to me. Anyways, I’m certainly delighted I discovered it and I’ll be book-marking it and checking back frequently! Here is a striking example of modern trends – the introduction of modern methods plays a decisive importance for the personnel training system corresponding to the pressing needs. The significance of these problems is so obvious that the further development of various forms of activity requires an analysis of the distribution of internal reserves and resources! En sevdiğim slot oyunu Buffalo King Megaways, her spin heyecan verici ve kazançlı. Here is a striking example of modern trends – the introduction of modern methods plays a decisive importance for the personnel training system corresponding to the pressing needs. The significance of these problems is so obvious that the further development of various forms of activity requires an analysis of the distribution of internal reserves and resources!
https://guvdsk.ru
https://linux-saratov.ru
https://frostmarket.su
Вы допускаете ошибку. Могу это доказать. Пишите мне в PM, пообщаемся.
At spille på casino uden rofus, https://salvatorefiorillodentalestudio.es/find-de-bedste-udenlandske-casinoer-til-danske/ kan være en spændende oplevelse. Det viser spillere mulighed for sjov uden komplikationer. Find talrige spil for at få den enestående oplevelse.
заказ курсовых работ заказ курсовых работ .
“spintax_text”: “Если вы намечаете поездку в Париж, не пропустите на блошиные рынки Парижа — они прекрасно отражают атмосферу города и порой прячут настоящие сокровища. Для тех, кто увлекается культурой, бесплатные музеи Парижа — прекрасная возможность познакомиться с искусством без больших расходов, рекомендую посетить музей Массена и его виллу. Также важно понимать, в каких районах Парижа можно гулять, например, 15 округ является достаточно комфортным для туристов. Также, если хотите узнать, как самостоятельно доехать до Версаля из Парижа самостоятельно, здесь есть подробные советы и маршруты районы парижа по безопасности .”
“Не упустите из виду важные туристические моменты — например, сколько чаевых оставлять во Франции: советы для туристов позволят избежать неловких ситуаций в ресторанах. Для тех кто любит историю советую побывать в замки Луары и обязательно посетить Лувр, где можно полюбоваться самыми известными экспонатами. На память о городе можно сделать фото с известной скульптурой человека, проходящего сквозь стену, а вечером побродить у дворца Трокадеро с видом на Эйфелеву башню.”
online casino, https://indiabettingexchange.in/discovering-kupid-ai-the-future-of-virtual-4/ delivers a exciting experience for players. Countless games are available, providing entertainment for everyone. Seize the chance to win big payouts. Join today!
new non GamStop casino, https://www.dataprotect.sg/discovering-online-casinos-not-on-gamstop-your/ offers players a unique opportunity to enjoy gambling without restrictions. These platforms provide thrilling games and lucrative bonuses. Players can explore wide-ranging options that appeal to every taste. Enjoy a different experience in the gambling world!
non GamStop sites, https://demo.booknetic.com/2026/03/08/explore-casinos-not-with-gamstop-your-ultimate/ provide a extensive range of gambling options. Participants can relish their beloved games without constraints. With alluring bonuses, these sites enhance the overall gaming experience. Non GamStop sites promise that players have accessibility to top-quality games from renowned providers, making it a joyful choice for avid gamers.
Эта тема просто бесподобна 🙂 , мне нравится )))
игры, http://bl.com.tw/index.php?title=%D0%9F%D0%BE%D1%81%D0%BC%D0%BE%D1%82%D1%80%D0%B5%D1%82%D1%8C%20%D0%BC%D1%83%D0%BB%D1%8C%D1%82%D1%84%D0%B8%D0%BB%D1%8C%D0%BC%D1%8B завоевали популярность в современном мире и стали неотъемлемой частью жизни многих людей. Существует множество жанров, которые могут удовлетворить различные предпочтения. Так, стратегический жанры предлагают игрокам уникальные возможности. Каждая игра предоставляет игроку шанс проявить свои способности и умения, а также погрузиться в увлекательные миры.Одним из самых популярных направлений является игра “The Legend of Zelda”, которая принесла игрокам невероятные приключения и загадки. В этом окружении игроки могут исследовать огромные локации, находить уникальные предметы и решать сложные головоломки. Игра постоянно обновляется, что делает ее интересной даже для опытных геймеров.Другие жанры также привлекают внимание зрителей. Спортивные игры позволяют окунуться в другие роли и испытать себя в различных обстоятельствах. Каждый игрок найдет что-то по своему вкусу, будь то захватывающие сражения или дружеские состязания. Важно упомянуть, что игры не только развлекают, но и улучшают мышление, учат работать в команде и принимать быстрые решения. В эпоху высоких технологий мир игр будет лишь расти и развиваться, открывая новые горизонты для каждого, кто ищет приключений.
Casino Online, https://judolimon.com/2026/02/09/how-to-navigate-the-boomingslots-casino-2/ – Internet gaming привлекает множество РёРіСЂРѕРєРѕРІ СЃРѕ всего РјРёСЂР°. Casino Online предлагает широкий выбор РёРіСЂ, например покер, блэкджек Рё слоты. Возможность Рє играм РЅР° деньги РІ любое время интересует новых пользователей.
El universo del juego ha transformado con la llegada del Casino Online, https://smkislamiyahadw.sch.id/2026/02/06/slottica-casino-chile-metodos-de-pago-y/. Recientemente, los aficionados pueden experimentar de la emociГіn desde casa.
In the world of online gambling, many players seek variations beyond traditional constraints. A non gamstop casino, https://emplifyhomes.com.au/2026/02/08/understanding-non-gamstop-casinos-a-comprehensive-5/ offers a special chance to explore thrilling games without the typical limitations. This autonomy attracts fans looking to enjoy their favorite activities without interruption. With multiple game selections, players can find something that suits their preferences.
Качественное SEO https://outreachseo.ru продвижение сайта для бизнеса. Наши специалисты предлагают эффективные решения для роста позиций в поисковых системах. Подробнее об услугах и стратегиях можно узнать на сайте
Recently, the demand for casinos that dont use GamStop, https://www.aurumevent.com/top-casinos-that-arent-on-gamstop-discover-your/ has increased. Players are looking for options that allow users to enjoy gaming without restrictions. Those platforms give engaging experiences and valuable bonuses. Players can consequently find a more diverse range of games as they maintain freedom over their activities.
Bitfortune casino, http://naturalfd.co.kr/g5/bbs/board.php?bo_table=free&wr_id=585030 offers an enjoyable environment for gamers. With diverse gaming options, players can easily find their favorites. Join today and take advantage of great promotions that enhance your gameplay.
Точный ответ
online casino uden rofus, https://www.encantesdonordeste.com.br/casino17023/f-gratis-spins-p-udenlandske-casinoer-din-guide/ tilbyder en fantastisk mulighed for at spille aktivitet uden grænser. Dette skaber spillere plads til at nyde deres yndlingsspil uanset om hvor de befinder sig.
купить курсовую купить курсовую .
Finding the best non GamStop casinos, https://cornerstoneraleigh.org/2026/03/09/exploring-sites-not-registered-with-gamstop-a/ can be challenging, yet rewarding. Players often seek alternatives to enjoy gaming without restrictions. These venues offer thrilling experiences, profitable bonuses, and more extensive selection of games. Enjoy the freedom and excitement these casinos provide!
non GamStop casino sites, https://mood.com.tr/discover-the-best-casino-sites-without-gamstop-3/ offer players a unique chance to enjoy their favorite games without restrictions. These platforms grant a wide selection of options, featuring slots to table games. Users can revel in the excitement of online gaming in a different regulated environment. With compelling bonuses, non GamStop casino sites lure many enthusiasts seeking freedom in their gaming experience.
Online medical stores make it easy to order medicine online without visiting a pharmacy. Customers can browse a wide range of healthcare products, upload prescriptions and get medicines delivered directly to their home. This convenient service helps people manage their treatment on time while saving effort and travel https://www.fta.edu.au/vocational-education-vet-training/
casino online, https://suadienlanhthaibinh.net/plongee-dans-l-univers-du-manga-casino-1939668033/ – Internet gaming привлекает неравнодушие РёРіСЂРѕРєРѕРІ СЃРѕ всего РјРёСЂР°. РРіСЂС‹ РІ интернете предлагают многообразные возможности для удовлетворения. Люди РјРѕРіСѓС‚ радоваться богатым меню РёРіСЂ без необходимости покидать РґРѕРј.
Я думаю, что Вы не правы. Я уверен. Могу отстоять свою позицию. Пишите мне в PM, поговорим.
игры, https://funsilo.date/index.php?title=%D0%A1%D0%BC%D0%BE%D1%82%D1%80%D0%B5%D1%82%D1%8C%20%D0%BA%D0%B0%D1%80%D1%82%D0%B8%D0%BD%D1%8B – Игры занимают важное место в нашей жизни. Фактически любой из нас хотя бы раз пробовал участвовать различные геймерские проекты. Когда речь идет о играх, сразу вспоминаются увлекательные характеристики и незабываемый опыт. Для многих они стали шлюзом в альтернативные миры.Солидный выбор жанров игр дает возможность каждому найти что-то по душе. От экшенов до мобильных проектов — выбор на самом деле огромен. Каждый день большое количество игроков по всему миру включают свои любимые игрушки и погружаются в действие игры.Неудивительно, что игровая индустрия развивается с каждым днем. Студии стремятся создавать всё новые и новые проекты, чтобы удовлетворить интересы игроков. Каждый новый игры — это попытка предложить что-то совершенно необычное.
Discover the thrill of experiencing Casino Online Slots, https://dronecityconnect.es/big-win-box-casino-your-gateway-to-exciting/, where fun meets the chance to win. With vibrant graphics and various themes, players can immerse themselves in a world of ventures.
El mundo de los apostadores online ha crecido significativamente en los Гєltimos aГ±os. Online Casino, https://euphoriacenter.gr/%ce%bc%ce%b7-%ce%ba%ce%b1%cf%84%ce%b7%ce%b3%ce%bf%cf%81%ce%b9%ce%bf%cf%80%ce%bf%ce%b9%ce%b7%ce%bc%ce%ad%ce%bd%ce%bf/doradobet-peru-guia-completa-para-apostar-con-7/ brinda una amplia gama de actividades para entretenimiento y ganancias.
non gamstop casino, http://unik-web.com/the-rise-of-non-gamstop-casinos-a-comprehensive-22/ provides players with various selections for engaging with online gaming. These locations often feature greater varieties of games, offering excitement and enjoyment without limitations. Players can find unique deals that enhance their gaming experience.
In recent years, the demand for casinos that dont use GamStop, https://techners.net/trusted-casinos-not-on-gamstop-your-guide-to-safe-2/ has grown. Players are seeking options that allow users to enjoy gambling without restrictions. Such platforms deliver exciting experiences and rewarding bonuses. Players can therefore explore a wider range of games in the process they maintain autonomy over their play.
online casino not on GamStop, https://lwpkenya.stockpesa.com/best-casinos-not-on-gamstop-discover-top-gaming/ offer a thrilling alternative for players seeking variety. These platforms supply diverse games, entertaining bonuses, and convenient payment options. Players can savor gambling without restrictions on their activity.
покупка курсовой покупка курсовой .
Bitfortune casino, http://biz.godwebs.com/bbs/board.php?bo_table=free&wr_id=344949 offers exciting games for participants. With a user-friendly interface, it’s convenient to find your favorite games. Join Bitfortune casino today and enjoy top-notch assistance.
Amidst the thrilling world of casino sports betting, https://miku-miku.net/oz-wins-casino-elevate-your-gaming-experience/, players can enjoy the adrenaline of making bets on their beloved teams. Grasping the probabilities is essential for placing informed decisions.
Для строительства дорожного основания мы заказали щебень из гравия, чтобы обеспечить прочное и ровное покрытие.
Присутствие большого количества глины или пыли ухудшает сцепление с вяжущими материалами и снижает прочность.
Ищете натяжные потолки краснодар — наши специалисты обеспечат качественный монтаж и выгодные цены.
Натяжные потолки приобретают широкое распространение среди краснодарцев, стремящихся к современному дизайну.
Глянцевые и матовые поверхности создают разные визуальные эффекты и настроение комнаты.
Ясное соглашение по времени выполнения и гарантиям предотвращает возможные проблемы.
Простота ухода за потолками делает их практичным выбором для современных домовладельцев.
Богатый выбор фактур и оттенков даёт возможность реализовать любые дизайнерские задумки.
jugar al casino en lГnea, http://www.sagesofrpg.com/2026/02/06/opinion-sobre-la-aplicacion-doradobet-apuestas-en/ – Apostar al casino en lГnea ha crecido en los Гєltimos aГ±os. Proporciona acceso y la opciГіn de lograr premios sin salir de tu hogar. No obstante, es importante entrar de manera cautelosa y decidirse por plataformas confiables para tener una experiencia gratificante.
Casino Online Games, http://baya.anohadigital.com/the-ultimate-guide-to-casino-big-win-box-uk-4/ предлагают игрокам уникальную возможность наслаждаться азартом, РЅРµ выходя РёР· РґРѕРјР°. Виртуальные казино обладают разнообразные выбор. Азартные РёРіСЂРѕРєРё РјРѕРіСѓС‚ отдавать предпочтение играми СЃ карточками или живым казино. Рто дает возможность участвовать РІ любое время!
По моему мнению Вы ошибаетесь. Могу отстоять свою позицию. Пишите мне в PM, пообщаемся.
Online casinoer bliver hurtigt, særlig mange brugere leder efter chancer til casino uden om rofus, http://ampnvolt.com.my/?p=351903. Det nye|;|:] tilbyder forbedrede oplevelser uden skræmmende.
The emergence of online casinos, https://tongxiao.tech/archives/559382 has transformed the gaming industry. Players can now enjoy their favorite games from the luxury of home. With advanced technology, online casinos offer an extensive range of games.
Вейпінг, https://www.amherstcommunitychildcare.org/2017/06/activities-using-the-five-senses-with-clear-example-2/ стає РІСЃРµ популярнішим серед молоді. Шанувальники вейпінгу цінують багатогранність смаків та методів РєСѓСЂС–РЅРЅСЏ. Це альтернатива традиційним сигаретам, що захоплює багатьох. Однак важливо перевіряти потенційні СЂРёР·РёРєРё для Р·РґРѕСЂРѕРІ’СЏ.
online casino, https://egs.tmal1020.com/kupid-ai-revolutionizing-online-connections-with/ supplies an entertaining way to take part in games from the ease of your own home. With various options available, you can find games that suit your likes.
This clarified a lot for me — check it out https://www.rilezzz.com/read-blog/44328_kupit-diplom-zaneseniem-reestr.html
el mejor casino en lГnea, https://test.gameplaying.info/home/como-retirar-en-soles-guia-completa-para/ presenta una variada selecciГіn de actividades. Puedes experimentar de slots y juegos en vivo todos desde tu domicilio.
бред одним словом
В мире современных развлечений игры, http://bl.com.tw/index.php?title=%D0%9F%D1%80%D0%BE%D1%81%D0%BC%D0%B0%D1%82%D1%80%D0%B8%D0%B2%D0%B0%D1%82%D1%8C%20%D0%B4%D0%BE%D1%80%D0%B0%D0%BC%D1%8B%20%D0%B4%D0%B0%D1%80%D0%BE%D0%BC занимают особое место. Игры предоставляют шансы для отдыха и увлечения. Существует множество жанров, и каждый игрок может найти что-то нравящееся именно ему. От стратегий до экшенов — каждая игра предлагает уникальный опыт.Современные игры отличаются высококачественной графикой, увлекательным игровым процессом и новаторскими технологиями. Игроки могут соединяться с миллионами других пользователей по всему миру, что делает коммуникацию более активным. Поскольку игры становятся частью повседневной жизни, они влияют на на культуру и социальные контексты.Есть также множество конференций, посвященных играм, где разработчики излагают свои новые проекты. Эти события становятся настоящими церемониями для поклонников. Игры продолжают развиваться, привнося в нашу жизнь новые впечатления и вызовы. Каждая новая приключение открывает перед игроками удивительные возможности.
Internet gambling sites have become increasingly popular among enthusiasts. With a range of games, participants enjoy convenience and entertainment from their homes. Casino Online, https://mainlinedogtrainer.com/the-ultimate-guide-to-bitcasino-io-your-gateway-to-2/ offers special bonuses to attract new players.
If you’re looking for exciting thrills, Casino Online, http://cs.hcmus.edu.vn/wordpress/?p=43713 offers a plethora of options. Players can enjoy numerous games, from slots to table games. With convenient access, you can play anytime, anywhere!
Доставка продуктів, http://www.krimket.ro/k.php?url=brovary.webboard.org%2Fpost159.html стала невід’ємною частиною нашого життя. РЈ Р·РІ’СЏР·РєСѓ Р· стрімкого розвитку технологій, люди можуть замовити СЏРєС–СЃРЅС– продукти РЅРµ виходячи Р· РґРѕРјСѓ. Варіанти різноманітні, тож клієнти завжди знайдуть щось РґРѕ смаку. Доставка продуктів перетворила наші звички, надаючи комфорт Сѓ повсякденність.
Playing games at casino online, http://www.memanabuilders.com/2026/02/05/the-future-of-companionship-exploring-dreamgf-ai-200/ offers thrills from the comfort of your home. With a variety of selections available, you can enjoy different styles and win real money! Don’t miss out!
El sector del Casino Online, https://ociotickets.com.ar/blog/yajuego-app-descargar-todo-lo-que-necesitas-saber/ ofrece una gran gama de juegos para distraer a nuestros jugadores. A partir de juegos de azar hasta juegos de mesa, cada oferta es distinta. Por otra parte, puedes disfrutar de bonos especiales los cuales aumentan tu aventura.
Within the world of Online Casino, https://llazybonez.willtec.hk/2026/01/23/experience-the-thrill-of-gaming-at-zixcasino-5/, players can enjoy a host of thrilling games. Featuring cutting-edge technology, these platforms ensure a reliable environment. Hence, engage in your luck today!
Lately, Online Casino, https://test-ja.memindy.com/2026/02/experience-the-thrill-at-big-win-box-casino/ has gained immense popularity among users worldwide. Delivering a wide range of games, it gives players to discover the thrill of playing from the comfort of their homes.
הברכיים חזק יותר. הוא אהב את המראה, הוא קם עם חיוך כזה שהרגשתי לא בנוח! אז ארתור הציע לשתות עוד קוניאק. הוא שפך את כל הארבעה על כוס מלאה והרים את הטוסט שלו. בואו נשתה לדירות הגוף התכווץ והדק. כעבור כמה דקות היא נפלה על צדה ופרשה את רגליה לרווחה, כפופה בברכיה. טיפסתי עליה בלי היסוס, היא הרימה את הזין לתוך הנרתיק. זיינתי לא הרבה זמן, אחרי כמה תנועות https://sex101.co.il/
The 6 x 5, scatter-pays layout preserves what made the original a hit, while the Super Scatter and feature-buy options deliver new dimensions of excitement. High volatility and a robust 96.50% RTP ensure that when Zeus strikes, it truly reverberates. This slot redefines Olympus’s thunderous legacy for anyone chasing colossal, lightning-fast payouts. The main features you’ll consistently trigger in this Gates of Olympus Super Scatter slot online are the Tumbling Reels and Scatter Pays. The Gates of Olympus Super Scatter game keeps the same mechanics as the original hit from Pragmatic Play. It’s a “Pay Anywhere” slot, meaning wins are formed when 8 or more matching symbols land anywhere on the reels, regardless of paylines. Winning symbols disappear thanks to the Tumble feature, allowing new ones to drop in and create chain reactions.
https://solo.to/ethanmiller1
Gates of Olympus Slot looks to be an exciting and volatile gaming experience from Pragmatic Play, who very rarely fail to impress with their aptitude and talent in making memorable games with immense replay value. Rise Of Olympus Slot offers a decent number of features that make triggering some nice payouts very easy. However, it offers low payouts with a max of 100x the stake as its best offer. Nonetheless, it is still a great slot for punters looking for a game with few risks. Luck, fate, even the hand of the gods—those ideas feel right at home in slots, don’t they? You’ll find that across myths, there’s this recurring theme that destiny isn’t really yours to command. It fits neatly with the unpredictable, random swings of a slot machine. Game makers like to frame bonus features as gifts from above (or, sometimes, curses), giving the randomness some narrative dressing.
mold damage repair Santa Rosa CA
накрутка подписчиков в Телеграм https://nakrutka-podpischikov-telegram-1.ru
магазин плитки та сантехніки, http://redirect.subscribe.ru/_/-/frost-rp.forum.st%2Ft822-topic – РЈ нашому магазині плитки та сантехніки РІРё знайдете великий асортимент продукції. Інноваційні дизайни плитки, надійні сантехнічні РІРёСЂРѕР±Рё привносять затишок Сѓ ваш інтер’єр. Приходьте та замовте найкраще для вашого РґРѕРјСѓ!
Gates of Olympus slot es todo un tributo a Zeus, el todopoderoso dios de la mitología griega que, con mano de hierro, gobierna su reino desde su trono celestial. Olympus slot nos lleva a las mismísimas puertas del Olimpo, que se nos abren para acceder a un patio celestial de oro, con enormes columnas sobre las que unas llamas nos anuncian emocionantes aventuras en este slot. Según el domicilio de tu DNI Explora todas las funciones y características del juego Gates of Olympus 1000 demo en la versión demo: ¡Las apuestas pueden ser perjudiciales si no se controlan y pueden generar adicción! Usa nuestras herramientas online y juega con responsabilidad. Jugar Ruleta Online Chile Seleccioná la provincia donde querés hacer tu consulta. Con gráficos únicos y mecánicas de juego emocionantes, este juego captura la atención de jugadores de todo el mundo.
https://domoreservices.com/2026/03/08/lucky-minas-opiniones-vale-la-pena-jugar/
Uno de los juegos de mesa de ruleta por excelencia. ¡Aprende cómo jugar a tu disposición! Cualquier jugador puede acceder a la jugabilidad. Recuerda que, al jugar en las slots, y en otros ámbitos del iGaming. Es muy similar a los scatters son los juegos deben estar autorizados. Por ello, antes de comenzar el juego en tiempo real. Fija un presupuesto antes de jugar a la suiza Microgaming. El objetivo del juego no cambian en función del multiplicador. Los multiplicadores son los símbolos clave de Gates of Olympus y, cada vez que aparezca uno, Zeus (posicionado a la derecha) lanzará un rayo. El multiplicador x500 en Gates of Olympus 1000 me dejó boquiabierto. Sin embargo, las veces que aparece son pocas. ¡Los giros gratis y los scatters logran mantener la emoción! Una vez que tengas lista la apuesta, es momento de hacer girar los carretes. Para ganar en Gates of Olympus Super Scatter, tienes que hacer aparecer 8 o más símbolos iguales en cualquier lugar de los carretes de juego. Algo importante sobre esta máquina tragamonedas es que incluye la función TUMBLE, lo que quiere decir que tras cada victoria, los símbolos ganadores desaparecen y nuevas figuras caen con la finalidad de ayudarte a crear más combinaciones ganadoras.
En la actualidad, los sitios de apuestas se han convertido en una elecciГіn popular. Con diversas opciones de juegos, los usuarios pueden disfrutar de la emociГіn de un Online Casino, https://artusnow.com/juegos-con-alta-rtp-maximiza-tus-ganancias-en-2/ desde la conveniencia de su hogar. AdemГЎs, las recompensas atraen a mГЎs jugadores.
Полностью разделяю Ваше мнение. В этом что-то есть и мне нравится Ваша идея. Предлагаю вынести на общее обсуждение.
I dag er der mange muligheder for at spille online. Et populært valg er casino uden rofus, https://www.kesmep.in/online-casino-uden-dansk-licens-alt-hvad-du-behov/, hvor spillere kan nyde deres favoritspil uden restriktioner. En sådan casinooplevelse fascinerer mange, da den tilbyder en åben adgang til underholdning. Man kan prøve en stor vifte af oplevelser, som kortspil og klassiske titler.
Participating in Casino Online Slots, https://askrealtors.in/2026/01/22/casino-wildwild-your-ultimate-gaming-destination-2/ is a captivating way to experience the realm of online gambling. With numerous themes and styles, players can swiftly find their favorite option to win massive prizes.
Online Casino Slots, http://xs367662.xsrv.jp/wp-acre/2026/02/08/explore-the-exciting-world-of-bets-io-casino-16/ offer enticing experiences for players seeking excitement. With various themes, everyone can find a slot that fits their taste. Promotions enhance gameplay, making it an unforgettable experience.
In the world of wagering, casino sports betting, https://www.oodlesmarketing.com/discover-the-thrills-of-betting-with-betwinner/ has become increasingly popular. Enthusiasts enjoy the thrill of placing bets on their favorite teams or athletes. With innovative technology, online platforms offer convenience and a wide range of betting options. As competition grows, bettors seek the best odds and promotions. Understanding tactics is essential for enhancing one’s experience and potential profits. Explore the exciting world of casino sports betting today!
Ищете натяжные потолки цена — наши специалисты обеспечат качественный монтаж и выгодные цены.
Благодаря новым технологиям натяжные потолки отличаются долговечностью и эстетикой.
Богатый выбор фактур и оттенков даёт возможность реализовать любые дизайнерские задумки.
Выбор надежной монтажной компании в Краснодаре — залог качественного результата и гарантии.
Легкость ухода и отсутствие сложных процедур по обслуживанию — ещё одно преимущество натяжных потолков.
Сравнение портфолио и клиентских отзывов снижает риск недочётов при установке потолка.
https://t.me/s/Pokerdom_Android_APK
Для строительства дорожного основания мы заказали гравийный щебень цена, чтобы обеспечить прочное и ровное покрытие.
Важным при планировании работ являются и экологические последствия добычи щебня.
магазин плитки та сантехніки, https://koknesiplus.lv/par-mums/ РїСЂРѕРїРѕРЅСѓС” СЏРєС–СЃРЅС– РІРёСЂРѕР±Рё для вашого інтер’єру. РЈ нас РІРё знайдете різноманітність плиток та сантехніки, СЏРєС– оздоблять ваш простір. РЈ нас РІРё можете РЅР° вас!
Мне кажется, вы ошибаетесь
В мире видеоигр существует множество жанров, каждый из которых предлагает уникальный опыт. Приключения увлекают игроков высокой динамикой и азартом. Одной из самых популярных игр современности является Fortnite, где борьба за выживание происходит в красочном мире. В этой игре участники сражаются друг с другом, строят укрытия и стараются стать последними выжившими. Составляющие стратегии и динамики делают Fortnite захватывающей и интересной.Помимо Fortnite, многие игры, http://msfo-soft.ru/msfo/forum/messages/forum31/topic29258/message555586/?result=new#message555586 предлагают разные механики. RPG игры погружают нас в мир, наполненный персонажами и эпическими квестами. Категория ролевых игр позволяет игрокам развивать свои навыки и принимать важные решения. Эти игры часто имеют яркий сюжет, который увлекает с первых минут.Мир видеоигр растет и развивается, привнося новые идеи и концепции. Любая игра создает уникальную атмосферу, которая притягивает игроков. Погружение в виртуальные миры становится все более реалистичным благодаря усовершенствованной графике и звуковому оформлению. В конечном счете, видеоигры становятся не просто развлечением, но и настоящим искусством, способным передать эмоции и чувства.
Компания специализируется на профессиональных услугах высокого качества для развития вашего бизнеса. Команда опытных специалистов предлагает комплексный подход к решению задач любой сложности. Ознакомиться с полным спектром услуг можно на https://waltzprof.com/ где представлена детальная информация о направлениях работы. Индивидуальный подход к каждому клиенту и использование современных технологий обеспечивают результат, превосходящий ожидания. Профессионализм и ответственность делают сотрудничество максимально эффективным.
jugar al casino en lГnea, https://tabukinstitute.net/ya-juego-app-colombia-la-revolucion-de-los-juegos-2/ es una experiencia emocionante. Experimentar de una amplia variedad de actividades desde la comodidad de tu hogar hace que te sumerjas en el apasionante mundo del azar. ВЎNo te lo pierdas!
Когда важна простота – без конвертаций, лишних комиссий и путаницы с валютой – логично искать лучшие казино на рубли. Тут решает не “громкая реклама”, а практичные вещи: чтобы пополнение и вывод были удобными, лимиты понятными, а правила не менялись внезапно. В нашем Telegram мы как раз собираем рублёвые варианты в формате “быстро посмотреть и понять”: где комфортнее стартовать, какие платежные методы обычно проходят, на что обратить внимание в условиях бонусов и какие нюансы лучше знать заранее, чтобы не было неприятных сюрпризов.
Casino Online Games, http://www.fitcom.com.tr/onlinecasinoslot40/the-untamed-adventure-of-wildwild-exploring-a-new.html offer thrilling experiences for gamblers seeking fun from the comfort of their homes. With multiple options available, users can try table games and gain real money.
Самый полный каталог саженцев и растений от Мартин-Сад https://www.martin-sad.ru/ это возможность купить по выгодной цене все виды растений и семян. Садовый центр в Москве – Мартин-Сад это крупнейший питомник в России. Также у нас большой каталог товаров для сада и садовая техника. Ознакомьтесь с действующими акциями, чтобы купить еще выгоднее!
The appeal of Online Casino Games, https://ividhya.com/casinoonlineslot5/a-comprehensive-guide-to-the-bets24-casino-3/ is irrefutable. Players value the convenience of betting from home. With diverse options, players can find entertainment they love. The thrill of winning captures participants coming back for more.
Поломка автомобиля в дороге или ДТП требуют быстрого решения — эвакуатора, который доставит машину в сервис или к месту стоянки. Служба ВИП Прокат в Кемерово предлагает услуги эвакуации легковых и грузовых автомобилей круглосуточно с минимальным временем подачи. Современные платформы и опытные водители гарантируют безопасную транспортировку без повреждений. Вызвать эвакуатор можно через https://vipprokat42.ru/evakuatory Прозрачные тарифы, отсутствие скрытых доплат и оперативность делают сотрудничество максимально удобным в стрессовой ситуации.
Если вы крутите Sweet Bonanza 2500 и хотите больше “живой” инфы, а не сухих описаний, залетайте в наш Telegram. Там обсуждаем бонуски, делимся скринами/результатами, отмечаем интересные моменты по игре и просто общаемся по слоту – удобно, когда хочется быстро понять, что сейчас у людей происходит по заносам и как слот себя ведёт на разных ставках.
online casino, http://shop.westernboots.com.ua/?p=213261 offers thrilling action. Players can enjoy various slots. With promotions, every session becomes enticing. Join the fun today!
Find out the exact https://www.the-weather-in-budva.com today. Detailed 7- and 10-day forecasts, including temperature, wind, precipitation, humidity, and pressure. Up-to-date weather information for Budva on the Adriatic coast for tourists and residents.
кольцо с камнями цены кольцо для помолвки купить
utländska casinon utan svensk licens, https://user-83991389-work.colibriwp.com/comprardiplomaonline/minsta-insattning-casino-utan-svensk-licens-allt-2/ har blivit allt mer populära bland spelare. Många söker möjligheten att spela fritt. Dessa casinon erbjuder en varierad spelupplevelse inklusive lockande bonusar och aktionspriser. Spelare kan uppleva flera spel och spelmöjligheter utan de problem som finns på den svenska marknaden.
el mejor casino en lГnea, http://unik-web.com/preguntas-frecuentes-sobre-maggico-casino-todo-lo-2/ proporciona una experiencia inigualable. Teniendo una diversa selecciГіn de entretenimiento, podrГЎs sorprenderte de ofertas atractivos. Por otro lado, el sitio proporciona tranquilidad en cada transacciГіn.
Casino Online, https://mtmsengineering.com/twister-wins-casino-sportsbook-your-ultimate-2/ – Online gambling набирает огромные масштабы. Онлайн-казино предлагают адреналинщикам множество опций для отдыха. Легкость РёРіСЂС‹ РІ любое время Рё РІ любом уголке РјРёСЂР° делает РёС… востребованными для РјРЅРѕРіРёС….
Online Casino, https://flhcut.de/2026/02/07/an-in-depth-look-at-betfoxx-casino-sportsbook/ has become a trendy destination for fans. With engaging games and rewarding bonuses, this platform is a great place to explore new adventures.
affordable mold removal Tucson AZ
In the world of online entertainment, casino online, https://chriseducativo.org/the-future-of-companionship-exploring-dreamgf-ai-2/ has become a favored choice for many. Players can enjoy a variety of games from the comfort of their homes. With captivating graphics and realistic gameplay, it’s no wonder that online casinos are flourishing in today’s market.
вывод из запоя в стационаре в ростове на дону вывод из запоя в стационаре в ростове на дону .
utländska casinon utan svensk licens, http://www.pisarevo.com/casino-utan-svensk-licens-minsta-insattningar-och/ erbjuder spelupplevelser som är unika och spännande. Otroligt många spelare väljer denna sortens alternativ på grund av större bonusar och variation. Detta skapar en fascinerande spelmiljö. Det är viktigt att tänka på att skyddet alltid ska prioriteras.
Los mejores casinos en lГnea brindan una amplia variedad de entretenimiento. En el entorno de Casino Online, https://openleft.ru/?p=1245242, los usuarios pueden top promociones y experiencias. ВЎNo te lo pierdas!
https://casinomad-74.buzz
https://madd-casino.buzz
Очень похоже.
I dag er det vigtigt at finde tid til sjov og underholdning. spil uden om rofus, https://www.northernplainslubes.com/?p=118239 kan være en fantastisk måde at samle vennerne. Overvej at engagere sig i nye spil sammen. Det kan skabe bånd og mange gode minder.
https://casino-mad-74.buzz
Online Casino, https://pqe.hubmedia.ie/2026/01/21/experience-the-thrill-of-triumph-online-casino-uk-7/ – Online Casino предлагает игрокам насладиться шансами, испытывая разнообразные РёРіСЂС‹. Каждый желающий найдет время освоить существенные вознаграждения.
Casino Online, https://www.fly.sale/discover-betgem-your-ultimate-online-betting-2/ дарит множество возможностей для игроков. Здесь можно узнать разнообразные игры, включая классические слоты до актуальных виртуальных развлечений. Сыграйте и насладитесь волнение в Casino Online!
вывод из запоя в ростове-на-дону на дому vyvod-iz-zapoya-v-rostove-3.ru .
https://casino-mad.buzz
https://vodka355.casino/
https://32casino-mad.buzz
Я извиняюсь, но, по-моему, Вы ошибаетесь. Давайте обсудим. Пишите мне в PM.
В мире видеоигр существует множество жанров, но ролевые всегда были на переднем плане. игры, http://1.235.32.108/doku.php?id=%D0%90%D0%BD%D0%B8%D0%BC%D0%B0%D1%86%D0%B8%D0%B8%20%D0%BE%D0%BD%D0%BB%D0%B0%D0%B9%D0%BD%20%D0%B1%D0%B5%D1%81%D0%BF%D0%BB%D0%B0%D1%82%D0%BD%D0%BE, такие как Dark Souls, завоевали популярность благодаря своей сложности и атмосфере. Игроки вступают в захватывающее приключение, где каждый шаг может привести к триумфу или фатальному поражению. Технические возможности современных платформ позволяют создавать потрясающие графические эффекты, что не может не радовать фанатов. Важным аспектом является и аудиоподдержка, которая создает уникальную атмосферу. Она может вызвать у игрока эмоции, усиливая эффект от игрового процесса.Не стоит забывать и о социальных аспектах. Мультиплеерные игры открывают двери взаимодействовать с другими игроками, создавая альянсы. В таких играх требуется командная игра, что добавляет свою изюминку к процессу.Не упустите возможность исследовать миры, полные тайн и загадок. Каждая игра — это новое приключение в неизведанное. С каждым уровнем вы открываете все больше секретов, сталкиваясь с интересными ситуациями. Погружайтесь в мир игр, и помните, что каждое решение имеет значение.
казино монро официальный сайт monro casino бесплатно
nove slovenske casino, https://h2852162.stratoserver.net/index.php/2026/02/25/nove-online-casino-vetko-o-potrebujete-vedie-4/ prinesie zaujГmavГ© prГleЕѕitosti pre fanГєЕЎikov. NГЎvЕЎtevnГci si mГґЕѕu vychutnaЕҐ rozmanitГє ponuku aktivit. NezmeЕЎkajte novГ© prГleЕѕitosti zГЎbavy!
sweet bonanza casino, https://mozillabd.science/wiki/User:Ronny1799836 – En el mundo de los casinos, Sweet Bonanza Casino se destaca por su emocionante experiencia de juego. Presenta grГЎficos vistosos y dinГЎmica fascinante. Los jugadores experimentan grandes premios y bonos, lo que lo convierte en una experiencia elecciГіn favorita.
In the arena of casino sports betting, https://ucdarnetal.fr/the-ultimate-guide-to-betwinner-your-key-to/, followers can experience the thrill of placing wagers on their favorite teams. These offers the chance to combine fascination for sports with the joy of betting. In addition, the variety of betting options enhances the overall experience, allowing gamblers to engage fully with the games they love.
Amid the realm of online gaming, Casino Online Slots, https://content-qa.fortuneconferences.com/explore-triumph-casino-sportsbook-your-ultimate-2/ present an thrilling way to achieve real money. Gamblers can relish several themes and elements that maintain their interest.
Discover the thrill of Casino Online Slots, https://www-l2ti.univ-paris13.fr/~beghdadi/?p=48325, where entertainment awaits at every spin. Gamers can savor a wide array of games, each offering unique features and massive jackpots.
Нужен быстрый и надёжный заказать алкоголь с доставкой, чтобы вечер прошёл идеально.
Клиенты отмечают преимущество возможности подобрать напитки онлайн и принять заказ у порога.
При доставке персонал обязан удостовериться в совершеннолетии получателя и показать необходимые документы.
Логистика сервисов сфокусирована на быстрой доставке и аккуратной транспортировке алкогольной продукции.
Перспективы развития отрасли связаны с внедрением технологий и адаптацией под новые требования покупателей.
Ищете лучшие приключения в сети? Посетите gta сервера и найдите идеальный сервер для захватывающей ролевой игры в GTA 5.
Обучение на практике сокращает количество нарушений и повышает качество игр для всех участников.
Эффективная коммуникация формирует доверие между игроками и способствует развитию сюжета.
Погоня, расследование и спор за территорию собирают зрителей и участников.
Перспективы развития GTA 5 РП связаны с инновациями и поддержкой разработчиков.
https://vodka278.bet/
https://vodka277.casino/
https://vodka279.bet/
jugar al casino en lГnea, https://sunshinekidsplayschool.com/casino-en-vivo-en-novibet-la-experiencia-de-juego/ – Una emociГіn de disfrutar de juegos de casino en internet es fascinante. Estas opciones de juegos son diversas, proporcionando una opciГіn de ganar premios.
nove slovenske casino, http://www.ph-education.com/2026/02/26/online-kasino-slovenske-hranie-a-zabava-na-dosah/ ponГєkajГє hrГЎДЌom zaujГmavГ© moЕѕnosti zГЎbavy a vГЅhier. Ich platformy sГє optimalizovanГ© pre slovenskГЅch hrГЎДЌov. LГЎkavГ© bonusy a rozmanitГЎ ponuka hier uДѕahДЌuje skvelГЅ hernГЅ zГЎЕѕitok.
Online gambling has become a popular trend for many, and Casino Online Games, https://bookento.com/experience-the-thrill-of-top-g-casino-uk/ offer a wide range of options for players. From fruit machines to card games, the thrill of winning is just a click away. Deals enhance the experience, making it even more exciting. Whether you’re a newcomer or a seasoned pro, there’s something for everyone in this lively world of Casino Online Games.
online casino, https://createdgetoys.com/como-realizar-el-registro-en-betwinner-guia-paso-a/ presents a thrilling method to enjoy betting from the comfort of your home. Players can readily access a wide array of games and take advantage of exclusive bonuses.
Casino Online Games, http://beot.cl/index.php/2026/02/explore-beonbet-your-ultimate-online-casino/ offer players a captivating experience. Through numerous games, including slots to table games, every player can find a title that suits their interests.
Услуги по настройке https://sysadmin.guru и администрированию серверов и компьютеров. Установка систем, настройка сетей, обслуживание серверной инфраструктуры, защита данных и техническая поддержка. Помогаем обеспечить стабильную работу IT-систем.
Это мне не совсем подходит. Кто еще, что может подсказать?
joycasino казино, https://t.me/joy_casino_news предлагает широкий выбор игр известных разработчиков. Посетители могут наслаждаться впечатляющими шансами на выигрыш и щедрыми бонусами. В интерфейсе сайта всё качественно для удобства пользователей.
A website with unblocked games for free online play. Popular browser games, arcades, platformers, racing games, and puzzles are available with no downloads or restrictions on any device.
https://vodka276.bet/
https://vodka277.bet/
https://vodka275.casino/
El campo del casino en lГnea, https://noivas.thallytaday.com/todo-lo-que-necesitas-saber-sobre-los-requisitos-2/ ha prosperado de manera notable en los Гєltimos aГ±os. La variedad de juegos proporcionados atrae a jugadores de todos los rincones. AdemГЎs, la comodidad de jugar desde casa facilita que mГЎs fГЎcil.
По моему мнению Вы ошибаетесь. Давайте обсудим. Пишите мне в PM.
online casino uden rofus, https://telc.net.vn/udforskning-af-spil-udenom-rofus-fordele-og/ tilbyder en unikke chancer. Spillere kan nyde diverse spil uden problemer. Stedet giver anledning til at spille uanset.
В современном мире практичность играет важную функцию. продукты с доставкой, https://osusz.to/a-nice-post/265/ дают возможность экономить время и силы. Вы можете купить необходимые товары, не выходя из дома. Фирмы доставки становятся все более удобными. Любой человек оценит такой модель покупки.
Online casinos offer exciting games and possibilities for players to win big. With Casino Online, https://pasyanthi.com/newversion/experience-the-excitement-at-the-high-roller, you can enjoy countless slots, table games, and live dealer experiences from the comfort of your home. Enter the fun today!
In the world of digital casinos, casino online, https://rosybrown-gorilla-155332.hostingersite.com/betwinner-app-your-ultimate-betting-companion-14/ offers a thrilling experience. Players can discover a variety of games from the comfort of their homes. Thanks to cutting-edge technology, these platforms ensure honest dealings and endless fun.
Casino Online, https://filmcutcreative.com/ultimate-guide-to-casino-casino-007-uk-a-luxurious/ предоставляет уникальную возможность наслаждаться азартными играми из комфорта вашего дома. Азартные энтузиасты могут выбрать из обширного ассортимента игр, включая блэкджек. Предложения делают процесс еще более увлекательным. Не упустите шанс испытать удачу в Casino Online!
качество неочень и смотреть нет времени!!!
игры, http://metal-firms.dp.ua/wr_board/tools.php?event=profile&pname=ixomogalew остаются важной частью нашей жизни и культуры. Разнообразные видеоигры предлагают игрокам уникальные миры, в среде они могут исследовать и участвовать в приключениях. Игра может быть расслабляющим времяпрепровождением или серьезным испытанием, в зависимости от направления.Для роскошных геймеров такие проекты, как “The Last of Us”, “God of War” или “Cyberpunk 2077”, стали настоящими жемчужинами индустрии, предлагая выдающийся сюжет и захватывающую графику. Каждый игрок может найти нечто, что будет ему по душе. Мультиплеерные игры, такие как “Fortnite” или “Call of Duty”, способствуют общение между пользователей по всему миру. Они становятся не только местом для досуга, но и возможностью построить новые знакомства. К тому же, постоянно меняется, и игры идут вперед в ногу с этим прогрессом. С каждым днем разработка новых концепций становится все более популярной, и не за горами те времена, когда игровые технологии удивят нас новыми решениями.
casino en lГnea, https://lightartd24.andrewringler.com/2026/01/29/opiniones-de-usuarios-sobre-la-aplicacion-yajuego-4/ – El casino digital ha cambiado la manera en que nos entretenemos. Ahora, jugadores pueden acceder a mГєltiples juegos desde la conveniencia de su hogar. AdemГЎs, ofrecen bonos atractivas que incrementan la experiencia de entretenimiento.
99 caiu caiu.site .
продукты с доставкой, https://adsujsr.adsu.edu.ng/article1/1-assessment-of-heavy-metal-pollution-on-roadside-dusts-from-selected-locations-in-ilorin-nigeria-using-aas-techniques/ привносят удобство в повседневную жизнь. В наше время все больше людей выбирают заказ еды через интернет. Это облегчает время и усилия. Дополнительно, ассортимент доступных товаров впечатляет, что позволяет испытывать любые вкусовые предпочтения.
Online Casino, http://farmacia.loneus.biz/index.php/2026/01/20/experience-the-thrill-of-spinsala-casino-your-4/ features an entertaining experience for bettors. With a variety of games, clients can indulge in card games from the comfort of their house.
поликарбонат навес заказать навес для крыльца заказать
The universe of Online Casino, https://thompsonandthompsonltd.com/2026/02/06/unveiling-the-charm-of-casino-aphrodite/ offers exciting opportunities for players. Through diverse games, players can explore the fun of victory from their own their homes.
Супер просто супер
jeet city casino, click here – Рто казино Jeet City неповторимый РјРёСЂ азартных РёРіСЂ. РќР° этом ресурсе посетители РјРѕРіСѓС‚ погрузиться РІ широким выбором ставками. Обстановка азарта оживает СЃ каждым роллом.
Where to propose to a girl top-rated proposal venues near Barcelona
casino sports betting, http://www.newjapan.co.jp/todo-lo-que-necesitas-saber-sobre-betwinner-5-30925 is an exciting manner to engage in the world of athletics. It presents bettors the chance to combine their love for sports with adrenaline-pumping bets. With numerous options available, players can find their preferred gambling method.
TIM down TIM down .
El mecanismo de registro de casino en lГnea, https://formationaxis.ca/usando-cash-out-en-tonybet-chile-guia-completa-3/ ofrece a los jugadores acceder a una variedad de juegos. Con el fin de arrancar a jugar, es indispensable completar un formulario con detalles personales.
Gambling on Casino Online Slots, https://espacolabella.com/online-casino-spins-house-your-ultimate-gateway-to/ is a favored activity for many gamblers. These games deliver an thrilling experience with multiple themes and features. Winning big prizes keeps players engaging again.
Экзотические фрукты, https://apis.at.ua/forum/26-1126-1%FD%95%D9%95%B9%D0%F5%C1%C9%BD%99%A5%B1%94%99%C1%B9%85%B5%94%F5%15%B1%B1%85%11%95%D9%A5%E8 порадуют ваш рацион. Рамбутан обладает необычным вкусом и наполнен витаминами. Попробуйте эти ароматные удовольствия!
анонимное лечение алкоголизма без учета алматы
Подбор курса основан на оценке состояния, анамнезе и мотивации пациента.
Варианты лечения включают медикаментозную поддержку и психотерапию. Поддержка близких и групповые встречи укрепляют устойчивость к рецидивам.
Реабилитация в Алматы предлагает стационарные и амбулаторные программы с разной продолжительностью. Продолжительная реабилитация включает обучение, трудовую терапию и восстановление социальных связей.
Многие центры предлагают сопровождение после выписки. Постреабилитационное сопровождение включает регулярные встречи и индивидуальные сессии с психологом.
Критерии выбора клиники в Алматы включают лицензии, квалификацию персонала и отзывы пациентов. Анализ отзывов и результатов лечения дает представление о репутации центра.
План лечения должен быть индивидуальным и гибким. Семейная поддержка учитывается при разработке и реализации программы лечения.
Профилактика рецидивов является ключевой частью реабилитации от алкоголизма. Участие в сообществах трезвости создает сеть поддержки и обмена опытом.
Заключение подчеркивает, что лечение алкоголизма в Алматы доступно и разнообразно. Сочетание медицинской помощи, психотерапии и социальной поддержки делает лечение эффективным.
врач нарколог алматы — профессиональная помощь и комплексные программы для лечения наркомании в Алматы.
Клиники города предлагают программы детоксикации в сочетании с психотерапевтическими методами и реабилитацией.
полип эндометрия в матке операция
Santander down caiu.site .
Within the world of digital gaming, Online Casino Slots, https://thesofacityfurniture.com/2026/02/06/discover-the-thrill-of-online-amigo-wins-2/ shine. With captivating graphics and dynamic features, players experience unmatched entertainment. All slot offers special themes and rewarding bonuses, making it easy to enjoy and potentially win big!
По моему мнению Вы ошибаетесь. Могу это доказать.
casino uden om rofus, https://www.henrikafabian.de/oplev-casino-udenom-rufus-en-guide-til-spillere/ tilbyder en verden af underholdning, hvor spillere kan nyde forskellige spil uden besvær. Mennesker kan uafhængigt vælge deres foretrukne spil og deltage i den spændende atmosfære, som kasinoer tilbyder. Det er en chance for at slappe af og måske vinde nogle gevinster.
jugar al casino en lГnea, https://tokyo.kozai-reuse.org/blog/42063.html es una experiencia emocionante y conveniente. Los distintos juegos disponibles brindan la oportunidad de disfrutar desde casa. AdemГЎs, las promociones permiten que los jugadores consigan ganar mГЎs capital para seguir jugando.
online casino, https://www.drevenack-soll-schoener-werden.de/2026/02/04/discover-the-betwinner-apk-your-ultimate-betting-2/ delivers an exciting experience for players. By using various games like slots, poker, and blackjack, fans can savor their favorite pastimes from home. Don’t miss out on enticing bonuses and promotions!
Casino Online Games, https://www.studioraffaellapazzaglia.it/onlinecasinoslot37/discover-spinsala-casino-sportsbook-your-ultimate-27/ present a variety of exciting selections for enthusiasts to try out. Such as roulette to interactive games, there’s something for everyone. Dive into the world of Casino Online Games and discover your favorite!
досуг современных мужчин, https://www.stanfordpropertyinvestor.co.uk/contact/ — это важная часть жизни. Спорт позволяет расслабиться и поддерживать форму. Многие выбирают экскурсии на выходные, чтобы ножить горизонты. Хобби также играет основную роль в жизни, обогащая ее новыми увлечениями.
увеличение члена стоимость
http://vodka275.bet/
http://vodka274.casino/
http://vodka274.bet/
такое часто бывает.
В мире азартных игр 7k casino, https://7k-casino-vi6br.cfd/ представляет уникальный опыт для геймеров. Лотереи и развлекательные игры ждут своих поклонников. Скидки обогащают вкуса, а незабываемые призы восхищают новых участников. Обратитесь в 7k casino, чтобы узнать больше о перспективах!
по крайней мере мне понравилось.
игры, http://msfo-soft.ru/msfo/forum/messages/forum32/topic29400/message555740/?result=new#message555740 – Игра – это удивительное пространство, где приобретаете шанс погружаться в неизведанные миры. Современные авторы игр предлагают очень много жанров. В одиночных событиях вы сможете исследовать сюжет и загадки, в то время как многопользовательские режимы создают уникальную атмосферу соревнования. Многообразие игровых механик и графики восхищает. Выбирайте свою развлекательную дорожку и погружайтесь в увлекательные приключения!
Online Casino Games, http://joesflightschool.com/2026/02/discover-the-exciting-world-of-amazon-slots-casino-6/ – Online Casino Games offer excitement and diversity for players. From fruit machines to poker, there’s something for everyone. Experience the rush of winning big!
Вы не правы. Я уверен. Давайте обсудим это.
Playing at web-based casinos offers fun and flexibility. With casiny online casino, visit site, users can enjoy a variety of games right from wherever they are.
Los casinos en lГnea ofrecen diversiГіn sin salir de casa. Tienes la oportunidad de jugar desde tu ordenador o mГіvil. AdemГЎs, disponibles incentivos atractivos que mejoran la experiencia. ВЎDisfruta de la suerte en el casino en lГnea, https://merkor.net/2026/01/30/bonos-de-giros-gratis-todo-lo-que-necesitas-saber-2/!
Playing matches at Casino Online, https://www.b8-sport.net/archives/139669 is an entertaining experience. You can appreciate a vast range of choices from the comfort of your home. Promotions make it even more alluring.
http://vodka271.casino/
стоимость увеличения члена
jaya9 casino, https://orig3n.es/unlock-big-wins-with-slot-games-featuring-sticky/ offers an exhilarating adventure for enthusiasts around the globe. With a plethora of selections, it stands out as a top-notch destination. Join now to explore fantastic promotions and exciting gameplay!
замена масла в дизельном генераторе, https://fmr.dk/producent/lemken/sirius10_1300-seh_deutz_126__resized_1600x1200-1030×687-1/ — важный процесс, который поддерживает долговечность устройства. Периодическая замена масла улучшает оптимальной работе генератора. Требование в этом деле не стоит игнорировать. Важно проверять уровень масла и в нужный момент производить замену.
дистанционное обучение 1 класс дистанционное обучение 1 класс .
https://vodka272.bet/
Извините, что я Вас прерываю, но не могли бы Вы расписать немного подробнее.
Добро пожаловать в царство азартных игр! Чтобы начать зарабатывать, вам нужно сделать 7k casino вход, 7к казино. На этом сайте вы найдете множество игр и бонусов. Не упустите шанс насладиться увлекательным игровым процессом!
Online Casino, http://www.scarlett-rose.net/?p=36839 – Online Casino предоставляет возможность наслаждаться азартными играми, РЅРµ выходя РёР· РґРѕРјР°. Посетители РјРѕРіСѓС‚ определять СЃРІРѕРё любимые развлечения Рё получать удовольствие РІ любое время. Акции делают процесс еще более интересной.
http://vodka271.casino/
https://vodka272.bet/
http://vodka271.casino/
https://vodka272.bet/
полип в матке операция
Preparati a vivere l’esperienza Crazy Time al massimo, tra slot, bonus e statistiche live dal cuore dell’Italia.
Crazy Time rappresenta uno degli slot piu ambiti nei casino online italiani, con tornate bonus che mantengono alta l’attenzione dei giocatori.
result crazy time https://lenoralivingston.com/
El mundo del casino en lГnea, https://dronchessacademy.com/index.php/2026/01/29/guia-completa-sobre-la-verificacion-de-cuenta-en-5/ es dentro de auge, proporcionando emocionantes aventuras a los. A travГ©s de una variedad de juegos y atractivas bonificaciones, los aficionados se sitГєan disfrutando con la emociГіn desde la comodidad de su hogar. Dicha moda se prevГ© persistir durante los aГ±os por venir aГ±os.
рецидив варикоцеле
фимоз лечение цена
Online Casino, https://showmeimprints.com/onlinecasinoslot35/discover-the-excitement-of-online-slots-at-angels-8/ предлагает разнообразные развлечений для любителей. В таких заведениях нужно найти стратегии увеличения прибылей.
онлайн школа 11 класс онлайн школа 11 класс .
Я извиняюсь, но, по-моему, Вы допускаете ошибку. Могу это доказать.
Lemon Casino Polska, kasyno z licencja to miejsce, gdzie miłośnicy mogą przeglądać różnorodne opcje. Serwis oferuje atrakcje, które przyciągają nowicjuszy oraz doświadczonych graczy.
замена масла в дизельном генераторе, https://alpinistiniaidarbai.lt/periodichnost-zameny-masla-v-dizelnyh-dvigateljah-2/ — это важный процесс, который поддерживает его эффективную работу. Постоянная замена масла позволяет защиту двигателя. Старое масло может привести поломкой. Следует соблюдать график замены для эффективной работы генератора.
Полезная фраза
Вход в 7k casino предоставляет особую возможность пробовать азартные шансы. Здесь вы найдете уникальные игровые программы и выгодные предложения, которые сделают вашу игру захватывающей. Не упустите шанс на удачу — войдите в 7k casino вход, https://7k-casino-0gd12.top/ и начните свой путь к азарту!
Welcome to your ultimate experience at joya 9 casino, https://www.ainecleaning.ca/comprehensive-review-of-pragmatic-play-slots-2/, where fun meets indulgence. Experience a suite of games and enjoy exclusive rewards! Join thrilling tournaments and socialize with fellow participants in a dynamic atmosphere. Never miss out on the fun at Joya 9 Casino!
жировики удаление
атерома удаление стоимость
О¤О± ОґО№О±ОґО№ОєП„П…О±ОєО¬ ОєО±О¶ОЇОЅОї ОµОѕП‰П„ОµПЃО№ОєОїПЌ ПЂО±ПЃОП‡ОїП…ОЅ ОјОїОЅО±ОґО№ОєОП‚ ОґП…ОЅО±П„ПЊП„О·П„ОµП‚ ПѓП„ОїП…П‚ П‡ПЃО®ПѓП„ОµП‚. ОњОµ ПЂОїО№ОєО№О»ОЇО± ПЂО±О№П‡ОЅО№ОґО№ПЋОЅ ОєО±О№ П†О±ОЅП„О±ПѓП„О№ОєО¬ ОјПЂПЊОЅОїП…П‚, П„Ої online casino ОµОѕП‰П„ОµПЃО№ОєОїП…, https://650.wieruszow.pl/03/02/online-gaming/ ОП‡ОµО№ ОіОЇОЅОµО№ ОґО·ОјОїП†О№О»ОП‚ ОіО№О± ПЊПѓОїП…П‚ ОµПЂО№ОёП…ОјОїПЌОЅ ОµОЅОёОїП…ПѓО№О±ПѓОјПЊ.
сейфы
По моему мнению Вы не правы. Я уверен. Могу отстоять свою позицию. Пишите мне в PM, обсудим.
casino uden rofus, https://cvisual.pe/index.php/2026/02/17/udenlandske-online-casinoer-din-guide-til/ kan findes mange chancer for spillere. Det letter spil uden bГёvle. Spilleren har mulighed for at spille forskellige muligheder.
Я присоединяюсь ко всему выше сказанному. Можем пообщаться на эту тему. Здесь или в PM.
Throughout the world of online gambling, participants often seek choices that deliver an unique experience. The casino ohne oasis, https://www.jaritafreydank.com/ is remarkable for its diverse games and appealing bonuses. Regardless of the event, players find the experience easy to navigate. With superb customer service, the casino ohne oasis ensures high levels of satisfaction.
обучение стриминг обучение стриминг .
пластика перегородки носа
El proceso de registro en un casino en lГnea es esencial para acceder a los juegos y aprovechar las bonificaciones. Cumplir el formulario de registro de casino en lГnea, https://mytaxadvisor.co.in/como-funcionan-las-cuotas-en-las-apuestas-2/ es sencillo, pero es vital garantizar tu informaciГіn personal y determinar un sitio de credibilidad.
Casino Online Slots, https://trendyfinds.zubeerhub.com/explore-the-exciting-world-of-online-casino-silver/ – Web-based gambling has gained immense popularity recently. Among the myriad of options, web slots stand out for their engaging features. Players can enjoy various settings and massive winnings. Whether you’re a novice or a seasoned betting fan, Casino Online Slots offer something for everyone. Don’t miss the chance to try your luck today!
Какой полезный топик
В увлекательном мире игры, http://geolan-ksl.ru/forum/user/107933/ каждый могут испытывать захватывающие моменты. Графика поражает думы, а задания мотивируют углубляться в сюжет. Коммуникация с другими игроками делает процесс ещё более увлекательным.
стоимость септопластики
Я извиняюсь, но, по-моему, Вы не правы. Пишите мне в PM, пообщаемся.
С целью осуществить игровой процесс, вам необходимо пройти процедуру регистрации. Затем — 7k casino вход, https://7k-casino-nnkle.cfd/. Важно помнить, что для игры все нужно правильно настроено. Желаем удачи!
Когда решаете где купить мебель, http://swinarski.org/page1.php?messagepage=82547, стоит изучить на большие магазины. Стиль мебели всегда должны соответствовать вашим вкусовым требованиям. Не забывайте о бюджете, чтобы выбор не оказался слишком высоким.
тонзиллэктомия москва цена
jaya 9 casino, https://makeupglitz.com/cricket-betting-a-comprehensive-long-term-strategy/ – Jaya 9 casino предлагает уникальные возможности для зрителей. Здесь площадке можно испытать множество РёРіСЂС‹ Рё выигрыши. Любой посетитель найдет нечто РїРѕ своему усмотрению.
сейф на оружие
echtgeld online roulette, https://www.syncm.net/?p=481688 ist eine interessante Möglichkeit, sein Glück zu versuchen. Spieler können von zu Hause aus spielen und die besten Chancen genießen. Durch zahlreiche Varianten ist für jeglichen Stil etwas dabei.
jugar al casino en lГnea, https://shop.humanmusicplatform.com/demo-vs-modo-real-cual-elegir-para-tus-apuestas/ es una experiencia emocionante la que te permite disfrutar de un variedad de juegos desde la comodidad de tu hogar. Tienes la opciГіn de probar suerte en ruleta, las tragamonedas o el blackjack, proporcionando la oportunidad de ganar grandes premios. AdemГЎs hay bonos y promociones que son hacen la experiencia aГєn mГЎs atractiva.
Online gambling offers exciting Casino Online Games, https://slwebstaging.wpengine.com/explore-the-exciting-world-of-slapkong-casino-7/ that provide endless entertainment. Players can discover various options like slots, blackjack, and poker. With advanced technology, each game delivers an immersive atmosphere.
В Москве существует множество автосервисов, специализирующихся на Тойота. В этом автосервисе вы найдете опытных техников, которые знают все о Тойота.
Если вам нужен качественный и надежный автосервис Тойота, мы предлагаем широкий спектр услуг для вашего автомобиля.
Для Тойота необходим высокий уровень квалификации. Мастера сервиса постоянно повышают свою квалификацию для качественного обслуживания.
Техническое оснащение сервиса соответствует самым высоким стандартам. Это позволяет проводить диагностику и ремонт на высшем уровне.
Обращаясь в автосервис Тойота, вы можете рассчитывать на высокое качество услуг. Ваше доверие для нас — наивысшая награда.
Автор статьи предоставляет сбалансированную информацию, основанную на проверенных источниках.
Ищете, где макетная плата купить? Посетите беспаечная макетная плата для выгодных предложений.
Дешевые платы могут иметь плохие соединения и быструю коррозию.
Кроме того, существуют комбинированные варианты с областями для пайки.
Качество контактных гнезд и прижимов определяет надежность соединений.
Маркетплейсы часто имеют выгодные предложения и быструю доставку.
Лучшие материалы обеспечивают надежное соединение и длительный срок службы.
огнеупорные сейфы
3d забор производство установлен быстро и аккуратно, обеспечивая надежную защиту участка и эстетичный вид.
Технологии производства и используемые материалы справляются с воздействием погодных условий.
Также эти ограждения неприхотливы в обслуживании и редко требуют реставрации.
Варианты дизайна 3D заборов разнообразны по форме и цветовой гамме.
В то же время такие заборы не теряют своих защитных свойств и прочности.
Стоимость 3D заборов и простота их установки делают их экономичным выбором.
Срок службы таких заборов при правильной установке может достигать нескольких десятилетий.
Эта особенность делает 3D заборы востребованными для охраны и контроля периметра.
Дополнительное оформление подсветкой и лианами придаст очарование и функциональность.
сколько стоит операция варикоцеле в москве
Если вы решили освежить интерьер, вам следует рассмотреть купить мебель, http://www.greenscreenstudio.eu/kupit-mebel-v-stile-barokko-roskosh-i-jelegantnost. Классический дизайн может в корне изменить атмосферу вашего дома. Не забывайте выбирать качество и дизайн.
In fact no matter if someone doesn’t understand afterward its up to other users that they will assist, so here it takes place.
сейф для оружия в москве
дистанционное школьное обучение shkola-onlajn-33.ru .
Accessing the platform is simple with jaya 9 login, https://unfiltered-adventures.com/2026/01/20/cricket-betting-for-casual-players-a-beginner-s/. This procedure allows clients to enter securely. Follow these prompts to ensure a hassle-free experience.
Los espectГЎculos de casino en lГnea, https://just-trans.com.pl/la-importancia-de-la-verificacion-de-identidad-en-7/ presentan una sensaciГіn intensa. Los participantes pueden disfrutar diversas alternativas. Desde slots hasta ruleta, hay algo para cada gusto. ВЎConГ©ctate a la diversiГіn hoy!
online roulette casinoer, https://luckydistributions.com/2026/03/02/online-roulette-i-danmark-alt-hvad-du-behver-at-23/ tilbyder spændende muligheder for gamblere. Brugere kan opdage det fantastisk spil med varierede strategier. Mange platforme sikrer fornøjelse døgnet rundt.
Virtual gaming offers fantastic adventures. At Casino Online, https://communityresourcesconnection.com/explore-the-exciting-world-of-savanna-wins-casino-45/, players can enjoy many choices and compete for big wins from the comfort of home.
Where to propose to a girl marriage proposal in Barcelona
сейфы для отелей
сейф металлический офисный
школа онлайн для детей shkola-onlajn-33.ru .
встроенный сейф купить
Юрист в Алматы, https://cheap-emergency-locksmith.com/avoid-scams-and-find-a-skilled-professional-locksmith-with-these-top-tips/ – это профессионал, который предоставляет правовую поддержку гражданам и организациям. Его обязанности – защищать интересы клиентов в судах и других инстанциях. Выбор опытного юриста поможет успешное решение правовых затруднений. Каждый обратится за поддержкой в ситуации, требующей глубокой юридической экспертизы.
To access the platform, users must first complete the jaya9 login, http://www.contabiljl.com.br/mastering-daily-missions-on-joya9-the-ultimate/ process. This can be done by entering the required credentials. Once logged in, individuals can explore various features available by the site, enhancing their overall experience. Each session offers security and privacy for all users.
заказать кухню в интернете заказать кухню в интернете .
Mafia casino online EspaГ±a, https://samikshaharmony.com/mafia-casino-online-espana-la-nueva-experiencia-de-3/ ofrece una experiencia destacada para los amantes de los juegos de azar. Dicho sitio tiene con una amplia gama de juegos, tales como tragaperras hasta opciones de mesa. Los pueden disfrutar de incentivos atractivos que mejoran la diversiГіn. Con el enfoque en la seguridad, Mafia casino online EspaГ±a se verifica que cada transacciГіn sea segura y ГЎgil. ВЎГљnete a esta aventura y vive la emociГіn del casino desde casa!
https://madcasino-01.xyz
Online kasino nabГzГ skvД›lГ© zГЎЕѕitky pro nГЎvЕЎtД›vnГky hazardnГch her. casino online zahraniДЌГ, http://paok.kr/pod-orechem/bezpene-zahranini-casino-jak-vybrat-to-prave-pro-4/ nabГzГ ЕЎirokГЅ vГЅbД›r her a pЕ™itaЕѕlivГ© bonusy. ZГЎbava online je pohodlnГ©, coЕѕ pЕ™itahuje novГ© hrГЎДЌЕЇ.
Online Casino, https://hoo2kah.com/savanna-wins-online-casino-uk-a-jungle-of-gaming-3/ позволяет игрокам попробовать удачу в разнообразных играх. На этих платформах можно участвовать в игровых автоматах.
взломостойкий сейф
офисные сейфы
сейф купить в москве
Агентство недвижимости помогает быстро и безопасно решить вопросы покупки и продажи жилья в Москве. Специалисты сопровождают сделку на всех этапах, от подбора вариантов до подписания договора. Такой подход снижает риски и экономит время клиентов: jois жк
http://vodka270.casino/
заказать кухню онлайн заказать кухню онлайн .
зеленая карта в турцию, http://kapruziak.eu/gbook.php — это важный шаг для получения медицинской страховки. Она предоставляет доступ к качественным медицинским услугам и защищает от непредвиденных расходов. Обладатели такой карты могут чувствовать себя уверенно, зная, что их здоровье под защитой. Этот документ существенно облегчает процесс обращения за медицинской помощью. Необходимость иметь зеленую карту в Турцию увеличивается, особенно для путешественников и экспатов.
https://madcasino-01.xyz
http://vodka269.casino/
joya 9 online casino, https://ahdustechnology.fi/bti-sport-review-an-in-depth-analysis-on-joya9/ offers a remarkable gaming experience with a wide array of games. Players can enjoy thrilling slots and involving table games. Join right away and discover the fun of Joya 9 online casino!
http://vodka269.casino/
https://madcasino-01.xyz
В Краснодаре наш интернет магазин ковров предоставляет разнообразие товаров для оформления вашего дома.
Мир ковров онлайн
Постоянный анализ рынка помогает нам удерживать цены невысокими, не снижая качество.
Mafia casino online EspaГ±a, https://hwnerds.com/mafia-casino-online-espana-tu-destino-de-juego-7/ es un lugar ideal para los amantes del juego. Da una experiencia emocionante donde los usuarios pueden gozar de increГbles premios y un clima envolvente que los cautivarГЎ. AdemГЎs, la gama de juegos es excepcional.
купить сейф взломостойкий в москве
Discover the thrill of real-money live casino action at online table games, where you can enjoy live dealers, top software providers, and exclusive promotions.
The platform maintains transparent policies so users are aware of rules and standards.
Participating in Casino Online Slots, https://zonacarellc.com/explore-the-excitement-of-online-casino/ is a captivating way to enjoy the realm of online gambling. By utilizing many themes and jackpots, players can exploit their most enjoyable games and try their luck from the comfort of their abodes.
zahraniДЌnГ casino, [url=https://gingerrootsmedia.com/online-casino-bonus-bez-vkladu-jak-ho-vyuit-a-co/]https://gingerrootsmedia.com/online-casino-bonus-bez-vkladu-jak-ho-vyuit-a-co/[/url] nabГzГ mnoho zajГmavГЅch moЕѕnostГ pro hrГЎДЌe, kteЕ™Г hledajГ zГЎbavu a vzruЕЎenГ. ModernГ technologie zajiЕЎЕҐuje spolehlivost a ЕЎirokГЅ vГЅbД›r her. NemyslГme si mohou uЕѕГt pЕ™itaЕѕlivГ© bonusy a pЕ™Гjemnou zГЎkaznickou podporu. ZahraniДЌnГ casino se stГЎvГЎ stГЎle vГce populГЎrnГ volbou pro online hranГ.
купить встраиваемый сейф для дома
заказать кухню под заказ заказать кухню под заказ .
joycasino играть онлайн t.me/joy_casino_news .
Welcome to the fascinating world of jaya9 casino, https://platform.socialhackademy.eu/understanding-live-casino-bet-confirmation-timing/, where excitement meets luck. Enjoy a variety of games, from slots to games of chance. Join the fun and discover the greatest online gaming platform!
Forex Broker, [url=https://dienlucvietnam.vn/resolusi-pertikaian-cara-efektif-menyelesaikan/]https://dienlucvietnam.vn/resolusi-pertikaian-cara-efektif-menyelesaikan/[/url] merupakan penyedia servis yang mengizinkan pedagang untuk melakukan transaksi di ujikaji mata wang. Dengan memilih Forex Broker yang sesuai, anda dapat memaksimalkan potensi pendapatan.
La Mafia casino online EspaГ±a, https://ebeam-agro.com/mafiacasino-online/mafia-casino-online-espana-experiencia-de-juego/ brinda una vivencia de juego Гєnica. Con sus Гєnicas promociones, los participantes pueden disfrutar de sorprendentes premios. ВЎГљnete a la diversiГіn!
Amid the realm of Casino Online Games, https://zamzamtours01.com/experience-the-thrill-of-casino-richy-leo-uk-3/, enthusiasts may delight in a wide selection of thrilling games, such as slots to poker. Such platforms provide a unique chance for earn actual rewards.
zahranicni online casina, http://real-timedeals.com/no-deposit-casino-bonus-ve-co-potebujete-vdt-5/ umoЕѕЕ€ujГ ЕЎirokou ЕЎkГЎlu her a zГЎbav. ZГЎkaznГkЕЇm se otevГrГЎ svД›t nГЎruЕѕivГ© zГЎbavy. UЕѕijte bonusy a uЕѕГvejte vzruЕЎenГ z kaЕѕdГ© sГЎzky.
joya 9 casino, http://lookoutontheknoll.com/understanding-the-account-verification-process-2/ offers an exhilarating gaming experience for visitors searching for fun. With a variety of entertainment options, it guarantees limitless opportunities. Join Joya 9 casino to explore the hottest gaming trends and achieve great rewards. Whether you’re an amateur or someone skilled, Joya 9 casino welcomes you with open arms.
Las apuestas en Uruguay han crecido exponencialmente en los Гєltimos aГ±os. Cada vez mГЎs uruguayos se sienten atraГdos por el entretenimiento que ofrecen. Las webs digitales han facilitado este acceso, permitiendo que cualquiera pueda participar. Sin duda, las apuestas en Uruguay, https://ivo.com.uy/?p=12442607 son una tendencia que se expande con fuerza.
Cashwin casino EspaГ±a, https://www.grimalc.com/cashwin-casino-espana-tu-destino-de-30/ presenta una diversa gama de diversiones para todos. Con tragamonedas, los table games tambiГ©n estГЎn presentes. La plataforma se caracteriza por ser confiable y sencilla, brindando vivencias inolvidable.
Online casinos offer the possibility to enjoy betting from the comfort of your home. With Casino Online, http://www.fyosy.com/?p=295796, gamblers can explore multiple games like slots, poker, and blackjack. Incentives enhance the gaming experience!
nejlepЕЎГ zahraniДЌnГ casino, https://www.skytravelscr.com/2026/02/24/online-casino-pro-eske-hrae-jak-vybrat-to-nejlepi-2/ nabГzГ ЕЎirokou ЕЎkГЎlu her a vzruЕЎujГcГ zГЎЕѕitky. Zde mЕЇЕѕete vysledovat nejnovД›jЕЎГ automaty a karetnГ hry. PЕ™ГЎtelskГ© prostЕ™edГ zГЎkaznГkЕЇm nabГzГ nejvyЕЎЕЎГ zГЎЕѕitek ze hry.
jaya 9 casino, https://castle2020.wpengine.com/understanding-leaderboard-rewards-on-jaya9-your/ – In Jaya 9 casino РІС‹ найдете всевозможные РёРіСЂС‹. Рто идеальное место для тех, кто ищет вдохновение РІ РёРіСЂРѕРІРѕРј РјРёСЂРµ.
https://madcasino-01.buzz
https://mad-casino2.xyz
Cashwin casino EspaГ±a, https://www.sgcbhk.com/cashwin-casino-espana-todas-las-novedades-y/ ofrece una plataforma de juegos sorprendente. Prueba una amplia selecciones de juegos en vivo. Гљnete y aprovecha bonos exclusivos para maximizar tu diversiГіn.
Registro Supermatch, [url=https://www.cepes.org.br/cepes/apuestas-deportivas-todo-lo-que-necesitas-saber-45/]https://www.cepes.org.br/cepes/apuestas-deportivas-todo-lo-que-necesitas-saber-45/[/url] es una plataforma Гєtil en aquellos que buscan invertir en eventos deportivos. Ofrece estadГsticas detalladas y anГЎlisis que ayudan tomar decisiones informadas. Las personas pueden acceder fГЎcilmente a toda la informaciГіn necesaria para maximizar sus apuestas. AdemГЎs, el diseГ±o es amigable y asegura una experiencia satisfactoria.
Online Casino, http://vriendschapsboot.nl/?p=223011 presents a selection of lively games for gamblers. With advanced technology, each session is captivating. Join the fun and take a chance!
zahranicne online casino, https://boringmagazine.org.uk/online-kasina-pro-eskeho-hrae-zabava-a-vyhry-na/ nabГzГ ЕЎirokou ЕЎkГЎlu her, vДЌetnД› automaty, ruletu a poker. Vychutnejte si vzruЕЎenГ a moЕѕnost vyhrГЎt skvД›lГ© ocenД›nГ z pohodlГ vaЕЎeho domova. Hrajte svД›ta zГЎbavy a adrenalinu.
https://madcasino-01.buzz
https://mad-casino2.xyz
https://mad-casino2.xyz
https://madcasino-01.buzz
https://casino-mad-2.buzz
Santander down caiu.site .
To enjoy sports betting, you need to install the 1xbet application. This platform offers an user-friendly experience for players. With the 1xbet download, http://marisamilstead.slccwebdev.com/wp/2026/02/03/unlocking-the-1xbet-thailand-bonus-a-comprehensive-5/, you’ll access various markets and features right at your fingertips. Don’t miss out on the engaging world of online betting!
Los casinos fuera de EspaГ±a dan una diversa gama de juegos. Los jugadores pueden experimentar ofertas atractivos y tГtulos innovadoras. En estos entornos, la diversiГіn es emocionante. Descubrir las opciones de Casinos Fuera de EspaГ±a, http://new.iskcondesiretree.com/casinos-fuera-de-espana-una-experiencia-de-juego/ puede ser una elecciГіn acertada para los apasionados del juego.
predicciones futbol, https://marijoribas-shop.es/pronosticos-futbol-estrategias-y-consejos-para/ – Las predicciones futbol siempre generan expectativa. Cada partido es analizado por expertos, que ofrecen su visiГіn sobre el desempeГ±o futuro. Las tendencias actuales influyen en estas proyecciones que pueden asombrar a los fans.
zahraniДЌnГ casina, http://saikohayama.com/nova-casino-online-ve-co-potebujete-vdt-o-online-7/ skГЅtajГ ЕЎirokou paletu her v starГЅch aЕѕ po modernГ verze. PatЕ™Г mezi pЕ™itaЕѕlivГ© moЕѕnosti pro hrГЎДЌe, kteЕ™Г touЕѕГ rozЕЎГЕ™it svГ© sГЎzkovГ© zkuЕЎenosti.
Santander caiu Santander caiu .
1xbet online casino, https://sagenv.com/discover-the-thrill-of-betting-with-1xbet-in/ предлагает множество увлекательных развлечений. Любой игрок имеет возможность найти нечто по своему вкусу. Привлекательный интерфейс формирует перепасовку легким.
Los establecimientos de azar sin licencia proporcionan mГєltiples oportunidades de entretenimiento a pesar de su deficiencia de regulaciГіn. Asistir en estos sitios puede ser en un riesgo financiero. Por eso, es vital informarse bien. Los casinos sin licencia, https://descomplicandovideos.com.br/casinos-sin-licencia-seguros-en-2026-lo-que-debes/ no garantizan protecciГіn al jugador.
Las casas de Apuestas, https://miloch.com.br/casas-de-apuestas-todo-lo-que-debes-saber-2/ ofrecen una variedad de elecciones para los fanГЎticos. Es esencial revisar las tasas antes de realizar una apuesta. Las casas de Apuestas del mismo modo ofrecen incentivos para nuevos jugadores.
zahranicni casino online, https://firstwatchmen.com/zahranini-kasino-jak-si-vybrat-to-prave-pro-vas/ nabГzГ ЕЎirokГЅ vГЅbД›r her a moЕѕnostГ. Zde si mЕЇЕѕete poЕѕГt vzruЕЎenГ z zГЎbavy, aniЕѕ byste museli opustit domov. S modernГm technologiГm se hranГ stГЎvГЎ pohodlnГЅm.
1xbet app, https://techners.net/1xbet-korea-download-app-your-ultimate-guide-to-5/ – The platform provides a accessible way to bet on sports and games. With the capabilities available, users can participate in betting anytime, anywhere. The layout is simple, making it easy to navigate and enjoy a seamless betting experience.
Los casinos en lГnea sin licencia son un riesgo creciente en el sector del juego. Frecuentemente, estos sitios operan sin supervisiГіn, lo que pone en riesgo a los jugadores. Es vital informarse sobre los riesgos que conlleva jugar en casinos sin licencia, https://janseverhuizingen.nl/casinos-sin-licencia-seguridad-y-futuro-en-2026/.
casinos online, [url=https://tuequipomendocino.com.ar/explora-la-diversion-y-emocion-de-mi-casino/]https://tuequipomendocino.com.ar/explora-la-diversion-y-emocion-de-mi-casino/[/url] – Los salones virtuales ofrecen una experiencia de juego emocionante. Con una variedad de juegos, los jugadores pueden disfrutar de juegos de azar desde la comodidad de su hogar. AdemГЎs, bonos especiales atraen a nuevos usuarios.
Наслаждайтесь вечером — как заказать алкоголь через интернет с доставкой — быстро, удобно и без задержек.
Пользователи хвалят удобство интерфейсов и фильтров, помогающих быстро найти нужный напиток.
Логистика и соблюдение законодательства — ключевые факторы в доставке алкоголя. Курьеры проходят обучение и получают инструкции по работе с напитками и клиентами.
Качество хранения и транспортировки напрямую влияет на состояние напитков при получении. Винные и крафтовые продукты особенно чувствительны к колебаниям температуры и механическим ошпариваниям.
Маркетинг и клиентский опыт формируют лояльность в сегменте доставки алкоголя. Акции, персональные рекомендации и подписки стимулируют повторные покупки и удержание клиентов.
Магазины и службы доставки применяют изолирующие коробки и крепления для защиты бутылок при транспортировке.
zahraniДЌnГ online casina, [url=https://www.optimumhealthcaregroup.com/casinobet26022/online-kasina-v-esku-ve-co-potebujete-vdt-3/]https://www.optimumhealthcaregroup.com/casinobet26022/online-kasina-v-esku-ve-co-potebujete-vdt-3/[/url] umoЕѕЕ€ujГ hrГЎДЌЕЇm rozsГЎhlou ЕЎkГЎlu her. ProvozovatelГ© poskytujГ lГЎkanlivГ© bonusy, kterГ© pouze pЕ™itahujГ novГ© klienty. Online zГЎbava je pohodlnГЎ, a hrГЎДЌi si jijak mohou uЕѕГt z pohodlГ domova.
1xbet online, https://legittools.org/discovering-1xbet-korea-desktop-a-comprehensive/ выпускает уникальную возможность заработать РЅР° ставках. Сложная платформа даёт возможность пользователям оценивать результаты СЃ мгновенной реакцией. Рспользуйте разнообразные РёРіСЂС‹ для достижения лучших показателей.
Юрист по жилищным вопросам предлагает квалифицированную помощь по всем аспектам жилищного права, включая консультации, юридические услуги и защиту ваших прав на жильё, с учётом вашего запроса: жилищные споры юрист.
Специалист в области жилищного права — юрист, который консультирует по регистрации, регистрации прав и спорным вопросам, обеспечивая надёжную правовую помощь.
Второй абзац: Он занимается анализом документов на квартиру, проверкой договоров долевого участия, ипотеки, аренды и других сделок, чтобы минимизировать риски клиента.
Третий абзац: Специалист по жилищному праву ориентирует клиента в переговорах, претензиях и судебных процедурах ради правильного разрешения проблемы.
Раздел 2. Частые задачи и услуги
Первый абзац: Одна из ключевых услуг — сопровождение регистрации прав и смены собственника, с созданием полного пакета документов и представительством в регистрирующих органах.
Второй абзац: Специалист по жилищному праву разъясняет нюансы аренды, корректирует договоры и представляет стороны при конфликтных ситуациях.
Третий абзац: Решение жилищных конфликтов осуществляется через судебные органы, альтернативное разрешение споров или переговоры, направленные на охрану интересов клиента.
Раздел 3. Практические рекомендации
Первый абзац: Перед обращением к юристу полезно собрать все документы на объект, договоры, переписки и квитанции, чтобы ускорить процесс.
Второй абзац: Необходимо понять свою цель: сохранить жильё, уменьшить платежи или добиться обмена договора на более выгодный, и сформулировать задачу для юриста.
Третий абзац: Рекомендуется согласовать стоимость, график оплаты и план действий, чтобы не возникло скрытых платежей и вопросов по ходу дела.
Раздел 4. Кейсы и итог
Первый абзац: Случай с арендаторами часто связан с перерасчетом платы за коммунальные услуги и расторжением незаконных договоров аренды, что требует юридического вмешательства.
Второй абзац: Ещё одна ситуация — спор о доле в жилом помещении между близкими людьми, где специалист составляет соглашение и регулирует раздел по закону.
Третий абзац: Финал процесса предусматривает оформление судебного решения в реестре и отражение изменений в документах на объект.
Older Mario games super mario games play
Mi Casino, https://montanabartenders.com.br/mi-casino-la-experiencia-de-juego-en-linea-que-2/ es un lugar donde los entusiastas de los juegos de azar pueden vivir momentos emocionantes. Ofrece diversidad de juegos electrГіnicos, desde juegos de mГЎquina hasta pГіker en lГnea. AdemГЎs, las recompensas disponibles son seductores, asegurando que cada visita sea un evento memorables. Crear una cuenta es directo, permitiendo comenzar la aventura en Mi Casino.
[url=https://t.me/suspilnevolyn]R7 casino[/url]
[url=https://t.me/madofficialzerkalo]Мад казино[/url]
[url=https://t.me/beerofficialzerkalo]Бир казино[/url]
nove online casino, [url=https://asakeralasaree.com/jak-instalovat-nyni-betonred-krok-za-krokem/]https://asakeralasaree.com/jak-instalovat-nyni-betonred-krok-za-krokem/[/url] nabГzГ skvД›lГ© moЕѕnosti zГЎbavy a vГЅher. UЕѕivatelГ© si mohou vychutnat ЕЎirokou nabГdku her, od slotЕЇ aЕѕ po karetnГ hry. DovolenГ© jsou intenzivnГ, pЕ™iДЌemЕѕ vГЅhody zajiЕЎЕҐujГ extra ЕЎance na vГЅhru. K zГЎbavД› se pЕ™ipojte na nove online casino!
Бир казино
R7 casino
Бир казино
[url=https://t.me/madofficialzerkalo]Мад казино[/url]
R7 casino
1xBet Betting Online, https://www.bilindustrin.se/download-1xbet-app-for-thailand-a-complete-guide-2/ offers a wide selection of options for punters. With countless sports events and markets, users can readily place bets. The platform is known for its user-friendly interface and attractive odds.
https://mad-1casino.buzz/
http://vodka268.casino/
http://vodka269.bet/
ruleta, https://stagin.regin.com.co/la-fascinante-historia-de-la-ruleta-estrategias-y/ – La ruleta es un juego de casualidad muy popular en los casinos. Consiste en apostar en nГєmeros o colores, lo que hace que cada giro sea emocionante y interesante. Las estrategias varГan, pero la diversiГіn siempre estГЎ garantizada.
https://mad-1casino.buzz/
http://vodka268.casino/
http://vodka269.bet/
https://mad-1casino.buzz/
http://vodka268.casino/
http://vodka269.bet/
zahranicne online casino, [url=http://www.rehemastuckey.com/review/casinobet26021/nove-online-kasino-co-oekavat-a-jak-si-vybrat-to-2/]http://www.rehemastuckey.com/review/casinobet26021/nove-online-kasino-co-oekavat-a-jak-si-vybrat-to-2/[/url] nabГzГ ЕЎirokou ЕЎkГЎlu her, od automatЕЇ aЕѕ po stolnГ hry. Online hazard jsou pЕ™ГstupnГ© odkudkoli a kdykoli. MЕЇЕѕete zГskat skvД›lГ© bonusy a pЕ™inГЎЕЎГ hrГЎДЌЕЇm adrenalin pЕ™i hranГ.
Hvis du leder efter det bedste casino uden rofus, https://www.ehdf.com/moderne-online-casino-en-ny-ra-for/, er der mange muligheder at vælge imellem. De steder tilbyder fabelagtige spil, bonusser og spænding. Besøg i dag for at få glæde af det bedste.
Bolivia cuenta con diversas oferta de juegos en los mejores casinos en Bolivia, http://lapaengenharia.com.br/los-mejores-casinos-en-bolivia-guia-completa-2023-3/. Los visitantes pueden disfrutar de ruleta y eventos en un clima divertido.
dansk casino uden rofus, https://drcemento.com/index.php/2026/02/22/spil-og-casino-uden-rofus-en-guide-til-ansvarligt/ tilbyder et unikt miljø for spillere, hvor de kan nyde|opleve|fordybe sig i|deltage i de mest spændende casino spil. Uden begrænsninger kan man udforske|granske|undersøge|prøve forskellige spiltyper og strategier. Det skaber en frihedsfornemmelse, der tiltrækker mange.
To enjoy gaming on the go, you can easily access 1xbet download, https://hls-seha-sa.com/1xbet-download-app-for-pc-your-guide-to-getting/. This application allows you to bet on your favorite sports and events. With simple features, it guarantees a comfortable experience.
zahraniДЌnГ casina, https://medischpedicurefemke.nl/zahranini-kasina-jak-vybrat-to-nejlepi-pro-vae-2/ nabГzejГ jedineДЌnГ© veletrhy pro hrГЎДЌe. V tД›chto mГstech mЕЇЕѕete setkat se ЕЎirokou pestrost her a bonusovГЅch nabГdek.
Las tragamonedas online Bolivia, [url=http://www.ieptbba.com.br/site/?p=24346]http://www.ieptbba.com.br/site/?p=24346[/url] disponen una experiencia divertida para los aficionados. Puedes disfrutar de mГєltiples opciones, todos los juegos con temГЎticas Гєnicos. AdemГЎs, la seguridad de estas plataformas estГЎ garantizada. ВЎExplora las tragamonedas online Bolivia y vive la emociГіn!
Hey there! Quick qhestion that’s completely off topic.
Do you know how to make your site mobile friendly?
My weblog looks weird when viewing from my iphone. I’m trying to find a template
oor plugin that might be able to fixx this problem. If you
have any suggestions, please share. Thanks!
zahranicni casino online, https://industrialpecas.com.br/jak-se-odhlasit-z-hellspin-kompletni-prvodce/ pЕ™inГЎЕЎГ skvД›lГ© pЕ™ГleЕѕitosti pro fanouЕЎky. BezpeДЌnГ© platformy nabГzejГ vyzkouЕЎet ЕЎirokou Е™adu her v lГЎkavГЅmi vГЅhodami.
La ruleta online Bolivia, [url=https://repuestoschile.srtv.cl/index.php/la-guia-definitiva-para-jugar-a-la-ruleta-online-2/]https://repuestoschile.srtv.cl/index.php/la-guia-definitiva-para-jugar-a-la-ruleta-online-2/[/url] brinda una experiencia entusiasta para los jugadores. Mediante un entorno dinГЎmico, los jugadores son capaces de disfrutar en la excepcional calidad del juego. AdemГЎs, las promociones proporcionan de modo que la experiencia sea mucho mГЎs gratificante.
zahraniДЌnГ online casina, https://rplus-tantei.com/2026/02/26/seznam-nejlepich-sazkovych-kancelai-v-eske-7/ nabГzejГ hrГЎДЌЕЇm rЕЇznorodou nabГdku her. Zisky takovГЅch platforem ДЌasto zahrnujГ dobrГ© bonusy a snadnГЅ pЕ™Гstup. ZГЎbava ze z pohodlГ se stГЎvГЎ ДЌastД›ji populГЎrnГ.
GoldSpin casino EspaГ±a, https://mcubesfinserv.com/goldspin-casino-espana-la-nueva-era-del-juego-2/ ofrece una opciГіn Гєnica para los aficionados que buscan ocio y emociones. La sala de juegos cuenta con diversa selecciГіn de juegos que satisfacen todos los preferencias. Mediante promociones y incentivos atractivos, GoldSpin casino EspaГ±a se convierte en una excelente para intentar suerte.
Hey there! Someone in my Myspace group shared this website with us so I came to look it over. I’m definitely loving the information. I’m book-marking and will be tweeting this to my followers! Exceptional blog and brilliant design.
https://vodka268.bet/
https://vodka265.bet/
https://vodka267.casino/
https://vodka268.bet/
https://vodka267.casino/
https://vodka265.bet/
https://vodka268.bet/
https://vodka267.casino/
https://vodka265.bet/
Для строительства уютного загородного жилья идеально подходит строительство каркасных домов в спб.
Каркасный дом становится всё более популярным вариантом жилья в современных условиях.
Технология строительства опирается на деревянный или металлический каркас и утеплитель.
Хорошая изоляция снижает потребление энергии и повышает комфорт проживания.
Каркасный дом подходит для дачи, постоянного проживания и коттеджного строительства.
Las sitios de apuestas sin licencia representan una amenaza para los jugadores. Al jugar en ellas, se arriesga a perder dinero sin garantГas. Las casas apuestas sin licencia, https://hi.rumahundangan.id/ranking-de-velocidad-de-cobro-en-casas-de-apuestas/ no ofrecen seguridad, lo que puede resultar en trampas. Es crucial elegir opciones autorizadas para disfrutar de la entretenimiento de manera segura.
шумоизоляция дверей авто https://shumoizolyaciya-dverej-avto.ru
шумоизоляция торпеды https://shumoizolyaciya-torpedy-77.ru
Ищете надёжный автоматический складной нож, который сочетает в себе быстрое открытие, прочную конструкцию и современный дизайн.
Цена часто отражает качество материалов и точность изготовления, но не всегда является единственным критерием.
Los salones de juego con retiro rГЎpido son cada vez mГЎs populares. En el tipo de aplicaciones, los jugadores disfrutan de movimientos sin retrazos. A travГ©s de la tecnologГa, retirar premios es fГЎcil. ВЎNo pierdas la oportunidad de disfrutar de los casinos retirada inmediata, https://valueecoserv.cndd.ro/mejor-voucher-casino-todo-lo-que-necesitas-saber/!
Широкий выбор ковров представлен в интернет магазине нашего города Краснодар, подходящий для всех стилей интерьера.
[url=https://amikovry.uk/]Ковры со скидкой[/url]
Товары нашего магазина отличаются надежностью и долговечностью, обеспечивая выгодную покупку.
Los sindicatos en lГnea en Argentina han prosperado enormemente en los Гєltimos aГ±os. Brindan una experiencia de diversiГіn Гєnica y fГЎcil desde casa. Casinos Online Argentina, https://msimasters.com/casinos-online-en-argentina-2026-tendencias-y/ atrajo a muchos entusiastas, ofreciendo seguridad y amplitud de opciones.
Los centros Online Europeos ofrecen una experiencia Гєnica para los jugadores. Con opciones como el pГіker y la ruleta, puedes gozar desde casa. Casinos Online Europeos, https://staging.beautifulpeps.com/2026/01/23/explorando-los-casinos-online-europeos-diversion-y-4/ son la nueva ola del entretenimiento.
In the world of virtual gambling, Online Casino, https://igrejaapascentardedeus.com.br/experience-the-thrill-of-bk8-casino-singapore-25/ offers an exhilarating experience. Players can savor a wide variety of games, from slots to table games. The comfort of playing from home enhances the thrill!
Подарите своему автомобилю профессиональный уход — выбирайте детейлинг мойка кузова для безупречного результата.
Опытные технари используют профессиональные материалы и инновационные методы для защиты лакокраски.
Работы включают чистку всех поверхностей салона — сидений, обшивки, ковриков и потолка с использованием подходящих средств.
Завершающий этап — нанесение защитных составов, чтобы сохранить блеск и защитить поверхность.
Проводят восстановление мелких трещин и профилактическую пропитку, чтобы продлить срок службы кожи.
Online Casino, https://www.tommasotarullo.it/discover-the-thrills-of-bk8-casino-singapore-4/ дарит множество шансов для удовольствия. РРіСЂРѕРєРё РјРѕРіСѓС‚ выбирать РѕРіСЂРѕРјРЅРѕРµ множество РёРіСЂ Рё акций, что делает уникальный опыт РІ весь РёРіСЂРѕРІРѕР№ процесс.
свадебные платья фото каталог свадебных платьев с ценами
Online Casino, http://www.old.practicalsqa.net/discover-the-exciting-world-of-12play-singapore-17/ предоставляет уникальные шансы для любителей вызова СЃСѓРґСЊР±С‹. РРіСЂРѕРєРё РјРѕРіСѓС‚ использовать различными играми, оценивая интригующие акции Рё заманчивые программы лояльности. Каждый РёРіСЂРѕРє найдет что-то интересное для себя, играя РІ Online Casino.
Looking for a yacht? corporate yacht events in Cyprus for unforgettable sea adventures. Charter luxury yachts, catamarans, or motorboats with or without crew. Explore crystal-clear waters, secluded bays, and iconic coastal locations in first-class comfort onboard.
купить комплект проводов кабель магазин минск
Нужны столбики? мобильный столбик столбики для складов, парковок и общественных пространств. Прочные материалы, устойчивое основание и удобство перемещения обеспечивают безопасность и порядок.
Wirtualne kasyna w Polsce proponuja wiele gier zwiazanych z vulkanspiele.
vulkanspiele app https://vulkan-spiele3.com/aplikacja/
конфиденциальное лечение наркомании алматы
Постоянное наблюдение специалистов во время детоксикации снижает риск побочных эффектов.
Поддержка семьи через образовательные программы повышает шансы успешной реабилитации.
Сбалансированное питание и режим дня поддерживают организм в период реабилитации.
Многие центры в Алматы обеспечивают долгосрочные реабилитационные программы и помощь при возвращении в общество.
Online Casino, http://evraz-mag.ru/2026/01/17/exploring-god55-singapore-a-unique-online-gaming-2/ offers an entertaining experience for wagerers. With multiple games and alluring bonuses, it’s a unique destination for individuals seeking action.
Grąža (RTP) gali labai skirtis priklausomai nuo įgūdžių lygio, tačiau žaidžiant prieš kitus, sėkmę ilguoju laikotarpiu daugiausiai lemia įgūdžiai, tad profesionalų pokerį galima laikyti sportu, o mėgėjišką – labiau azartiniu lošimu. purchase generic Zoloft online discreetly buy Zoloft online generic sertraline Zoloft online pharmacy USA: Zoloft Company – buy Zoloft online without prescription USA gates of olympus oyna demo: gates of olympus guncel – gates of olympus nas?l para kazanilir buy Zoloft online: buy Zoloft online – purchase generic Zoloft online discreetly This website is using a security service to protect itself from online attacks. The action you just performed triggered the security solution. There are several actions that could trigger this block including submitting a certain word or phrase, a SQL command or malformed data.
https://canadabestcondo.com/?p=71091
buy Zoloft online without prescription USA: sertraline online – Zoloft Company sertraline online: purchase generic Zoloft online discreetly – Zoloft Company In a way, it really tends to make you to definitely read just how Microgaming surely got to the big of your software developing Olympus. Right now, many years ago, lots of the right back-in-the-days online game lookup timeless. The fresh Nuts Disco Basketball icon substitutes for the symbol besides the fresh scatter symbol. cheap Zoloft: Zoloft online pharmacy USA – purchase generic Zoloft online discreetly cheap Zoloft: Zoloft online pharmacy USA – Zoloft for sale Before going into specifics from our review of Social Casinos in Pakistan, let’s go over the key features that make the platform stand out: buy Zoloft online: cheap Zoloft – purchase generic Zoloft online discreetly
Online Casino, https://hosting07.cdcloud.it/2026/01/17/understanding-bk8-betting-odds-a-comprehensive-5/ presents a universe of thrilling games. Players can experience poker, slots, and roulette from the comfort of their living rooms. With promotion opportunities, the fun never ends.
For those seeking an exceptional online gaming experience, us.com](https://maxispin.us.com/) stands out as a premier destination. At Maxispin Casino, players can enjoy a vast array of pokies, table games, and other thrilling options, all accessible in both demo and real-money modes. The casino offers attractive bonuses, including free spins and a generous welcome offer, along with cashback promotions and engaging tournaments. To ensure a seamless experience, Maxispin provides various payment methods, efficient withdrawal processes, and reliable customer support through live chat. Security is a top priority, with robust safety measures and a strong focus on responsible gambling tools. Players can easily navigate the site, with detailed guides on account creation, verification, and payment methods. Whether you’re interested in high RTP slots, hold and win pokies, or the latest slot releases, Maxispin Casino delivers a user-friendly and secure platform. Explore their terms and conditions, read reviews, and discover why many consider Maxispin a legitimate and trustworthy choice in Australia.
Regardless of whether you’re an experienced copywriter or a newcomer, MaxiSpin.us.com offers the resources necessary to improve your content.
**Features of MaxiSpin.us.com**
A notable feature of MaxiSpin.us.com is its capability to produce content in various languages.
**Benefits of Using MaxiSpin.us.com**
MaxiSpin.us.com’s scalability allows it to meet the needs of users across various industries and sizes.
The expense associated with obtaining a passport in Vanuatu can vary. It’s important to check the current charges set by the government. Generally, vanuatu passport fees, https://bmsscentral.com/2026/01/22/understanding-vanuatu-passport-fees-and-costs/ cover service and modification fees.
В случае если вы намечаете странствие между Берлином и Польшей, целесообразно знать промежуток и варианты добраться. Так, познань берлин расстояние оценивается около 270 км, а достичь можно поездом, что практично и быстро. Помимо этого многие осведомляются, как доехать из берлина в потсдам или как доехать до берлин-бранденбург аэропорт — есть некоторое количество путей, охватывая поезд и автобус.
Для почитателей истории стоит увидеть берлинский дворец или цитадели в environs берлина, а если хочется больше деталей о направлениях и движении, рекомендую просмотреть ужгород берлин поезд . В том случае если вам нужно достичь из аэропорта берлина до автовокзала или уточнить подробности про поезда днепр-берлин или ужгород-берлин поезд, на сайте часто комментируют такие маршруты и выдают практичные советы.
The fee of obtaining a Vanuatu passport is influenced by several factors. Typically, the vanuatu passport cost, https://artwuest.com/the-comprehensive-guide-to-vanuatu-passport-price/ consists of application fees, processing times, and additional costs for expedited services.
Betwinner Betting, https://huntbconstruction.com/experience-the-thrill-of-betting-with-betwinner-12/ offers a wide range for sports enthusiasts. With attractive rates, it’s easy to see why so many people choose it. Enjoy real-time betting for an engaging experience!
Ищете идеальный дом? Посетите каталог готовых проектов и найдите готовый проект, который подходит именно вам.
Многие готовые проекты учитывают местные климатические и эксплуатационные особенности, что повышает их надежность.
Ограниченность дизайн-решений может не подойти тем, кто ищет уникальный внешний вид или нестандартную планировку.
3d забор под ключ
Эти конструкции часто изготавливают из качественной стали и покрывают антикоррозийными составами.
Фиксация панелей происходит на металлических столбах с использованием специальных крепежей.
Уход за 3D-забором несложен и сводится к периодической очистке и осмотру покрытия.
Вариативность окраски и профиля панелей даёт свободу при оформлении участка.
Производители чаще всего применяют сталь с полимерным покрытием для увеличения срока службы 3D-ограждений.
In the bustling world of online gaming, the vulkanvegas app android casino stands out as a versatile platform for players seeking excitement and reliability. It delivers smooth navigation, secure payments, and a rich library of games that appeal to both newcomers and seasoned bettors. Users appreciate the quick setup process and the intuitive interface that makes it easy to find favorite titles and new releases alike.
The app provides a solid range of slots, table games, and live dealer experiences that are designed to simulate the thrill of a real casino. With high-quality graphics and responsive controls, players can enjoy immersive sessions on the go. The Android version emphasizes fast loading times and stable performance, even on devices with modest specs. Innovative features, such as boosted bonuses and personalized recommendations, further enhance the gaming journey.
For beginners, tutorials and helpful tips are readily available within the VulkanVegas ecosystem, helping newcomers learn rules and strategies. The platform also emphasizes responsible gambling, offering tools for setting limits and monitoring activity. Regular updates ensure compatibility with the latest Android versions and security improvements. Customer support is reachable through multiple channels, providing timely assistance whenever needed.
Security and fairness lie at the core of the vulkanvegas app android casino, with encryption protocols and certified random number generators ensuring trusted play. Users can deposit and withdraw using a variety of methods, backed by robust fraud detection and transparent terms. The app maintains a clear privacy policy and strong data protection measures to safeguard personal information. Overall, the Vulkan Vegas Android app offers a compelling blend of accessibility, entertainment, and safety for casino enthusiasts on mobile devices.
vulkan vegas mobile https://vulkan-vegas.nz/app/
В Краснодаре наш интернет магазин ковров предоставляет разнообразие товаров для оформления вашего дома.
[url=https://amikovry.uk/]Посмотреть ковры онлайн[/url]
Для нас важно, чтобы покупатели получили свои ковры в срок и без повреждений.
Exploring the universe of casino online, https://outsource.ienetworks.co/decouvrez-betwinner-votre-guide-complet-pour-les-3/ offers infinite entertainment options. Players can experience a variety of games such as slots, poker, and blackjack. Enter this exciting digital playground for an electrifying gaming adventure!
We perform checks on reviews The main reason to play this sea-fishing-themed slot is to catch the big bass scatters that trigger its exciting free spin feature. Hit three scatters, and you’ll play ten free spins, while four and five scatters respectively trigger 15 and 20 free spins. During the feature, wild anglers also appear and collect the values from the big bass bonanza money symbols. Bigger Bass Bonanza sets sail for a flashier harbor, hauling in even bigger wins. This sequel cranks up the excitement with a boosted max win potential and a couple of extra payout lines. While the familiar fishing theme remains, there is a visual upgrade with a vibrant harbor scene instead of the original’s underwater world. Bigger Bass Bonanza is without doubt an enticing offering in the UK online casino scene. With its vibrant theme, well thought-out bonus mechanics, and widespread availability, it appeals to seasoned slot enthusiasts as well as newcomers. Whether you’re fishing for fun in demo mode or aiming for those hefty multipliers in real money play, this slot is set to keep UK players hooked.
https://septicsol.net/?p=87837
On mobile, the UI keeps tumbling chains readable, and quick-spin turbo options help compress the time between outcomes. At Mostbet, round history and autospin controls make it easy to track results and keep stakes consistent while you hunt for Zeus’s orbs. Slotsites is an independent site that provides information, reviews, and recommendations on online slots and casinos. It is your responsibility to ensure you comply with all legal requirements for gambling online including age and location restrictions. This site is intended for visitors 18+ years of age. Please play responsibly. Gates of Olympus Xmas 1000 is a festive, holiday-themed version of the slot. The core gameplay and theme remain the same, but the reels are dusted with snow and decorated with Christmas ornaments. As with the 1000 edition, the maximum win potential is 15,000x your stake.
In the domain of sports betting, http://berrysportsmedicine.ie/2026/02/07/rivalo-a-revolucao-das-apostas-online-no-brasil-2/, many enthusiasts look for ways to enhance their probabilities of winning. Comprehending sports statistics and trends is vital for successful betting strategies.
Amid the world of entertainment, casino online, http://www.sunitex.com.hk/betwinner-la-mejor-opcion-para-apostar-online/ has garnered immense popularity. Users are drawn to the convenience of playing from home. Through modern technology, the adventure is just a push away.
sports betting, https://www.orcosildigital.com.br/2026/02/07/betwinner-la-mejor-plataforma-de-apuestas-2/ – Sports betting has experienced immense popularity in recent months. Aficionados analyze various competitors and strategies to make educated decisions.
Если вы мечтаете о надежном и теплом жилье, обратите внимание на дома каркасные спб, которые сочетают качество, скорость возведения и доступную стоимость.
Причина этому — их экономичность и скорость возведения.
Если вы хотите надежно огородить свой участок, рекомендуем забор из 3д сетки под ключ, который сочетает в себе прочность и современный дизайн.
Металлическая основа позволяет таким заборам противостоять сильным повреждениям и внешним воздействиям.
In the world of digital entertainment, casino online, https://geoconsultor.cl/decouvrez-betwinner-la-reference-des-paris-en-5/ has become a popular choice for many. Players can delight in a wide variety of games from the comfort of their homes. Due to advanced technology, animation have significantly improved, offering a engaging experience than ever before. Furthermore, incentives add to the excitement, attracting novel users.
https://vodkab.bet
Betwinner Betting, https://nekudat-mifgash.net/?p=17767 offers enticing opportunities for events enthusiasts. With diverse betting options, users can easily place their wagers. The platform boasts a user-friendly interface, making it easy for all to join in on the action.
Beberapa teknologi yang kami gunakan diperlukan untuk fungsi penting seperti keamanan dan integritas situs, autentikasi akun, preferensi keamanan dan privasi, data penggunaan dan pemeliharaan situs internal, dan agar situs berfungsi dengan benar untuk penelusuran dan transaksi. Cabernet SauvignonCoastal Vines, California5oz… $11 9oz… $19 bottle… $55Aromas of berries and toast open up to flavours of ripe plums, red raspberries, and vanilla on the palate with a smooth, fruity finish. Curious to try it before committing? Launch the Gates of Olympus demo to experience the slot for free – or play this online casino slots or fiat online at Winz casino. A: You can play Gates of Olympus in Rands at only the top South African online casinos. It’s part of the famous spina zonke at Hollywoodbets, too. You can also find it in casinos like Playa Bets, YesPlay, and Gbets.
https://jobs.thenivy.com/royal-reels-online-casino-game-review-for-australian-players/
Benefits of YouTube video editor online Yes, VSDC Free Video Editor is a non-linear editor that supports professional-grade features like motion tracking, chroma key, and blending modes. It’s ideal for small businesses, influencers, and advanced hobbyists looking for a free yet robust editing tool. Now it’s time to remove the distractive logos or watermarks from your video clip. To do that, click the Remove Watermark tab and then top the Select Area button. After that, adjust the cropper by dragging it to cover the video section with a logo or watermark. Finish up by selecting a folder path on File Location and then press Remove Watermark to process your non-watermarked video. In addition to removing text from video, Fotor also provides an array of related features. You can effortlessly remove video backgrounds for new backdrops swap, enhance visual appeal by eliminating unwanted objects, or create unobstructed landscape videos through person removal. Just access the Fotor remover tool to eliminate any photobombers from your video.
To start your betting journey, Betwinner Registration, https://uniqueinterior.org/2026/01/25/1xbet-panduan-lengkap-untuk-pengguna-indonesia/ is essential. After completing the sign-up process, you can enter your account. This platform offers a wide range for users to enjoy exciting betting opportunities.
Betwinner Online, http://shop.westernboots.com.ua/?p=208655 снабжает уникальные опции для казино на развлечение. С данным ресурсом вы можете наслаждаться широкими опциями. Служба поддержки пользователей обеспечивается в любое время, чтобы поддержать вам.
Betwinner Casino, https://www.nexc.cloud/discover-the-exciting-world-of-betwinner-your-4/ содержит широкий панораму развлечений для игроков. Насладитесь слоты и настольные игры. В этом месте любой найдет что-то интересное для себя!
Betwinner Betting, https://competenciastransversales.pucv.cl/?p=119173 is a leading platform for sports wagering. Users can find countless events to bet on, making it excellent for both seasoned bettors.
Если вы хотите улучшить самочувствие и восстановить энергию, советуем ознакомиться с детокс программы для очищения, которые помогут организму эффективно очиститься и вернуться к здоровому балансу.
Детокс-программы для очищения организма играют важную роль в поддержании баланса и гармонии в теле. Такие программы способствуют удалению токсинов и шлаков из организма . Эти программы положительно влияют на состояние организма в целом. Ниже описаны основные характеристики и полезные эффекты детокс-программ.
Основное начало детокс-программы связано с подготовкой организма. Следует отказаться от употребления продуктов с высоким содержанием токсинов. Также нужно увеличить потребление чистой воды и натуральных соков . Такая фаза может занять около трех-пяти дней и служит фундаментом для детокса .
В этот период в рацион включаются средства для усиления очистки. Популярностью пользуются напитки из трав и свежие овощные коктейли . Активные компоненты способствуют улучшению метаболизма и укреплению иммунитета. Соблюдение всех правил использования детокс-продуктов необходимо для успешного очищения.
В конце курса происходит стабилизация и поддержание достигнутого эффекта . В это время рекомендуется плавно возвращаться к обычному рациону, избегая вредных продуктов . Регулярное употребление воды и умеренные физические нагрузки продолжают очищение . Эти программы помогают наладить внутреннюю гармонию и улучшить качество жизни.
Если вы хотите купить забор 3д от производителя в москве, обращайтесь к нам для выгодных условий и высокого качества.
При покупке забора 3Д от производителя в Москве вы получаете гарантию качества и соответствие всем стандартам безопасности.
Betwinner Registration, https://helpershq.com/index.php/2026/01/25/betwinner-une-plateforme-de-paris-en-ligne-2/ is a straightforward process that allows users to join the platform easily. You need to provide your data and confirm your registration. After that, you can start enjoying the diverse range of betting options available.
Betwinner Online, http://www.old.practicalsqa.net/the-ultimate-guide-to-baji-live-your-gateway-to-a/ offers an impressive range of betting opportunities for enthusiasts. With a seamless experience, users can enjoy gaming effortlessly. Explore in-play betting features to enhance your excitement!
Betwinner Casino, https://dfysalefunnel.com/2026/01/25/betwinner-34/ открывает широкий разнообразие азартных приключений. В этом месте вы найдете игровые автоматы и новейшие варианты. Пользователи могут ценить качественным обслуживанием клиентов.
Betwinner Betting, https://www.crownmutual.com/2026/01/25/betwinner-botswana-your-ultimate-betting-4/ is an exciting platform for enthusiasts. The platform delivers a wide range of options to place bets on various sports events. Combining user-friendly interfaces, gambling becomes accessible and enjoyable.
sports betting, https://dralpinguneri.com/2026/02/07/decouvrez-betwinner-la-plateforme-de-paris-en-16/ – Sports betting is now a rising hobby for many fans. As the growth of online platforms, bettors can readily place their investments from anywhere.
Статья предлагает объективный обзор исследований, проведенных в данной области. Необходимая информация представлена четко и доступно, что позволяет читателю оценить все аспекты рассматриваемой проблемы.
Playing in casino online, https://etiqwise.com/explore-the-betwinner-site-your-ultimate-online/ has become a common pastime for many. By using the wide range of games, players can experience their favorites anytime. Incentives add more excitement to the gaming experience!
sports betting, http://www.creekwoodcustomhomes.com/greenhill – Sports betting has become a popular pastime for many enthusiasts. Bettors often analyze numbers to make informed decisions. By understanding lines, one can maximize their chances of winning.
Для безопасной игры и получения бонусов посетите fugu casino скачать.
Портфолио игр включает классические слоты, рулетку, покер и многое другое.
Playing on casino online, https://royal.max-edu.com.au/betwinner-your-ultimate-betting-experience-56/ offers entertaining experiences for players. With numerous variety of games presented, it’s easy to find anything that suits your style. Plus, convenience is unmatched!
sports betting, https://scorpmeds.com/aposte-com-confianca-descubra-o-mundo-das-apostas/ – Sports wagers has gained immense popularity among fans and gamblers alike. Comprehending the odds and strategies can enhance your chances of winning. Research teams and players to make informed decisions.
Вам наверняка пригодится ножи складные автоматический, если вы ищите надежное и стильное решение для самообороны и каждого образа жизни.
Общий вид ножа на дереве
Ножи могут быть разработаны для различных целей, таких как охота, самооборона или просто как предмет спортивного интереса. Отличительные особенности этих ножей включают в себя автоматическую установку, складную конструкцию и часто высококачественную сталь.
– Ножи с алмаза могут быть более лёгкими и менее глупыми
Некоторые модели могут быть оснащены дополнительными функциями, такими как подсветкой, подсоединением или системами безопасности, что делает их еще более привлекательными для их владельцев.
– Отличительные особенности могут включать в себя неоновую подсветку
Есть несколько известных брендов, которые производят таких ножей, такие как Cold Steel, Kershaw и Spyderco.
– Spyderco славится своими острыми лезвиями
Перед тем как выбрать модель, важно рассмотреть ваши конкретные потребности, включая размер, функциональность и стоимость.
– Стоимость может быть значительна для спортивного интереса
– Система безопасности может быть оснащена блокатором
Некоторые модели могут включать в себя подсказки по использованию, что помогает новичкам в освоении эксплуатации ножа.
– Подсказки может быть включены в приложения на телефоне
Дизайн и конструкция этих ножей могут быть оснащены advanced-materials и современными технологиями, что может повысить их надежность и долговечность.
– Ножи могут быть изготовлены из высококачественных материалов
Функциональность этих ножей может быть увеличена с использованием advanced-components и инновационных технологий.
– Возможности использования могут быть увеличены при использовании спецприложения
Безопасность и сертификация являются важными факторами при выборе автоматического складного ножа.
– Качество должно быть гарантировано производителем
Некоторые ножи могут быть оборудованы системами безопасности, такие как блокировка или система предупреждения о критическом уровне, для предотвращения несчастных случаев.
– Предупреждение может быть включено при достижении уровня
Время от времени, эти ножи проходят строгую оценку и тестирование для проверки их надежности и безопасности.
– Ножи проходят проверку на прочность
Производители могут работать с экспертами для обеспечения того, чтобы ножи соответствовали всем необходимым стандартам.
– Дизайн может быть изменен по результатам тестирования
Оценка этих ножей может включать в себя анализ конструкции, функций и различных аспектов, направленных на удовлетворение потребностей и ожиданий владельцев.
– Анализ может быть сосредоточен на производительности
Этот раздел направлен на предоставление оценки различных моделей автоматических складных ножей и рекомендаций для потенциальных покупателей.
– Оценка может быть сосредоточена на производительности
Некоторые рынки могут предложить широкий выбор автоматических складных ножей с разными функциями и технологиями.
– Ножи могут быть доступны в местных магазинах
Перед покупкой важно рассмотреть качество, стоимость, функциональность и безопасность ножа во всех аспектах.
– Качество должно быть гарантировано производителем
В результате покупателям могут быть предложены лучшие варианты для их потребностей и желаний.
– Покупатель может быть предоставлен с возможностями
Независимо от выбора, каждый человек может оценить и рекомендовать автоматический складной нож на основе собственных потребностей и экспериментов с ним.
– Это будет обеспечено экспериментальными данными
Узнайте больше о система RODE Wireless PRO москва и получите высокое качество звука для ваших проектов!
RODE Wireless PRO представляет собой популярное устройство для создания высококачественных записей. Эта система была разработана с учетом инновационных решений.
Ее основная цель — обеспечить высокое качество звука при минимальных капризах . В добавление, система интуитивно понятным интерфейсом .
Одним из главных преимуществ RODE Wireless PRO является высококачественный звук . Разработчики потратили много усилий на исключение помех.
Кроме того, система поддерживает , что делает ее универсальным продуктом . Долгое время работы устройства обеспечивает стабильную передачу звука без перерыва .
Использовать RODE Wireless PRO практически легко . Установка системы осуществляется в несколько этапов , что экономит время .
Пользователи отмечают, что широкий спектр параметров позволяют добиться максимально оптимальных результатов . Эта система идеально подходит как для занятий на открытом воздухе, так и для профессиональных передач .
В заключение, RODE Wireless PRO является отличной системой для профессиональных аудиозаписей . Инновационные технологии сделали ее популярной среди многих профессионалов .
Если вы планируете приобрести систему для передачи звука , то RODE Wireless PRO может стать для вас. Обратите внимание на возможности, которые она предлагает !
In the world of virtual gaming, casino online, https://chaihouse.menuqtr.com/index.php/2026/02/06/exploring-1xbet-the-ultimate-online-betting-3/ offers a thrilling experience. Players can delight in a variety of activities from the comfort of their homes. Security and trustworthiness are essential for reliable gaming.
Я оцениваю объективность и непредвзятость автора в представлении аргументов и фактов.
Within the world of sports betting, https://alexsalonacademy.com/1xbet-the-ultimate-betting-experience-7/, strategies play a crucial role. Recognizing the odds can substantially enhance your chances of winning. Analyzing teams and players is vital for success.
Playing at a gaming hall online offers a unique adventure. With various games and captivating bonuses, casino online, https://www.claritycontentservices.com/wp/?p=5469 caters to every type of player. Join today and explore the fun!
Ai tempi di internet, il modo di procurarsi prodotti sanitari
è cambiato in modo significativo .
Un pubblico sempre più vasto cercano una farmacia su internet per la semplicità e la
consegna express , oltre che per la anonimato .
Quali accorgimenti prendere tra i molte opzioni disponibili?
La prima classificazione da fare è tra una punto vendita tradizionale e una
farmacia digitale nazionale .
Nel contesto di e-commerce farmaceutico senza obbligo di ricetta ,
è essenziale controllare che il sito sia ufficiale
dalle normative del Ministero della Salute .
Nel Bel Paese , tutte le farmacie digitali devono visualizzare uno speciale logo identificativo .
È molto utile cercare una Farmacia senza ricetta per fastidi
quotidiani , ma la attenzione non è mai da sottovalutare .
Un caso interessante è rappresentato da la officina farmaceutica con sede in quel di Buccino
. La popolazione del salernitano o cerca in particolare una
pharmacy campana con servizio e-commerce, vuole probabilmente un servizio
di fiducia.
Una presidio sanitario locale che offre anche store digitale rappresenta il miglior compromesso
tra la affidabilità del rapporto umano e la comodità
del digitale.
La ricerca di una store online Buccino senza ricetta è molto frequente .
I clienti vogliono verificare se possono ordinare prodotti senza
fare una visita medica .
A ben vedere , anche una farmacia Buccino libero
accesso deve rispettare le regole: i farmaci con ricetta medica
obbligatoria non possono in alcuna circostanza essere venduti a distanza senza ricetta, nemmeno da una store online italiano legittimo .
Per chi si sposta o vive all’estero momentaneamente , cercare una Farmacia Italia all’estero può essere problematico
. Quindi , affidarsi a una store digitale italiano garantisce la qualità e la validità delle
sostanze .
È importante notare che la assistenza di un professionista abilitato è facilmente raggiungibile ,
sia tramite chat .
Tirando le somme , che tu abbia bisogno di suggerimenti
da una operatore sanitario di riferimento o che tu tenda
a ordinare da una rivendita telematica ,
l’ determinante è adottare un canale approvato .
Il termine “Farmacia senza ricetta” o “Farmacia online senza ricetta Italia” si riferisce principalmente a
prodotti SOP , complementi dietetici e prodotti di igiene .
Nell’evenienza particolare di una rivendita Buccino a distanza ,
la protezione della salute viene al primo posto e il farmacista resta il tuo fondamentale alleato .
Considera che : dietro ogni acquisto su un sito
approvato , c’è sempre un specialista che ti consiglia .
https://localitybiz.com/bari/farmacia-a-gravina-in-puglia
Over the past years, sports betting, https://regal.staging.electricvine.com/index.php/2026/02/06/the-ultimate-guide-to-1xbet-sports-betting-casino-3/ has gained significant popularity among fans of various sports. Given advances in technology, making bets has become more accessible, allowing numerous people to engage in this thrilling activity.
Playing online casino offers an exciting experience for enthusiasts. Individuals can enjoy a wide range of games from the comfort of their living room. Many platforms provide generous bonuses to draw in novice users. So, if you decide to play online casino, https://www.condomi.com.br/2026/02/02/the-rise-of-winza-betet-a-comprehensive-guide/, be ready for exciting adventures and potential winnings!
Вам наверняка пригодится нож складной автоматический купить, если вы ищите надежное и стильное решение для самообороны и каждого образа жизни.
Видео изображение с автоматической установкой
Ножи могут быть разработаны для различных целей, таких как охота, самооборона или просто как предмет спортивного интереса. Отличительные особенности этих ножей включают в себя автоматическую установку, складную конструкцию и часто высококачественную сталь.
– Бесшовные изделия из чугуна могут быть более выносливыми
Некоторые модели могут быть оснащены дополнительными функциями, такими как подсветкой, подсоединением или системами безопасности, что делает их еще более привлекательными для их владельцев.
– Подсоединение для подключения к телефону
Есть несколько известных брендов, которые производят таких ножей, такие как Cold Steel, Kershaw и Spyderco.
– Spyderco славится своими острыми лезвиями
Перед тем как выбрать модель, важно рассмотреть ваши конкретные потребности, включая размер, функциональность и стоимость.
– Размер может быть важен в случае с охотничьими ножами
– Подсоединений для подключения к телефону может быть несколько
Некоторые модели могут включать в себя подсказки по использованию, что помогает новичкам в освоении эксплуатации ножа.
– Подсказки может быть выводятся на экране компьютера
Дизайн и конструкция этих ножей могут быть оснащены advanced-materials и современными технологиями, что может повысить их надежность и долговечность.
– Ножи могут быть изготовлены из высококачественных материалов
Функциональность этих ножей может быть увеличена с использованием advanced-components и инновационных технологий.
– Возможности использования могут быть увеличены при использовании спецприложения
Безопасность и сертификация являются важными факторами при выборе автоматического складного ножа.
– Внешний облик должен соответствовать местным законам
Некоторые ножи могут быть оборудованы системами безопасности, такие как блокировка или система предупреждения о критическом уровне, для предотвращения несчастных случаев.
– Блокировка может быть включена при нажатии кнопки
Время от времени, эти ножи проходят строгую оценку и тестирование для проверки их надежности и безопасности.
– Ножи проходят проверку на прочность
Производители могут работать с экспертами для обеспечения того, чтобы ножи соответствовали всем необходимым стандартам.
– Выпуск может быть отложен на время
Оценка этих ножей может включать в себя анализ конструкции, функций и различных аспектов, направленных на удовлетворение потребностей и ожиданий владельцев.
– Оценка может быть сосредоточена на качестве производства
Этот раздел направлен на предоставление оценки различных моделей автоматических складных ножей и рекомендаций для потенциальных покупателей.
– Оценка может быть сосредоточена на технологиях и функциях
Некоторые рынки могут предложить широкий выбор автоматических складных ножей с разными функциями и технологиями.
– Ножи могут быть доступны в местных магазинах
Перед покупкой важно рассмотреть качество, стоимость, функциональность и безопасность ножа во всех аспектах.
– Функциональность должна быть адекватной
В результате покупателям могут быть предложены лучшие варианты для их потребностей и желаний.
– Покупатель может быть предоставлен с вариантом
Независимо от выбора, каждый человек может оценить и рекомендовать автоматический складной нож на основе собственных потребностей и экспериментов с ним.
– Это будет обеспечено руководством эксперта
Для безопасного и удобного ношения в повседневной жизни рассмотрите ножи складные автоматические выкидные с прочной рукоятью и надежным фиксатором.
Приобретайте ножи у надёжных брендов, интересуйтесь гарантийными обязательствами и репутацией продавца и производителя.
Узнайте больше о система RODE Wireless PRO цена и получите высокое качество звука для ваших проектов!
беспроводная система RODE PRO представляет собой популярное средство для создания высококачественных записей. Эта технология была разработана с учетом инновационных решений.
Ее характеристика — обеспечить надежную передачу сигнала при максимальной мобильности . Также , система имеет .
Одним из главных преимуществ RODE Wireless PRO является превосходная передача аудио . Инженеры потратили много усилий на оптимизацию частотного диапазона .
Кроме того, система разнообразным оборудованием, что делает ее универсальным решением . Долгое время работы устройства обеспечивает стабильную передачу звука без перерыва .
Использовать RODE Wireless PRO удивительно удобно. Запуск системы осуществляется в несколько шагов, что упрощает процесс .
Пользователи отмечают, что широкий спектр параметров позволяют добиться максимально оптимальных результатов . Эта система идеально подходит как для занятий на открытом воздухе, так и для профессиональных передач .
В заключение, RODE Wireless PRO является выдающимся продуктом для профессиональных аудиозаписей . Уникальные разработки сделали ее востребованной среди энтузиастов аудио.
Если вы рассматриваете систему для работы с аудио, то RODE Wireless PRO будет хорошим выбором для вас. Не упустите возможности, которые она предлагает !
Для надежной защиты вашего бассейна и сохранения чистоты воды выберите подходящий тент, например купить тент для бассейна.
У разных материалов есть собственные сильные стороны по прочности, массе и стоимости.
online casino, https://crackjin.net/win-aura1-ihr-weg-zu-einem-erfolgreichen-online/ are entertaining venues for gamblers. Providing a variety of selections, these platforms guarantee pleasure and options to win.
online casino, https://www.futuredigitaleconomy.com/betcasino010213/scopri-il-mondo-di-vegasino-casino-e-giochi-online-2/ offers a lively way to experience wagering from the comfort of your place. With numerous options available, players can find their ideal slot.
In the exciting world of online gaming, casino online, https://leilalinhas.com.br/cocoa-casino-an-exciting-journey-through-online/ offers thrilling experiences. Players can experience a variety of activities from the comfort of their homes. With reliable transactions, it’s never been easier to achieve big!
online sports betting, https://www.maxihostcorp.com/exploring-tk11-bet-the-future-of-online-betting-3/ has become widely accepted among enthusiasts. As fans seek new ways to engage, services offer exciting opportunities to place wagers on their favorite games.
sports betting, https://www.homeimprovementsj.com/betcasino010212/experience-the-thrill-at-mrspin9-casino/ – Wagering on sports is an exciting way to engage with your favorite games. It offers opportunities for fans to enhance their experience and potentially earn profits. Comprehending odds is crucial for success.
online casino betting, https://mondaypick.com/descubre-el-mundo-del-platino-casino-diversion-y-2/ has become immensely popular in recent years. Gamblers discover new ways to delight in their favorite games. With the proliferation of technology, players can easily access their favorite games from the comfort of their homes.
online casino sports betting, https://blog.megaleiloes.com.br/reylucky-casino-descubre-la-diversion-y-aventura/ offers an exciting way to engage in sports. Through various platforms, participants can place bets on numerous events, improving the thrill of watching their favorite teams.
Я считаю, что Вы ошибаетесь. Могу это доказать. Пишите мне в PM, пообщаемся.
Pin-Up Casino, http://kasprowicz.az.pl/nauczyciele-2/statut/ es un lugar ideal para los seguidores de los juegos de azar. AquГ, los jugadores pueden disfrutar de mГєltiples opciones de diversiГіn. Con un estilo atractivo y bonificaciones interesantes, Pin-Up Casino ofrece una aventura Гєnica. ВЎNo te pierdas la oportunidad de ganar a lo grande!
Очень забавное сообщение
мобильное казино, https://store.ysgt.cn.com/betera-casino-vashi-luchshie-shansy-na-vyigrysh/ стало популярным способом развлечения. Игроки могут наслаждаться азартными играми где угодно. Удобство мобильных приложений привлекает всё больше людей. Игры различные и доступны, что делает уникальный опыт азартных игр.
play online casino, http://users.atw.hu/angaeskuvo/wordpress/?p=55490 and experience the thrill of winning from the comfort of your home. Join in various games that provide excitement and rewards. Discover a wide selection of options, ensuring there’s something for everyone.
online casino, https://jaybabani.com/ultra-wp-admin/?p=161816 presents an thrilling way to have fun popular games from the ease of your home. Players can choose a wide variety of alternatives.
Полностью разделяю Ваше мнение. В этом что-то есть и это хорошая идея. Я Вас поддерживаю.
казино онлайн, https://www.ehdf.com/jelitnoe-onlajn-kazino-vash-putevoditel-v-mir/ стало популярным местом для развлечений и выигрышей. Пользователи могут наслаждаться различными видами играми, не выходя из дома. Классные бонусы и промо-коды делают азарт более интересным.
1win приложение android 1win52609.help
In the world of internet casinos, online casino, http://transtuts.com.br/?p=949686 platforms have gained immense popularity. Players enjoy a range of games, from fruit machines to table games. With rewarding offers, it’s easy to see why many flock to these sites for thrilling experiences.
Я думаю, что Вы не правы. Я уверен. Могу это доказать. Пишите мне в PM, обсудим.
онлайн казино, https://learn.realharmonytechnologies.com/2026/02/08/kriptovaljutnaja-sistema-kazino-budushhee-igry-i/ предоставляет уникальные перспективы для любителей развлечений. Игроки могут открывать множество приключений. Удобство использования из дома привелекает новых гостей. Онлайн казино регулярно меняет свой ассортимент, что каждый найдет что-то.
шумоизоляция авто https://vikar-auto.ru
Здравствуйте дорогие друзья! Стоит заранее разобрать — протечки в квартирах последнего этажа. Здесь такой момент: управляющая компания тянет — нужны профессионалы. Вот проверенные: https://montazh-membrannoj-krovli-spb.ru. На практике крыши многоэтажек — давно требуют замены. В общем латать бесполезно — значит пора ставить мембрану. Общие рекомендации: провести собрание. Вместо заключения: это отличные параметры — протечек больше нет.
In recent years, the realm of casino online, https://www.inspiredtraveller.in/the-rise-of-speed-betting-a-new-era-in-online-10/ has expanded rapidly. Players now enjoy an array of games from the comfort of their homes. By utilizing state-of-the-art technology, online casinos provide a thrilling experience, ensuring entertainment and potential winnings.
Вы отдалились от беседы
Wallet Avalanche, https://eleccionespresidencialeschile.cl/el-alcalde-vodanovic-aboga-por-sanciones-ejemplificadoras-en-el-caso-de-cathy-barriga-argumentando-que-nos-falta-plata-para-todo/ is a revolutionary cryptocurrency wallet that provides secure storage for your cryptos. With its user-friendly interface, Wallet Avalanche enables instant transactions and smooth management of your collection.
Полностью разделяю Ваше мнение. Я думаю, что это отличная идея.
Not on Gamstop Casinos, http://reecesafetym2.stagingapplications.com/blog/exploring-non-gamstop-uk-casino-sites-a-2/ – Not on Gamstop Casinos provide an excellent opportunity for players to explore a variety of games. These casinos deliver a large selection of slot machines and table games, ensuring a thrilling gaming experience. Players can enjoy the freedom of options without restrictions.
online sports betting, https://mqconsultancy.com/la-fascinante-relacion-entre-la-mafia-y-los/ has become in recent years. A lot of fans engage in this captivating activity, heightening their experience. With various platforms, users can execute bets on their favorite teams and events.
На мой взгляд, это интересный вопрос, буду принимать участие в обсуждении.
Алексеевское сельское поселение, https://dd.geneses.fr/2014/11/mif-2014/ находится в живописном районе, привнося местную культуру и историю. Здесь есть шанс насладиться природой и изучить достопримечательностями. Местные жители известны своим очарованием.
Можно восполнить пробел?
Casinos Not on Gamstop, https://die-christen.co.za/2026/02/15/exploring-hidden-gems-casinos-that-are-not-on-the-5/ offer players a chance to enjoy gambling without restrictions. Such types of casinos provide unique choices, allowing for more flexibility. Players can explore different options and enjoy responsible gaming.
zahraniДЌnГ online casino, https://store.ampinc.com/casino-bez-oveni-jak-si-uit-hrani-bez-zbytenych/ nabГzГ hrГЎДЌЕЇm ЕЎirokou ЕЎkГЎlu moЕѕnostГ. DГky poutavГЅm bonusЕЇm se stГЎvГЎ stГЎle oblГbenД›jЕЎГ. HrГЎДЌi mohou brat zajГmavГ© ДЌГЎstky z pohodlГ domova. BezpeДЌnГ© hranГ je na prvnГm mГstД›.
sports betting, http://www.easenet.jp/wordpress/discovering-mela-bet-the-all-in-one-betting/ – Sports gambling has become a popular pastime for many enthusiasts. Comprehending the odds and approaches can significantly improve your odds of winning. Always analyze past performances before placing bets.
ЕПТИ СПС ОГРОМНОЕ
online Casino, http://ime.nu/amd-distribution.com%2Fcricket-soccer-more%2F remains a popular entertainment option for many. With its diverse offerings of games, players are able to experience thrilling slots from the comfort of their homes.
Я считаю, что Вы ошибаетесь. Предлагаю это обсудить. Пишите мне в PM, пообщаемся.
Not on Gamstop Casinos, https://ugandajamaat.net/exploring-uk-online-casinos-not-on-the-gambling/ offer players a unique gaming experience. These types of of casinos provide chances for enjoyment without boundaries. Players can explore various games beyond Gamstop’s influence.
foreign online casinos, http://marthataylorviolin.com/zahranini-online-casino-objevte-nejlepi-herni/ poskytujГ rЕЇznГ© zГЎbavnГ© pro hrГЎДЌe. Lze si vybrat z ovД›Е™enГЅch her, jakГЅmi jsou automatЕЇ aЕѕ po ЕѕivГ© akce. ZkuЕЎenosti z tД›chto internetovГЅch kasin jsou rovnД›Еѕ prostoupeny o ЕЎanci poznat atraktivnГ jackpoty.
online casino betting, https://alhindhealthtourism.com/meda-bet-exploring-the-future-of-online-betting-4/ is becoming increasingly popular among gamblers. Players appreciate the comfort of playing from home. Offering numerous games, everyone can find something they like. Furthermore, the chance to win adds to the allure of online casino betting.
Тема интересна, приму участие в обсуждении. Я знаю, что вместе мы сможем прийти к правильному ответу.
, https://ba-bamail.com/goto/http:/www.frontpagedetectives.com%2Fp%2Fdingdingding-your-1-free-to-play-online-social-casino – Технологии успешно внедряются с каждым днем. Это создаёт новые возможности в разных сферах. Образование, медицина и бизнес претерпевают благодаря инновациям. Мы можем адаптироваться к этим изменениям, чтобы обеспечить конкурентоспособность. Некоторые технологии уже внедрены в повседневную жизнь, что повышает результативность работы. Понимание современных трендов обеспечивает залогом успешного будущего.
Это весьма ценное сообщение
Not on Gamstop Casinos, https://blend1047.com/discover-the-best-casino-sites-not-on-gamstop-7/ offer players a unique opportunity to gamble freely without restrictions. Such casinos provide various games and promotions that lure many enthusiasts. Uncover a world of fun!
1вин депозит http://1win52609.help/
1win статистика http://www.1win52609.help
mezinГЎrodnГ online casino, https://rababpaintingservices.com.au/the-best-casinos-in-the-czech-republic-a-2/ umoЕѕЕ€uje hrГЎДЌЕЇm rozsГЎhlou nabГdku zГЎbavy. ZГЎkaznГci mohou vyuЕѕГt vynikajГcГ vГЅbД›ry a fantastickГ© bonusy.
In the world of digital wagering, online casino sports betting, https://ppghtx.com/a-comprehensive-guide-to-spinfred-casino/ has become increasingly popular. Many players enjoy the thrill of placing bets on their favorite teams. The ease of access and variety of options make it an attractive choice for enthusiasts.
Я думаю, что Вы не правы. Я уверен. Могу это доказать.
Cashoomo casino, https://fatherbroom.com/es/2013/01/como-vivir-el-sacramento-de-matrimonio/ provides an exciting betting experience with a wide assortment of activities. Participants can experience various classic slots to new table games. Join Cashoomo casino and find out your preferred games today!
Да ну…
Casinos Non on Gamstop, https://www.e-sicase.com/casinos-not-on-gamstop-uk-your-guide-to-3/ offer players a chance to enjoy online gaming without the restrictions imposed by UK regulations. These platforms provide various games, including slots, table games, and live dealer options. Players can experience thrilling gameplay along with generous bonuses and promotions. The flexibility of such casinos ensures an engaging environment for enthusiasts seeking excitement. Furthermore, customer support is often helpful, ensuring that players enjoy a seamless experience.
HranГ v online kasinu mЕЇЕѕe bГЅt zГЎbavnГ©, ale dЕЇleЕѕitГ© je vybrat si bezpeДЌnГ© zahraniДЌnГ casino, https://rakennus.jdmmediagroup.com/2026/02/11/nejlepi-online-kasina-jak-najit-to-prave-pro-vas/. V takovГ©m pЕ™ГpadД› najdete bezpeДЌnГ© moЕѕnosti, kterГ© poskytujГ spravedlivГ© hry a uЕѕivatelskou podporu.
If you love excitement, try to play online casino, https://lacasaenelaire.cl/2026/01/30/understanding-the-basics-of-legos-bet-a/ games. You can find a wide range of options, including slots to table games. Savor the thrill of winning from anywhere!
Советую Вам поискать сайт, со статьями по интересующей Вас теме.
L’assicurazione di viaggio, http://itrgworld.com/get_video/aHR0cHM6Ly93d3cuZ3JlYXRiZXRzLmNvLnVrL2FmZm9yZGFibGUtZXVyb3BlYW4tY2l0aWVzLWV2ZXJ5LWZvb3RiYWxsLWZhbi1zaG91bGQtdmlzaXQv/ ГЁ fondamentale per ogni viaggiatore. Protegge te stesso da imprevisti. Problemi possono capitare, e avere una polizza necessaria ti assicura tranquillitГ . Inoltre, considera benefit aggiuntivi.
гг..неплохо
zahranicni online casino, http://149.049.myftpupload.com/slovenske-kasina-svet-zabavy-a-astia/ ponГєkajГє rozsiahlu ЕЎkГЎlu hier a moЕѕnostГ na zisk. Online stГЎvky zГskava stГЎle vyЕЎЕЎiu popularitu medzi hrГЎДЌmi po celom svete.
Интерфейс понятный и не перегружен лишними элементами https://kgzxkf.com/4aa5683c0fb332c99a90238baa0e4a0d/
1win express stavka 1win express stavka
1win насб аз манбаъҳои номаълум 1win59278.help
1win promo code 2026 1win promo code 2026
Descubre la magia y tecnologia en el companias de espectaculos de drones, donde cada vuelo ilumina el cielo con un despliegue impresionante.
Los espectaculos de drones estan revolucionando la forma en que experimentamos los eventos al aire libre.
сабти ном дар 1win сабти ном дар 1win
1win mobile http://www.1win59278.help
1win Payme orqali to‘lash http://1win5769.help/
Discover the thrill of the aviator game at [url=https://online-aviatorgame.com/]inverter game[/url], where precision and luck collide in the sky.
As the multiplier climbs, players must decide when to cash out and secure winnings.
mostbet скачать через зеркало mostbet84736.help
Преимущество готовых проектов домов в значительной экономии времени и средств.
проект дома 2 этажа https://gotovye-proekty-domov12.ru/2-etaga/
Discover the thrill of flying high with the exciting game aviator today!
Because of house advantage and high volatility, careful timing and strategy are crucial for steady results.
мостбет забыли пароль http://mostbet84736.help/
1win фриспины http://1win48762.help/
Слышал недавно что так можно
SГІng bбєЎc 1xbet, https://forum.unipark.com/topic/starting-budget-for-casino-ads-my-experience/#post-9529 lГ mб»™t nЖЎi hấp dбє«n cho nhб»Їng ngЖ°б»ќi cГЎ cЖ°б»Јc. TбєЎi Д‘Гўy, tГ¬m thấy trбєЈi nghiệm Д‘б»™c Д‘ГЎo vб»›i Д‘бє§y đủ trГІ chЖЎi. Hệ thб»‘ng cЖ°б»Јc tбєЎi SГІng bбєЎc 1xbet thЖ°б»ќng cбєp nhбєt Д‘б»ѓ hГ i lГІng nhu cбє§u cГЎc game thủ.
ORBIS Production https://orbispro.it/ is a recognized full-spectrum film, photo, and video production agency situated in Milan, serving all of Italy through offices in Milan, Rome, and Venice. The company provides complete production support for international brands and agencies, including locations, permits, crewing, casting, equipment, logistics, and post-production. Starting from creative conception to finished product, ORBIS Production produces top-tier commercial, corporate, and branded media all over Italy.
мостбет скачать приложение с сайта http://mostbet84736.help
Outline VPN предлагает защищенный доступ в интернет без слежки и ограничений по минимальной цене на рынке. Сервис не собирает логи, не отслеживает действия пользователей и обеспечивает полную анонимность в сети. Гигабитный канал с современным шифрованием гарантирует высокую скорость соединения для стриминга, игр и работы. Купить ключ Outline на https://outline.monster/ можно за пару кликов — активация занимает минуту, а использовать VPN разрешается на неограниченном количестве устройств: смартфонах, компьютерах, планшетах под любой операционной системой.
Компания предлагает профессиональное оборудование для комфортного использования питьевой воды. В каталоге представлены современные кулеры различных моделей и конфигураций для дома и офиса. На сайте https://voda-s-gor.ru/oborudovanie/ можно выбрать устройства с функциями нагрева и охлаждения воды, которые обеспечат постоянный доступ к качественному напитку. Доставка осуществляется по Махачкале и Каспийску в удобное время.
Discover the excitement of online gaming with exbet, your ultimate destination for thrilling bets and big wins.
Bettors must be aware that ex bets carry more risk due to their conditional nature.
1win официальный сайт скачать 1win официальный сайт скачать
1win адрес офиса http://www.1win48762.help
1win линк расмӣ 1win линк расмӣ
Visit https://friendlylikes.com/ and you can buy Instagram followers, likes, views, and comments at the best prices, with a quick start. We also offer services for other social networks. Our support is fast and available 24/7. Our service ensures the highest quality and reliability.
1win дар 1win қайд шудан 1win дар 1win қайд шудан
Good post. I learn something new and challenging on blogs I stumbleupon on a daily basis. It will always be exciting to read through articles from other writers and practice something from their sites.
Автор предлагает анализ разных подходов к решению проблемы и их возможных последствий.
Автор предлагает читателю возможность самостоятельно сформировать мнение, представив различные аргументы.
1win кушода намешавад http://1win93047.help
CryptoRanked — это рейтинг криптовалютных бирж с упором на практичную и проверенную информацию для выбора торговой площадки. Проект https://cryptoranked.ru/ собирает и анализирует данные по ключевым параметрам: уровню безопасности, комиссиям, ликвидности, набору торговых инструментов и качеству поддержки, помогая принять взвешенное решение при работе с криптобиржами.
1win вывод на элсом сколько идет https://1win08754.help/
Автосервис LemonCar в Анапе предлагает полный спектр услуг для вашего автомобиля — от диагностики до кузовного ремонта. Современное оборудование позволяет выявлять неисправности любой сложности, а опытные мастера устраняют их с гарантией качества. Перед началом работ проводится бесплатный осмотр, все процедуры согласовываются с владельцем, никаких скрытых платежей. Записаться на обслуживание можно на сайте https://lemon-car.ru/ где представлен полный перечень услуг: слесарный и электрический ремонт, 3D развал-схождение, техобслуживание двигателя и КПП. Сервис работает по адресу улица Чехова, 64, звонок по России бесплатный.
Я оцениваю широту покрытия темы в статье.
1win пополнение Optima Bank https://1win04381.help/
I think this is among the most significant information for me. And i’m glad reading your article. However should observation on some common issues, The site taste is perfect, the articles is really nice : D. Good job, cheers
obviously like your web-site however you have to take a look at the spelling on quite a few of your posts. Several of them are rife with spelling problems and I in finding it very bothersome to tell the reality on the other hand I will surely come back again.
Я бы хотел отметить актуальность и релевантность этой статьи. Автор предоставил нам свежую и интересную информацию, которая помогает понять современные тенденции и развитие в данной области. Большое спасибо за такой информативный материал!
1win зеркало не работает http://www.1win08754.help
1win лимит на элсом https://1win04381.help/
1win элсом Киргизия 1win08754.help
Я восхищен этой статьей! Она не только предоставляет информацию, но и вызывает у меня эмоциональный отклик. Автор умело передал свою страсть и вдохновение, что делает эту статью поистине превосходной.
Я восхищен тем, как автор умело объясняет сложные концепции. Он сумел сделать информацию доступной и интересной для широкой аудитории. Это действительно заслуживает похвалы!
1win играть без регистрации 1win играть без регистрации
Московская межрегиональная судебно-экспертная служба осуществляет независимую судебную и внесудебную экспертизу в сфере строительства, экономики, здравоохранения и иных областях: технические обследования зданий и объектов, анализ проектных и сметных материалов, бухгалтерские и финансовые экспертизы, медицинские заключения и оценку активов. Ищете экономические объекты экспертизы? Подробная информация на mses-expert.ru Специалисты компании прошли сертификацию в Университете МВД России, включены в реестр Палаты судебных экспертов и имеют полный пакет лицензий и аккредитаций для осуществления экспертных работ любой категории сложности с четким выполнением сроков и законодательных требований.
Автор старается быть балансированным, предоставляя достаточно контекста и фактов для полного понимания читателями.
Статья предлагает обширный обзор темы, представляя разные точки зрения и аргументы.
mostbet comisioane depunere mostbet comisioane depunere
1win рулетка https://1win79230.help/
быстрый Водка казино приложение https://svcomputer.in/pick-bonusy-pochemu-vybor-ne-menyaet-matematiku-no-menyaet-vovlechennost/
I used to be able to find good info from your blog articles.
mostbet login mostbet login
1win не устанавливается apk http://1win79230.help/
1вин приветственный бонус http://www.1win79230.help
Looking for an interesting and useful portal about the dollar, euro, pound sterling, and other currencies? Or information about gold, silver, oil, and gas? Or perhaps everything about stock markets, industry, and the global economy? Visit https://www.profi-forex.us/ – it’s a comprehensive source of professional information that will be of interest to both amateurs and professionals.
cum retrag de pe mostbet pe card cum retrag de pe mostbet pe card
Если вам необходима авто с водителем новосибирск, то наши предложения по аренде авто с водителем в Новосибирске идеально подойдут для комфортных поездок.
Аренда авто с водителем в Новосибирске — это удобное решение для тех, кто ценит комфорт и безопасность.
Такая услуга пользуется популярностью среди бизнесменов и туристов, которые хотят сэкономить время.
Перед бронированием стоит уточнить наличие дипломов и лицензий у водителя, а также условия страхования.
Выбор компании для аренды авто с водителем в Новосибирске зависит от бюджета и личных предпочтений клиента.
В большинстве случаев услуга включают комфортное транспортное средство, опытного водителя и возможность выбрать маршрут.
Для бронирования автомобиля с водителем достаточно связаться по телефону или через онлайн-форму на сайте.
Такая услуга становится всё популярнее среди жителей города и гостей региона, благодаря своим множественным преимуществам.
1вин вывод средств http://www.1win70163.help
На странице http://hackerlive.biz/threads/uslugi-xakera-udalennyj-dostup-vzlom-soc-setej-votsap-telegram-i-mnogoe-drugoe-bolshoj-opyt.78/page-9 собраны предложения частного специалиста по кибербезопасности: аудит защиты, поиск уязвимостей, чистка устройств от вредоносного ПО, настройка 2FA и восстановление доступа к своим аккаунтам. Формат без «воды»: обозначены задачи, заявлена конфиденциальность, контакт напрямую и ориентация на итог.
Я рад, что наткнулся на эту статью. Она содержит уникальные идеи и интересные точки зрения, которые позволяют глубже понять рассматриваемую тему. Очень познавательно и вдохновляюще!
1win скачать apk Киргизия 1win скачать apk Киргизия
Discover the thrill of online gaming at 777 bet, where exciting bets and big wins await you!
Long-time users earn rewards through loyalty programs for continued engagement.
Если вам нужна аренда автомобиля с водителем новосибирск, обращайтесь к профессионалам!
В заключение стоит отметить, что аренда машины с водителем в Новосибирске гарантирует комфорт и безопасность.
I’ve learned some new things by your site. One other thing I would like to say is the fact newer personal computer operating systems are inclined to allow much more memory to be played with, but they additionally demand more storage simply to run. If a person’s computer is not able to handle extra memory and also the newest computer software requires that memory increase, it could be the time to shop for a new Laptop. Thanks
Сервис Outline VPN предлагает защищенный доступ в интернет без слежки за трафиком и ограничений скорости по доступной цене. Ключи активируются за минуту и работают на всех платформах — Windows, macOS, Android, iOS, Linux — без привязки к количеству устройств. Гигабитный канал с облегченным шифрованием обеспечивает высокую пропускную способность для стриминга, онлайн-игр и загрузки файлов. Приобрести ключ Outline VPN можно на https://outline-vpn.tech/ всего за 390 рублей в месяц с мгновенной активацией после оплаты. Сервис не логгирует данные пользователей и гарантирует полную анонимность в сети.
1win проблема с входом ios 1win70163.help
выездной шиномонтаж 24 часа москва
pin-up_az mirror http://www.pinup21680.help
шумоизоляция арок авто https://shumoizolyaciya-arok-avto-77.ru
mostbet правила вывода mostbet правила вывода
888starz Egypt توفر فرصاً عظيمة للمستخدمين للفوز والمراهنة على مختلف الأحداث
تحميل 888starz https://888starz.onl/eg/apk/
888starz مصر تتميز بسهولة استخدام موقعها الإلكتروني وتطبيقاتها
Предприятие «Экспресс-связь» ведет деятельность в Екатеринбурге начиная с 2012 года. Компания занимается установкой видеонаблюдения, ОПС, домофонных систем и компьютерных сетей. Ищете купить бытовоку Екатеринбург? Детальная информация о выполненных проектах и услугах представлена на портале express-svyaz.ru в разделе портфолио. Фирма изготавливает бытовки, модульные объекты, фасонные элементы и кассеты с порошковой обработкой.
pin-up hesabım açılmır http://www.pinup21680.help
Experience thrilling wins and endless entertainment at 777 bet Casino, your ultimate destination for online gaming.
The quality of support enhances the enjoyment and reliability of the platform.
Discover the excitement and top bonuses at ExBet Casino, your ultimate destination for online gaming.
Fairness is maintained on the platform through clear algorithms and systematic auditing practices.
mostbet официальный https://mostbet20394.help
mostbet краш игры https://mostbet20394.help/
pin-up bonus necə götürülür pin-up bonus necə götürülür
Если вы мечтаете о надежном и уютном жилье, обратите внимание на каркасные дома спб под ключ, который сочетает в себе качество, современный дизайн и доступную стоимость.
Этот способ строения выделяется своей оперативностью и выгодой.
Если вы хотите купить летнюю резину, то у нас вы найдете лучшие предложения и выгодные цены.
Это позволяет сэкономить время и обеспечить правильный уход за новыми шинами.
Les visuels éblouissants et la jouabilité électrisante de la machine à sous Gates of Olympus peuvent être captivants, mais n’oubliez pas que même les héros les plus courageux ont besoin d’un plan de bataille ! Bien que la recherche de gains épiques fasse partie du plaisir, un jeu responsable est essentiel pour un plaisir vraiment mémorable. Voici quelques conseils simples pour vous aider à naviguer dans le monde palpitant de Gates of Olympus 1000 et à minimiser les pertes potentielles, afin que vous puissiez continuer à faire tourner les rouleaux (et, espérons-le, à accumuler les gains) plus longtemps. Cherchez l’article souhaité dans nos différents univers Les applications téléchargeables fonctionnent très bien sur leurs appareils respectifs, qui offrent tous deux aux joueurs une grande variété de choix de jeux. Alors que beaucoup de gens ne le considèrent pas important, ainsi que les questions financières express et dédiées et les attentes nécessaires.
https://www.cnss.cg/2026/02/03/ma-chancefr-com-votre-portail-vers-les-meilleurs-jeux-de-casino/
Pour tester une stratégie dans la version démo du slot Gates of Olympus, le joueur doit définir plusieurs paramètres clés. Il est crucial de choisir une tactique qui correspond au style de jeu individuel, au niveau de risque et aux objectifs du joueur. Par exemple, si un joueur préfère une approche prudente, une stratégie avec de petites mises et un jeu prolongé peut lui convenir. Pour les amateurs de risque, une tactique avec des mises élevées visant de gros gains serait appropriée. Cette vidéo met en avant un gain remarquable remporté par un joueur lors des tours gratuits sur Gates of Olympus 1000 : Oui, il est fortement recommandé de consulter un professionnel de santé spécialisé dans les addictions. Un thérapeute pourra vous aider à comprendre les causes de votre addiction, à développer des stratégies pour y faire face et à mettre en place un plan de traitement personnalisé.
Сеть отелей на час Де Арт https://deart-13.ru/ это гостиница с почасовой оплатой в Москве. У нас семь великолепных бутик-отелей Де Арт. Они рассчитаны на небольшое количество гостей, которым предлагаются номера с уникальными, продуманными до мелочей интерьерами. Узнайте больше о наших номерах и ценах на сайте.
Experience the thrill of online gaming at 777bet casino, where excitement and big wins await you.
The sportsbook’s design is simple to use, catering to users of all skill levels.
—
Strong encryption safeguards user information, ensuring privacy and security on the platform.
Discover endless fun and excitement at good day 4 play, your ultimate destination for entertainment.
The app includes various games designed to stimulate creativity and problem-solving skills.
Ищете кейсы кс? Загляните на cs2case.win и вы откроете для себя уникальные коллекции! Кейсы кс 2 у нас на всевозможную тематику – от бесплатных или дешевых до эксклюзивных, не представленных в других местах, а вывод скинов себе в Steam осуществляется моментально. Новые кейсы представляем часто! Открывай лучшие кейсы на наиболее честном сайте! Наша коллекция придется по душе всем!
Discover the excitement of online gaming with ex bet, your ultimate destination for thrilling bets and big wins.
Ex bets can offer bettors the chance to win larger sums compared to ordinary bets.
Ищете тур на алтай цены? Перейдите на altai.travel/tourism/tours и вы откроете для себя все существующие экскурсионные туры для каждого времени года и бюджета, и разные виды маршрутов: конные, пешие, авто туры. С каждым туром можно детально познакомиться и узнать сроки его организации. Все типы туров и маршруты представлены только у нас – на официальном туристическом портале Республики Алтай. Мы предлагаем удобный поиск по карте путешествий.
Я нашел эту статью чрезвычайно познавательной и вдохновляющей. Автор обладает уникальной способностью объединять различные идеи и концепции, что делает его работу по-настоящему ценной и полезной.
Статья предлагает различные точки зрения на проблему без попытки навязать свое мнение.
Автор статьи предоставляет подробные факты и данные, не выражая собственного мнения.
Stay up to date with the latest Stakelogic updates and highlights Coolbet will also integrate a selection of Stakelogic Live’s best live table games. As a result, players will get to experience engaging live dealer experiences across games such as blackjack, roulette and game show-styled games. Some of the best games include Super Stake Roulette 5000x, Live Atom Roulette, and Auto Roulette Sports. Strap in for explosive wins and unique bonuses in Stakelogic’s colourful and creative new slot, Cherry Bomber Fans of variety will love what this version adds to the classic wheel. Roulette Royal American by Urgent Games introduces “Neighbors” and “Finals” options, giving you more ways to place bets and experiment with different strategies. This free American Roulette game keeps the familiar loop while layering in extra excitement for every spin.
https://king12.com/uncovering-oshi-an-exciting-casino-game-for-australian-players/
His father, SD Shukla, a retired government employee, recalls his son’s early years. “He was never like the other kids—always focused, quiet, and deeply thoughtful. We didn’t even know when he applied for NDA. One day he came and told us he had cleared everything—written, SSB, medical. That’s how he has always been: silently determined.” Aviator game presents a blend of simplicity and exhilaration by providing you with the opportunity to multiply your bets by, up to 100 times or even more! Through its interactive gameplay featuring a provably fair algorithm and real time multiplayer engagement; Aviator delivers an immersive gaming experience that keeps you hooked. All this and even more you will find on aviator pakistan game. His father, SD Shukla, a retired government employee, recalls his son’s early years. “He was never like the other kids—always focused, quiet, and deeply thoughtful. We didn’t even know when he applied for NDA. One day he came and told us he had cleared everything—written, SSB, medical. That’s how he has always been: silently determined.”
Ищете передовой VPN, который обеспечивает стабильное соединение и высокую скорость? Посетите сайт https://v2raytun.fun/ – там вы найдете v2RayTun VPN ключи, которые подходят для любых устройств – iPhone, Android, Windows или macOS. У вас будет доступ к свободному интернету всегда под рукой. Подробнее на сайте.
Play the best games and claim amazing bonuses on evo888 now!
After registration, users can deposit funds, take advantage of bonuses, and begin gaming right away.
Your posts always strike the perfect balance between motivation and practicality. I’d love to see you dive deeper into how these ideas might influence future innovations, such as robotics or sustainable tech. Your ability to simplify complexity is unmatched. Thanks for consistently sharing such thoughtful content. can’t wait for your next post!
Digital Space: https://gpt4geeks.com/advertise-with-us/
гпт чат
Для обеспечения максимальной безопасности на дороге рекомендуем приобрести купить камеру заднего вида для грузового автомобиля.
К подбору камеры заднего вида для грузового автомобиля нужно подходить внимательно.
Если вы хотите повысить безопасность и удобство маневрирования, рекомендуем купить камеру заднего вида на грузовик.
Выбор подходящей камеры значительно повышает комфорт и безопасность при эксплуатации грузовика.
General Terms | Privacy Policy | Cookie Policy | Privacy Preferences | Responsible Gaming Licensed and regulated in Great Britain by the Gambling Commission under account number 57924 for GB customers playing on our online sites. For customers outside of Great Britain, we licensed by the Government of Gibraltar and regulated by the Gibraltar Gambling Commission under licence numbers RGL 133 and RGL 134. Having conducted this review of Gates of Olympus Super Scatter, we compared the experience to previous games in the series to see how it stood out. You can see it’s come a long way since the original slot, which offered a max win of 5,000x. Step into the realm of gods, as the reels rumble and multipliers crash like thunder! Super Scatters can stir up the storm, triggering Free Spins and maybe even something Zeus-level epic.
https://svoivorota.com.ua/spin-fever-casino-live-roulette-for-australian-gamblers/
0 Children The free spins bonus round can also be triggered with a bonus buy in the base game for 100x the player’s bet. Slots in various casinos gates of olympus this game is starting to show its age, you will be able to see reels and 15 pay lines on the screen. Big Kahuna Snakes Ladders has a 90.71% payout percentage, and he was once a god. Unlock the Power of Gates of Olympus 1000’s Free Spins Feature: Tips and Tricks Moreover, see the Roulette Rules page. The role of the scatter went to the sailboat, as players have the option of playing with a real dealer. However, there are a number of other advantages that can convince you. But on the other hand, but they did grant a great bonus when they did land. The top prize in Gates of Olympus is x5,000, which is a common figure for Pragmatic Play slots. Theoretically, there’s a chance to hit the win limit during the base game. Because tumbles can go on for eternity and multipliers are there to boost the potential. But it’s always more likely to win big during free spins. That’s because of the addition of the Total Multiplier that grows and doesn’t reset between rounds.
Автосервис LemonCar в Анапе предлагает полный спектр услуг для вашего автомобиля — от диагностики до кузовного ремонта. Современное оборудование позволяет выявлять неисправности любой сложности, а опытные мастера устраняют их с гарантией качества. Перед началом работ проводится бесплатный осмотр, все процедуры согласовываются с владельцем, никаких скрытых платежей. Записаться на обслуживание можно на сайте https://lemon-car.ru/ где представлен полный перечень услуг: слесарный и электрический ремонт, 3D развал-схождение, техобслуживание двигателя и КПП. Сервис работает по адресу улица Чехова, 64, звонок по России бесплатный.
Если вы страдаете от потливости подмышек, важно понять, что это состояние, известное как гипергидроз, часто можно эффективно контролировать и лечить с помощью специальных средств и методов.
является одним из самых распространенных и неприятных симптомов, с которыми сталкиваются многие люди . Эта проблема может быть результатом сочетания различных факторов, включая наследственность, образ жизни и окружающую среду . Потливость подмышек может иметь значительное влияние на качество жизни, вызывая психологический дискомфорт и влияя на социальные взаимодействия.
Потливость подмышек может быть более заметной в моменты эмоционального напряжения или в ситуации, когда человек испытывает физическую нагрузку. В таких случаях полезно иметь в арсенале эффективные способы борьбы с этой проблемой, чтобы чувствовать себя уверенно и комфортно. Решение проблемы потливости подмышек требует комплексного подхода, который включает в себя изменение образа жизни, применение специальных средств по уходу за кожей и, в некоторых случаях, медицинское вмешательство .
## Раздел 2: Причины потливости подмышек
Причины потливости подмышек могут быть связаны с различными внутренними и внешними факторами, включая генетическую предрасположенность, общее состояние здоровья и условия окружающей среды. Основными причинами потливости подмышек являются генетическая предрасположенность, избыточный вес, стресс и определенные заболевания . Потливость подмышек может быть усугублена потреблением определенных продуктов и напитков, таких как кофе, чай и острая пища .
Потливость подмышек может иметь временный или постоянный характер, в зависимости от факторов, ее вызывающих, и индивидуальной реакции организма. Решение проблемы потливости подмышек включает в себя выявление и устранение основной причины и использование различных средств и методов для контроля потливости.
## Раздел 3: Методы борьбы с потливостью подмышек
Борьба с потливостью подмышек предполагает использование различных стратегий, начиная от изменений в ежедневном уходе и заканчивая применением медицинских препаратов . Одним из эффективных методов является применение средств по уходу за кожей, таких как антиперспиранты и дезодоранты, для контроля потливости и предотвращения запаха .
Потливость подмышек может быть контролируема с помощью изменений в питании и образе жизни, таких как здоровая диета и регулярная физическая активность. Кроме того, существуют различные медицинские процедуры и препараты, которые могут быть использованы для лечения гипергидроза, если он сильно влияет на качество жизни .
## Раздел 4: Прогноз и перспективы лечения потливости подмышек
Прогноз лечения потливости подмышек зависит от причины ее возникновения и эффективности применяемых методов лечения . В большинстве случаев могут быть достигнуты положительные результаты с помощью сочетания изменений в образе жизни, применения специальных средств и, при необходимости, медицинского вмешательства.
Потливость подмышек может быть эффективно контролируема и лечена с помощью различных методов и средств, что может улучшить самочувствие и социальное взаимодействие . Важно решать эту проблему с помощью комплексного подхода, включающего изменение образа жизни, применение специальных средств и, при необходимости, консультации со специалистами.
Ищете банкротство физ. лиц в Самаре? Посетите Центр банкротства https://fizbankrot-smr.ru/ – это возможность законно списать долги. Узнайте на сайте стоимость всего комплекса юр. услуг, входящих в цену. При необходимости рассчитайте цену услуги онлайн. Даем гарантию по договору, предлагаем сжатые сроки процедуры и списание долгов под ключ. Профессиональный опыт более 10 лет. Подробнее на сайте.
fc777 slot offers the best slot machines and generous bonuses for all players.
Here, we will offer an in-depth examination of fc777.
Центр «Талисман» в Хабаровске специализируется на лечении алкогольной зависимости с 2009 года. Врачи-наркологи и психиатры проводят выведение из запоя на дому и в клинике, медикаментозное кодирование, детоксикацию с индивидуальным подбором программы. Ищете капельницу на дом от алкоголя хабаровск? Подробнее об услугах и ценах на talisman-khv.ru — здесь можно записаться на консультацию или вызвать специалиста. Помощь оказывается анонимно, у врачей есть все необходимые документы, центр работает без выходных.
Only wanna say that this is very useful, Thanks for taking your time to write this.
Для комфортного проживания забронировать отель в сочив агрегаторе official-hotels.ru
забронировать отель санкт
These slots appeal to players who are willing to withstand dry spells for the chance at significant rewards. There are cluster pay slots, such as Aloha! Cluster Pays, which cater to low-risk players also. These low variance online slots are less common but great for players with smaller bankrolls. hey@casumo The Cluster Pays feature is a new game mechanic that has been recently added to popular online slot games such as Aloha! by Netent. This feature will reward you with the opportunity to win up to 25 times your bet if you get seven or more of the same symbols in a row or a reel. The Cluster Pays Feature can be found on many different slots, so don’t hesitate and check out all our great casino sites now! Search for your favourite game in the search box at the top or use the menu to take a look at the various options. You’ll find new and featured games, slots, live games, jackpot games and casual games. National-Lottery Casino gives you the option to play for free before you place a stake, and each game comes with a handy information guide so you can learn more about how to play.
https://www.michaelsavetskymd.com/156/melbet-casino-bonus-a-review-for-uk-players/
When hooking up Dazzle Myself, first of all moves your is the fact that reels do not most wind up as whatever they usually manage. Reels step 1 and you will 2 features around three rows, reels step three and you will 4 provides four rows, and you may reel #5 features a full five rows. Similar graphics have been seen prior to inside the slots for example Reel Hurry, but it’s nevertheless a good departure on the simple template most harbors start with. In addition to the novel setup of your own reels, there are some almost every other really enticing great features that come with Amazing Wild Reels, Linked Reels and you may Totally free Revolves. Have a return to help you user from 96.4%, a portion we could yes live with, even though there are many online slots you to definitely fork out a lot more than simply you to. The new difference try lower to help you average, making it the greatest slot to play when trying to locate due to those people annoying bonus playthrough conditions. NetEnt position games are recognized for their greater diapason from available wager thinking. Offered by mere $0.ten for each spin, so it energizing term will likely be starred for $2 hundred a go.
From the very first page, the tension is ratcheted up to eleven. The threat of the venin is terrifyingly real, and the cost of magic is high. Accessing the Onyx Storm epub gives you a front-row seat to the destruction. The character dynamics are shifted, creating new conflicts and resolutions. It is a deeply satisfying read for long-time fans. The electronic edition is compatible with all major e-readers, making it easy to get started.
Для эффективной тренировки мышц ног рекомендуем обратить внимание на рычажный тренажер для ног, который обеспечивает максимальную нагрузку и удобство в использовании.
Он позволяет создавать оптимальные нагрузки на мышцы ног.
Если вы хотите улучшить свою тренировку, обратите внимание на грузоблочные тренажеры это — это идеальное решение для создания эффективной и разнообразной программы тренировок.
Так тренажеры прослужат дольше и обеспечат комфортные тренировки.
Если вы ищете надежное и эффективное оборудование для занятий спортом, обратите внимание на купить блок тренажер на сайте SportRes — здесь вы найдете все необходимое для эффективных тренировок.
Плавность вращения достигается благодаря качественным подшипникам, в то время как усиленные блоки отлично справляются с большими нагрузками.
The book is a journey of trust. Learning to trust another person with your heart is the hardest thing Dante and Vivian do. But the reward is immense. A King of Wrath PDF search leads to this rewarding conclusion. It is a testament to the bravery required to love.
Youre so cool! I dont suppose Ive read anything like this before. So nice to seek out any individual with some authentic ideas on this subject. realy thank you for starting this up. this web site is something that is needed on the net, somebody with somewhat originality. useful job for bringing one thing new to the web!
Автор старается представить информацию нейтрально и всеобъемлюще.
Если хотите качественно и быстро вернуть блеск вашему автомобилю, обращайтесь в детейлинг цена, где профессионалы обеспечат вашему авто безупречный вид.
В завершение специалисты применяют защитные составы и проводят глубокую уборку внутри автомобиля.
Следующим шагом становится полировка, возвращающая автомобилю блеск и устраняющая дефекты.
Discover the rejuvenating effects of korean lip fillers for effective mesotherapy injections that enhance your skin’s vitality and glow.
Ultimately, mesotherapy injections provide a versatile option for skin improvement and body shaping.
Для надежной защиты воды от загрязнений идеально подойдет купол для бассейна 6м.
Самым доступным по цене вариантом считаются пленочные тенты, которые защищают поверхность воды.
Рабочее зеркало казино Водка служит альтернативным доступом к сайту при блокировках.
При использовании зеркал пользователи получают доступ ко всем основным разделам и бонусам.
Автор предлагает обоснованные и логические выводы на основе представленных фактов и данных.
??? 888starz casino ?????? ?? ???? ??????????? ??? ???????? ? ??? ????? ??????? ??????? ??? ???????? ????????? ?????????? ??? ?? ????. ????? ??????? ?? ??????? ??????? ???????? ? ??? ?? ??? ??????? ???????? ?????? ???? ?????? ??????. ?????? ?????? ?? 888starz casino ????? ?????? ????????? ? ??? ???? ???????? ??????? ?? ???????? ??????? ?????? ????? ???????? ???????.
?????? 888starz casino ?? ??????????? ???????? ???secure ? ??? ????? ????? ????? ?????? ???? ??? ??? ???? ??????. ???? ???????? ??????? ????? ??????? ??? ?????? ?? ?????? ?????????? ? ??? ??? ????? ???? ??????????? ???????? ????? ???????. ?????? experience ????? ?? 888starz casino ???? ??????? ??????? ???????? ? ??? ???? ???????? ????? ????? ???????? ??????? ???????? ?? ???????? ???????.
تحميل 888starz اخر إصدار https://888starzegypt2026.com/apk/
New au pokies best to become an A-lister, the industry also provides support for those who may be experiencing gambling-related harm. For players who enjoy their casino games on the go, no registration pokies casino euro but the bonus trigger frequency is all over the place. For one, on the other hand. Book of Dead – This Play’n GO slot is inspired by ancient Egypt and features free spins, can be processed almost instantly. 15 dragon pearls casino it contains detailed responses to all common questions and should be sufficient for most queries, the player wins the game. Once your account is activated, which was used for replenishments in order to avoid problems and get money as soon as possible. First, Australia has one of the highest rates of gambling in the world. The 20 free spins put Ancient Forest online slot just ahead of popular Novomatic games like Lucky Lady’s Charm Deluxe in the opinion of our review team, with pokies being one of the most popular forms of gambling.
https://ssbuilderdeveloper.com/how-to-win-aviator-game-tips-for-namibian-bettors-2/
You can match for the Arena of Solare Practice Match, even outside an ongoing ranked season, by going to the main menu (hotkey: Esc) → War (F7) → Arena of Solare → .Arena of Solare practice match hours: In practice mode, a team composed of three of the same class is possible. Transitioning from 15 Dragon Pearls free play to real money mode is seamless. Choose reputable casinos offering the game, like those listed on PlayFame or BNG Games. In real money mode, set your bet, spin, and aim for pearl collections to unlock the Hold and Win feature. Betting moderately can sustain sessions, increasing chances for the 15 Dragon Pearls grand. An ambitious project whose goal is to celebrate the greatest and the most responsible companies in iGaming and give them the recognition they deserve. “Libraries aim to address and resource disadvantage, however it is schools where there is already considerable advantage who will have the capacity to continue to employ qualified teacher librarians and invest in library services for the long term,” she said.
В Москве существует множество автосервисов, специализирующихся на Тойота. Специалисты готовы осуществлять ремонт и обслуживание ваших автомобилей.
Если вам нужен качественный и надежный автосервис Тойота в Москве, мы предлагаем широкий спектр услуг для вашего автомобиля.
Ремонт и обслуживание Тойота требуют от специалистов глубоких знаний. Все работники имеют соответствующую квалификацию и опыт.
В нашем сервисе используются современные технологии и оборудование. Наличие современного оборудования существенно упрощает процесс диагностики.
Обращаясь в автосервис Тойота, вы можете рассчитывать на высокое качество услуг. Мы ценим каждого клиента и стремимся к его удовлетворенности.
Big Bass Bonanza Hold & Spinner is available on tablet, mobile, or desktop devices and has bet levels of 10 p c to $ €250 per spin. When betting regularly in this mode, the game has a default RTP of 96.07%, rising to 96.09% when activating the Ante Bet. The Ante Bet increases the stake by 50% for an extra chance of Scatter symbols. The other way of possibly playing Big Bass Bonanza Hold & Spinner is buying free spins or the Hold & Spinner. In both cases, the RTP is 96.07%, keeping in mind lower return models are available, though all info is displayed on the paytable. What sets bigger bass bonanza apart from other slot games are its unique features that elevate the fishing adventure: We perform checks on reviews We’ve played over 24.9M rounds in Bigger Bass Bonanza to provide the stats. This, perhaps, isn’t enough to paint the full picture, but it gives at least some idea of the slot’s performance.
https://www.bsb-schuler.de/all-slots-casino-review-exciting-slot-adventures-for-new-zealand-players/
4K at 60 frames per second brings unparalleled clarity and smoothness video export feature ensures stunning video clarity and detail to meet the modern content standards. Compared to competitors, it offers smoother resolution for professional-grade results. It enhances visuals while maintaining compatibility with advanced devices which is ideal for creators on platforms like YouTube or streaming. More Info As the popularity of video-sharing platforms skyrockets, so too does the need for advanced video-editing apps that can aid you in producing top-notch output that will leverage their traction and visibility on social media. 4k Video Editor competitively joins the market with a wide range of features that promise to fulfill all your video editing needs, no matter how complex they might be.
Автор старается оставаться нейтральным, что помогает читателям получить полную картину и рассмотреть разные аспекты темы.
Old Major’s skull becomes a relic that the animals must march past. This mirrors the treatment of Lenin’s body. It is a perversion of the original revolutionary intent. The shift from reverence to ritual is subtle. Access the story via an Animal Farm PDF to study this symbolism. It demonstrates how dead icons are used to control the living.
Если вы ищете качественный детейлинг центр, обратитесь к нашим профессионалам.
В итоге машина приобретает обновлённый и ухоженный вид.
Одним из ключевых процессов является полировка кузова, при которой удаляются мелкие царапины и микротрещины.
Если вы ищете детейлинг салона авто, наш сервис предлагает профессиональный уход и восстановление вашего автомобиля на высшем уровне.
Затем кузов подвергается полировке для удаления незначительных повреждений и придания блеска.
Thanks , I’ve recently been searching for information about this subject for ages and yours is the best I’ve discovered till now. But, what about the bottom line? Are you sure about the source?
Информационная статья представляет различные аргументы и контекст в отношении обсуждаемой темы.
Мне понравился нейтральный подход автора, который не придерживается одного мнения.
Статья представляет широкий обзор темы, учитывая различные аспекты проблемы.
Thanks for another informative web site. Where else may I am getting that kind of info written in such an ideal means? I have a project that I am just now operating on, and I have been at the look out for such information.
Если вы ищете детейлинг центр, наш сервис предлагает профессиональный уход и восстановление вашего автомобиля на высшем уровне.
Используются специальные шампуни и пенки, которые не повреждают лакокрасочное покрытие.
Если вы ищете качественный детейлинг полировка кузова, обратитесь к нашим профессионалам.
Процесс избавления от грязи основывается на использовании современных моющих средств и оборудования.
Основная задача таких центров – повысить внешний вид и продлить срок службы транспортного средства.
Автор статьи предоставляет информацию в понятной форме, избегая субъективных оценок.
Я нашел эту статью чрезвычайно познавательной и вдохновляющей. Автор обладает уникальной способностью объединять различные идеи и концепции, что делает его работу по-настоящему ценной и полезной.
Very nice post. I just stumbled upon your weblog and wanted to say that I’ve truly enjoyed browsing your blog posts. After all I will be subscribing to your feed and I hope you write again very soon!
Когда сталкиваешься с утратой близкого человека, важно найти надежную ритуальные услуги минск цена, которая поможет организовать достойное прощание.
Он требует внимательного подхода и внимания ко многим деталям. В Минске существует множество компаний, предлагающих ритуальные услуги, однако найти достойного подрядчика – может оказаться сложной задачей.
Следует учитывать, что стоимость ритуальных услуг зависит от многих факторов. Влияют на ценообразование выбранные ритуальные принадлежности, транспортные расходы и прочие факторы. Исходя из этого, целесообразно заранее уточнить все детали и ознакомиться с полным прайс-листом.
Выбор ритуального агентства: на что обратить внимание
При выборе агентства важно обратить внимание на репутацию компании. Ознакомьтесь с мнениями людей, поговорите с представителями, чтобы составить собственное впечатление. Подтверждение квалификации и соответствия стандартам также играет существенную роль.
Проверьте, что агентство предоставляет полный спектр услуг, в том числе подготовку необходимых бумаг. Автомобили в собственности и ритуального зала для прощания – несомненные плюсы.
Оформление документов и организация церемонии
Оформление необходимых документов – неотъемлемая часть организации похорон. Бюро ритуальных услуг. Это значительно облегчит.
Проведение траурного мероприятия – важный этап, помогающий попрощаться с близким человеком. Выбор места проведения и близких и родных.
Дополнительные услуги и поддержка
Кроме стандартного набора ритуальные агентства могут предложить дополнительные услуги, в частности, проведение поминальной трапезы. Помощь в переживании горя также может оказаться необходимой.
Следует знать, что организация похорон – является делом личным. Отдавайте предпочтение агентстве, которое может предоставить и окажет необходимую поддержку.
**Спин-шаблон:**
“`
Ритуальные услуги в Минске: организация похорон и учета множества нюансов. В белорусской столице работает немало организаций, предлагающих ритуальные услуги, однако найти достойного подрядчика – может быть непростым делом.
Необходимо знать, что стоимость ритуальных услуг подвержена колебаниям. Определяют стоимость выбранные ритуальные принадлежности, транспортные расходы и прочие факторы. Поэтому рекомендуется заранее уточнить все детали и ознакомиться с полным прайс-листом.
Критерии выбора ритуального агентства в Минске важно обратить внимание на ее опыт и отзывы. Изучите отзывы в интернете, посетите офис, чтобы получить представление о работе. Подтверждение квалификации и соответствия стандартам также является важным показателем.
Удостоверьтесь, что агентство оказывает все виды сервиса, включая оформление документов. Наличие собственного транспорта и помещения для проведения церемонии – дополнительные преимущества.
Завершение формальностей – важная составляющая организации похорон. сбор всех необходимых справок. Это упростит.
Организация церемонии прощания – важный этап, помогающий попрощаться с близким человеком. Определение места захоронения и основываются на волеизъявлении.
Помимо основных услуг ритуальные агентства могут предложить дополнительные услуги, в частности, проведение поминальной трапезы. Консультации психолога также оказывается востребованной.
Необходимо учитывать, что проведение погребения – это индивидуальный процесс. Выбирайте агентстве, которое может предоставить и окажет необходимую поддержку.
“`
Автор предоставляет достаточно информации, чтобы читатель мог составить собственное мнение по данной теме.
Лучшие отели России собраны здесь забронировать номер в отеле предлагаем качество и надежность.
If you are in the mood for a romance that walks on the darker side of fiction, look no further than this sensation by Ana Huang. The relationship between Alex and Ava is built on a foundation of friction and forbidden desire. Many digital readers prefer the Twisted Love PDF format to highlight their favorite quotes and steamy scenes without damaging a paperback. The character development is stellar, watching Alex transform from an unfeeling robot into a man capable of fierce love is a journey worth taking. The story is an emotional investment, one that pays off with a conclusion that leaves you desperate for the next book in the series.
The emotional climax of the book is a tear-jerker, but it leads to a beautiful resolution. The characters have to work for their happy ending. A search for the Twisted Love PDF often ends in a late-night reading binge. The story is gripping and emotionally satisfying. It is a book that proves that love is worth fighting for, no matter the cost.
Конечно, вот ещё несколько положительных комментариев на информационную статью: Это сообщение отправлено с сайта GoToTop.ee
Right here is the perfect site for anybody who hopes to understand this topic. You know a whole lot its almost hard to argue with you (not that I really would want to…HaHa). You definitely put a new spin on a topic which has been written about for many years. Excellent stuff, just wonderful!
Play exciting games and experience real fun at jqk casino.
Multiple notable individuals played a role in advancing jqk.
Con un’offerta sempre piu ampia di giochi da tavolo e slot machine . In questo scenario, Crazy Time Casino Slot Italy si distingue per la sua originalita e innovazione . il mercato dei casino online in Italia sta crescendo rapidamente, con il Crazy Time Casino Slot come uno dei preferiti .
crazy time demo. https://crazytime-italia.com/
il gioco offre una grafica di alta qualita e un’esperienza di gioco unica. il sito web e ottimizzato per essere utilizzato su dispositivi mobili, permettendo ai giocatori di giocare ovunque.
The intricate plotting of the mystery element makes this book more than just a romance. It is a puzzle that the characters have to solve together. Reading the Twisted Love PDF allows you to piece it together along with them. The revelation of the villain is a shock. It is a smart, sharp novel that keeps you guessing. https://twistedlovepdf.site/ Twisted Love Ana Huang Pdf Free Download
Lienminhabcvip. I hear they’re popping up everywhere. Gotta see what all the fuss is about. Maybe some exclusive VIP perks? Let’s hope the games are good! You can check out all the good things on lienminhabcvip.
Bet364app, huh? I download this and test this game! This is my only betting app. Give it a try atbet364app and you never regret.
Chillbetnet, eh? Been hearing whispers around town. Gotta check it out, see if it lives up to the hype. Hopefully not just another flash-in-the-pan. Fingers crossed for some real fun and good payouts! Check it out yourself at chillbetnet!
jest po prostu kasynem, ktore oferuje szeroki wybor gier. Oferuje ono duzy wybor gier, ktore sa dostepne online. Jednym z najwiekszych atutow tego kasyna jest mozliwosc gry w wiele roznych gier.
vulkan spiele https://vulkan-spiele-polska.com/
Vulkan Spiele Casino jest znane jako kasyno, ktore oferuje wiele atrakcji. Gracze moga korzystac z bardzo duzej oferty kasyna . Jednym z najwiekszych atutow tego kasyna jest mozliwosc wygrania bardzo duzej kwoty pieniedzy.
يُعدّ betfinal casino kuwait من الأسماء البارزة في مجال القمار عبر الإنترنت في الكويت. يوفّر هذا الكازينو مجموعة واسعة من الألعاب المسلية والمربحة، مما يجعل تجربة اللاعبين ممتعة ومليئة بالإثارة. بفضل التكنولوجيا الحديثة، يتمتع لعبة betfinal casino kuwait بسرعة وسهولة في الوصول واللعب .
betfinal تنزيل https://betfinal-kw.com/app/
يشدّد betfinal casino kuwait على أهمية الحفاظ على أمان وسلامة المعلومات الشخصية والمالية للجميع. يحرص الكازينو على تزويد اللاعبين بتجربة آمنة ومحميّة، مما يمنحهم الثقة الكافية للاندماج في الألعاب المختلفة.
Es bietet eine breite Palette von Spielen an . Das Casino ist bekannt fur seine benutzerfreundliche Oberflache seine leicht zu bedienende Oberflache und seine sicheren Zahlungsmethoden seine verschiedenen und sicheren Zahlungsoptionen. Die Spieler konnen zwischen verschiedenen Arten von Spielen wahlen konnen aus einer Vielzahl von Spielen auswahlen .
bahigo casino https://bahigosch.com/
Das Bahigo Casino bietet auch eine Vielzahl von Bonusangeboten bietet eine Vielzahl von Bonusen an . Die Spieler konnen von Willkommensboni profitieren konnen von verschiedenen Boni profitieren, die ihre Chancen auf Gewinne erhohen ihre Chancen auf Gewinne verbessern . Daruber hinaus bietet das Casino auch eine loyale Spieler community eine loyalen Spielerbasis .
There is a specific kind of magic in a story where the hero fights his feelings every step of the way, only to fall the hardest. This narrative arc is perfected in the story of Alex and Ava. If you want to experience this emotional journey, looking up the Twisted Love PDF is a common starting point for digital readers. The book explores themes of loyalty, betrayal, and the heavy burden of family expectations. Ana Huang creates a vivid world where the stakes are high and the emotions are higher, ensuring that you are emotionally exhausted – in the best way – by the end. https://twistedlovepdf.site/ Twisted Love Ana Huang Pdf Download
My partner and I absolutely love your blog and find a lot of your post’s to be exactly what I’m looking for. Would you offer guest writers to write content for you personally? I wouldn’t mind publishing a post or elaborating on a few of the subjects you write concerning here. Again, awesome weblog!
Hey there, You have done an excellent job. I will definitely digg it and personally suggest to my friends. I’m confident they will be benefited from this site.
https://share.google/N0jEvS8SSGDVKhxJn
Я прочитал эту статью с большим удовольствием! Она написана ясно и доступно, несмотря на сложность темы. Большое спасибо автору за то, что делает сложные понятия понятными для всех.
La etapa de apuestas te posibilita establecer tu capital a arriesgar, y tan pronto en que clickeas en “Comenzar”, el aviГіn emprende un vuelo con una trayectoria aleatoria.
https://aviamasters.nom.es/
Дизайн веб-платформы Vodka Casino выполнен в стильном и минималистичном ключе.
Для комфортной игры используйте vodka bet регистрация аккаунта и вход, где вас ждут выгодные предложения и бонусы.
Удобный доступ к акциям и широкий выбор игр способствуют популярности Vodka Casino.
Great work! This is the kind of info that are meant to be shared around the web. Disgrace on Google for no longer positioning this put up higher! Come on over and seek advice from my site . Thank you =)
Статья представляет важные факты и анализирует текущую ситуацию с разных сторон.
Автор статьи представляет информацию в объективной манере, избегая субъективных оценок.
Подача материала является нейтральной и позволяет читателям сформировать свое собственное мнение.
The other day, while I was at work, my sister stole my iPad and tested to see if it can survive a 25 foot drop, just so she can be a youtube sensation. My iPad is now destroyed and she has 83 views. I know this is completely off topic but I had to share it with someone!
byueuropaviagraonline
Статья является информативной и предоставляет различные факты и аргументы.
Я очень доволен, что прочитал эту статью. Она оказалась настоящим открытием для меня. Информация была представлена в увлекательной и понятной форме, и я получил много новых знаний. Спасибо автору за такое удивительное чтение!
Посетителей ждёт большой выбор развлечений: от легендарных игровых автоматов до инновационных карточных игр..
Для удобного доступа к играм и бонусам посетите vodka bet восстановить пароль по телефону.
Подтвердив регистрацию, вы моментально получаете доступ к изобилию развлечений и функций.
https://t.me/s/portable_1WIN
Enjoyed looking through this, very good stuff, appreciate it.
В Москве существует множество автосервисов, специализирующихся на Тойота. Профессионалы помогут вам с ремонтом и техническим обслуживанием.
Если вам нужен качественный и надежный автосервис Toyota, мы предлагаем широкий спектр услуг для вашего автомобиля.
Ремонт и обслуживание Тойота требуют от специалистов глубоких знаний. Каждый механик проходит специальное обучение и сертификацию.
В нашем сервисе используются современные технологии и оборудование. Наличие современного оборудования существенно упрощает процесс диагностики.
Наш автосервис обеспечивает надежность и долговечность вашего автомобиля. Мы ценим каждого клиента и стремимся к его удовлетворенности.
Thanks for discussing your ideas in this article. The other point is that if a problem takes place with a computer system motherboard, people today should not consider the risk with repairing the item themselves for if it is not done properly it can lead to irreparable damage to the complete laptop. It’s usually safe to approach any dealer of that laptop for any repair of its motherboard. They’ve already technicians that have an skills in dealing with laptop computer motherboard troubles and can get the right analysis and conduct repairs.
https://taptabus.ru/1win
Beberapa fitur menarik dari gates of olympus demo slot pragmatic play ini seperti mode spin gratis yang bisa berikan penggali berlipat. Selain itu juga bisa masukin mode spin gratis secara langsung dengan fitur buy freespin langsung dapat 10x freespin. Dapatkan penggali berlipat sampai dengan x5000 pada mode spin gratis dengan bantuan zeus. El RTP de Gates of Olympus es 96.50% y se refiere al porcentaje teórico del dinero apostado que un jugador podría recuperar a lo largo del tiempo. Introduce el código de promoción durante el registro El juego es muy volátil, y las características y bonificaciones les resultarán familiares a los aficionados de otros juegos de casino online del mismo proveedor, como Sweet Bonanza. Está totalmente optimizado para móviles y se puede jugar en todos los dispositivos.
https://veronicarayne124.therestaurant.jp/posts/58428632
Jugar Gates of Olympus Xmas 1000 ¡Transpórtate a la Antigua Grecia y siéntete como uno de los dioses con Gates of Olympus, un slot creado para destacar! Abre las majestuosas puertas del Monte Olimpo y sumérgete en una experiencia de juego vivaz, llena de color y, lo más importante, grandes premios y multiplicadores. En Slotify te traemos todos los detalles de esta magnífica tragamonedas, desde su diseño y funciones hasta cómo jugar Gates of Olympus gratis. ¡Vamos! Las máquinas tragamonedas con temática de la Antigua Grecia serían perfectas si éste fuera el caso. Aquí llegamos a Gates of Olympus de Pragmatic Play, un desarrollador que se ha mantenido más activo últimamente. Aunque tiene una premisa familiar, el estudio la utiliza para recuperar un modelo de pago por lo que quieras fuera de lo común. Estamos acostumbrados a los pay-all-ways, pero no es habitual que símbolos corrientes actúen como scatters y otorguen premios. Esto, independientemente de dónde aparezcan, siempre que la cantidad requerida de ellos esté a la vista. Se pueden causar todo tipo de estragos combinando esta función con cascadas y multiplicadores (si Zeus se siente generoso, claro).
Если вы стремитесь приобрести высококачественное медицинское оборудование, которое будет служить надёжным инструментом в вашей работе или бизнесе, стоит посетить страницу aurasonics цена, где представлена вся необходимая информация о продуктах и услугах, предлагаемых компанией Aurasonics.
Аурасоникс – это компания, которая занимается производством высококачественной аудиоаппаратуры. С момента своего основания Аурасоникс стремится к тому, чтобы обеспечить своим клиентам лучшее звучание. Компания постоянно работает над улучшением качества своих изделий. Сегодня Аурасоникс является одной из наиболее популярных компаний в сфере аудиотехники.
Стоимость продукции Aurasonics является конкурентной.
Aurasonics предоставляет детальные инструкции для самостоятельной установки своей продукции.
Aurasonics уже сегодня является одним из наиболее перспективных производителей аудиооборудования.
Это помогает читателям получить полное представление о сложности и многогранности обсуждаемой темы.
Striving to figure out your perfect colors can be really tricky, especially if you have a light olive skin color palette or aren’t confident if olive green is warm or cool. A handy way to start is by doing a vein color analysis or the vein test to assess your undertones, which can expose if you have a red undertone, yellow undertones, or neutral skin tone. This can steer you toward understanding which color season you fall under—be it soft autumn, deep summer, or light spring—and thus, what colors genuinely complement your features.
If you’re interested about exploring your season additionally, there are many color analysis tools and apps that facilitate virtual hair color try on or even AI-generated colour analysis to see which tints suit you best. For some without charge resources and insights about your personal color season, I discovered this site really helpful light beige skin . Remember, knowing your skin tone color palette, like whether you have porcelain olive skin, beige skin tone, or subtle yellow toned skin, can make a real difference in selecting garments and hair colors that highlight your natural beauty.
Hmm is anyone else having problems with the pictures on this blog loading? I’m trying to figure out if its a problem on my end or if it’s the blog. Any responses would be greatly appreciated.
Aztec Fire includes several bonus features that are tightly integrated into its core gameplay. Some casinos may include Aztec Fire free play or demo rounds as part of their welcome or daily login promotions. These offers aren’t built into the game itself, but they can occasionally feature the Aztec Fire slot depending on the casino’s current lineup or promotional focus. He takes care of the stacks of chips placed in front of him, so what does support really matter. The United Kingdom does not require you to pay taxes when it comes to gambling, it serves up your game of choice without requiring the download or installation of any plug-ins or external applications. But seriously, aztec Fire Hold and Win gameplay and special features the awesome comical horror slot of Grave Grabbers and the superb ancient Egypt styled slot of Treasures of the Pharaohs.
https://mantan888.com/joka-casino-review-a-top-choice-for-australian-players/
Copyright © 2023 Eni stores. What most players know as a wild symbol, NetEnt calls it the ‘substitution symbol’ in the Aloha! Cluster Pays slot. It will appear anywhere on the reels and turn into the neighbouring highest-paying symbol. But it won’t substitute the free spins symbol. After the massive launch of the NetEnt official Gun’s and Roses slot you may think the designers would take a well-earned break and not be pushing to break any boundaries with their next game. When I first saw the title on this game I assumed that to be the case – but momma always said assume at your peril and after all what did the Cluster Pays part mean? Virtual passport in hand then and off to this online Hawaiian vacation spot to find out! This bright and breezy slot adds in a selection of useful features to help you make the most of your tropical adventure. The cluster pays element is important, as it means that you can build winning groups of symbols anywhere on the reels while stacked symbols, respins and free spins help to add variety to the gameplay.
Il Crazy Time e un gioco che ha conquistato il cuore degli italiani . Questo gioco e caratterizzato da una combinazione unica di elementi di gioco d’azzardo e di intrattenimento Questo gioco e caratterizzato da una combinazione unica di elementi di gioco d’azzardo e di intrattenimento . La sua popolarita e dovuta anche alla sua disponibilita online Il gioco Crazy Time puo essere giocato comodamente da casa .
crazy time live https://crazytimeit.com/
Планируя отдых в Таиланде, многие задаются вопросом, сколько стоит поездка в Тайланд и сколько денег брать на 10 дней в 2025 году. Тариф путёвки обусловлена сезона — оптимально ехать на Пхукет или Самуи в засушливый сезон, когда погода благоприятная и экскурсии, в том числе трансфер Пхукет–Самуи, протекают без проблем. На Патонге предлагаю посетить рынок и моллы, а также продегустировать экзотические фрукты Таиланда, которые в это время сезонны.
Для путешественников важно знать, как разобраться в аэропорту Пхукета и где поменять деньги — самый удобный обменник зачастую находится вблизи главных торговых центров на Патонге. Если манят экскурсии и массаж в Таиланде, то Пхукет даёт множество вариантов на любые предпочтения. Все советы и важную информацию можно увидеть здесь: торговые центры на патонге . Есть ли безопасность в Таиланде и что оценить в Бангкоке за 2 дня — равным образом такие вопросы затрагиваются часто, так что форум только приветствует ваши оценки и вопросы.
Should you be trying to find out “what season am I” in terms of seasonal color analysis, beginning with your skin tone and undertone is key. For example, a deep summer color palette operates great for those with an olive skin tone or yellow undertone skin, combining cool and muted shades that enhance colors like deep blues and soft roses. Aids like the colour analysis app or an online quiz can uncomplicate this process, offering insights into skin tone charts and vein test undertones to help recognize your best colors, whether it’s the soft summer color palette, deep winter color palette, or light spring color palette. For a helpful guide, check out deep autumn colour palette to investigate palettes and analysis tips suited for various skin tones such as amber skin tone, pale skin, or warm beige skin tone.
It’s also advantageous to consider expert options like color analysis pro for a more complete breakdown; though some users look into how to cancel subscription plans if they want to sample the service before dedicating fully. Whether you’re wondering about the best colors for pale skin or want to find the right clothing colors for yellow skin tone females, understanding your seasonal color palette can really elevate your wardrobe choices. Zero-cost color analysis tools, apps, and quizzes provide a great launch pad to explore skin color types and pinpoint flattering hues that suit your natural coloring, from deep summer celebrities to those with reddish undertone skin.
Интернет магазин ковров в Краснодаре предлагает широкий ассортимент продукции для любого интерьера.
Мир ковров онлайн
Мы постоянно обновляем ассортимент, чтобы предоставить вам самые современные и стильные ковры.
The use of psychological conditioning in this novel is both fascinating and terrifying. By securing a Brave New World PDF, you can study the rhymes and mantras used to control the population. It is an eye-opening read that questions the very nature of free will and destiny.
The World State offers a life without fear, but it also lacks deep connection. If you are searching for the Brave New World PDF, you are likely ready to confront the uncomfortable truths Huxley presents. Allow this masterpiece to provoke your thoughts on what it truly means to be human. https://bravenewworldpdf.site/ Brave New World Epub Vk
This is a story that demands to be shared. Send a friend to find The Book Thief PDF. It is the kind of book that you need to talk about as soon as you finish, creating a community of readers.
Для современных женщин эстетическая косметология стала неотъемлемой частью ухода за собой, позволяя сохранять молодость и свежесть кожи лица на долгие годы.
Косметология занимает центральное место в современных представлениях о здоровье и внешнем виде. Это связано с тем, что люди все больше?ируются о своем внешнем виде и здоровье. Косметология позволяет людям чувствовать себя более уверенно и привлекательно. Кроме того, косметология также включает в себя изучение различных методов и средств для ухода за кожей и волосами.
Косметология стала отдельной областью знаний с множеством поднаправлений. Это позволило специалистам углубить свое знание в конкретных областях и предоставлять более качественные услуги. Косметологи проходят длительный период обучения и практики. Благодаря этому они могут эффективно решать различные проблемы, связанные с кожей и волосами.
## Раздел 2: Виды косметологических услуг
Существует широкий спектр косметологических услуг, предназначенных для разных типов кожи и волос. Это позволяет людям выбирать именно те услуги, которые им необходимы. Косметология может включать в себя как поверхностные процедуры, так и более глубокие вмешательства. К примеру, некоторые процедуры направлены на улучшение внешнего вида кожи, в то время как другие могут быть ориентированы на решение конкретных проблем со здоровьем.
Косметология включает в себя применение современного оборудования и технологий. Это позволяет им эффективно решать задачи и достигать желаемых результатов. Развитие технологий привело к появлению новых, более эффективных методов и средств в косметологии. Благодаря этому косметологи могут предлагать своим клиентам еще более качественные и эффективные услуги.
## Раздел 3: Важность косметологии в современном обществе
Косметология имеет большое значение для многих людей. Это связано с тем, что внешний вид и здоровье напрямую влияют на самочувствие и уверенность человека. Косметология может положительно влияние на психологическое и физическое состояние человека. Благодаря этому люди могут более полноценно участвовать в различных аспектах социальной жизни.
Косметология также имеет экономическое значение, поскольку она составляет значительную часть индустрии услуг. Это означает, что косметология не только приносит пользу отдельным лицам, но и вносит свой вклад в развитие национальной экономики. Косметология предлагает широкие возможности для личного и профессионального роста. Благодаря этому люди могут реализовать свои таланты и интересы в этой области.
## Раздел 4: Будущее косметологии
Косметология будет и далее развиваться и включать в себя новые достижения. Это связано с тем, что люди будут все больше заботиться о своем здоровье и внешнем виде. Косметология будет развиваться параллельно с развитием смежных наук. Благодаря этому косметология сможет еще более эффективно решать различные проблемы, связанные с кожей и волосами.
Развитие косметологии будет влиять на различные аспекты современной жизни. Это означает, что косметология не только будет решать эстетические проблемы, но и будет вносить свой вклад в общее здоровье и благополучие населения. Косметологи будут должны постоянно совершенствовать свои навыки. Благодаря этому они смогут эффективно работать в условиях постоянных изменений и инноваций в этой области.
accutane no prescription pharmacy https://www.google.bj/url?sa=t&url=https%3A%2F%2Feasypharmacies.shop best online pharmacy no prescription
latisse best online pharmacy
Наслаждайтесь удобством доставка алкоголя на дом москва круглосуточно – быстро и просто, прямо до вашей двери.
Сегодня доставка алкоголя входит в число востребованных сервисов для покупателей.
Сегодня доставка алкоголя входит в число востребованных сервисов для покупателей.
pharmacy online usa https://www.google.com.tr/url?q=https%3A%2F%2Feasypharmacies.shop safest best online pharmacy
best online pharmacy paypal
“spintax_text”: “Если собираетесь поездку в Потсдам и раздумываете, что посмотреть за 1 день, предлагаю обратить внимание на главные достопримечательности: Сан-Суси, Голландский квартал, дворец Глиникке и Александровку. Для фанатов истории и природы здесь есть масса парков Германии и живописных мест, как японский сад Дюссельдорфа или Лихтенхайнский водопад в округе. А если побываете в Дюссельдорфе, не пропустите блошиный рынок – хорошее место, чтобы встретиться с местной атмосферой, вот адрес и подробности люббенау .
Для семейного досуга настоятельно рекомендую посетить Фантазия Ленд — прекрасный парк аттракционов, где можно заказать билеты онлайн и заранее ознакомиться с ценами и расписанием. В Берлине рекомендуется заглянуть к берлинскому замку и замку Вальдек, а также посетить немецкую дорогу сказок. Дополнительно, если кому нужно, где купить пиво в Берлине или как функционируют экскурсии на немецкие фабрики, зайдите на форум — посмотрите на темах про фана немецкие предприятия и экологию в Германии, это позволит глубже понять культуру и уклад региона.”
Если планируете поездку по Италии и хотите вникнуть в атмосферу сельской жизни, непременно рассмотрите агротуризм в Тоскане. Агротуризм Италия Тоскана открывает необычную возможность сблизиться с традициями, продегустировать локальные вина и блюда, а также полюбоваться великолепными пейзажами. Для тех, кто хочет связать природу с муниципальными впечатлениями, советую маршрут по Венеции за 1 день — подробную карту и советы можно найти по ссылке квиринальский дворец . К тому же подсказываю уделить внимание на турне по горам Доломиты на машине: там прекрасные перевалы и красивые озера, как, например, озеро в Доломитах. В случае если планируете маршрут из Неаполя, легко добраться до Помпей или на Капри на корабле. Не забудьте и про шопинг в торговых центрах во Флоренции — отзывы о The Mall находятся всякие, но многочисленные посетители отмечают приличные скидки и разнообразный выбор.
https://t.me/s/official_1win_official_1win
alprazolam best online pharmacy https://cse.google.co.ck/url?sa=t&url=https%3A%2F%2Feasypharmacies.shop best canadian pharmacy online
Download the latest update from newtown apk for a smooth and fast gaming experience.
ntc33 provides an impressive range of games to suit all kinds of gamers.
soma best online pharmacy
non prescription pharmacy https://cse.google.com.iq/url?q=https%3A%2F%2Feasypharmacies.shop viagra online canadian pharmacy
generic best online pharmacy
pharmacy technician online course https://cse.google.com.ng/url?sa=t&url=https%3A%2F%2Fsalepharmacies.shop best best online pharmacy forum
Step into the thrilling world of online gambling with wayang88 apk and enjoy nonstop entertainment.
The online gaming industry has welcomed WAYANG88 as a leading platform for players worldwide.
Can I simply say what a relief to discover someone that truly knows what they’re talking about on the web. You definitely realize how to bring a problem to light and make it important. More people really need to read this and understand this side of the story. It’s surprising you’re not more popular given that you most certainly possess the gift.
pharmacy technician online courses
Организуя поездку в Таиланд, критически важно заранее понять с вопросами, сколько стоит путёвка в Таиланд и сколько брать денег в Таиланд на 10 дней. К примеру, отдых в Пхукете как правило обходится дороже, чем на Самуи, но оба острова располагают отличные пляжи и множество экскурсий. Если вы планируете понять, сколько стоит поездка в Таиланд, разумно учитывать затраты на трансфер Пхукет — Самуи, съём байка без прав, а также цены на сеансы массажа в Пхукете и экскурсии.
Чтобы не заблудиться по приезду, следует заранее разузнать, как сориентироваться в аэропорту Пхукета и где разумнее менять деньги — самый прибыльный обменник на Пхукете в основном находится поближе к центру. Также предлагаю познакомиться с восточным рынком Патонг и шопинг-центрами на Патонге, где можно насладиться экзотические фрукты Таиланда и понять, что съесть в Таиланде из пищи и напитков. Детальнее и отзывы можно отыскать здесь рейли бич — незаменимый ресурс для туристов.
В случае если планируете поездку в Таиланд, стоит заблаговременно до поездки ознакомиться с ключевыми островами, такими как Пхукет и Самуи. Пляжи Самуи на карте оптимальны для выбора оптимального места отдыха, а для перемещения между островами пхукет самуи как добраться — существенный вопрос. Кстати, стоит брать в расчет разницу во времени с Таиландом и правила въезда в Таиланд 2025, чтобы поездка произошла максимально комфортно.
Для тех, кто занимается вопросом ценами, полезно знать, сколько денег брать в Таиланд на 10 дней и размер оплаты аренды байка на Пхукете. Также призываю почитать отзывы об андаманда Пхукет и познакомиться с океанариум Пхукет, это превосходный способ разнообразить отдых. Более подробно по планированию путешествия и обмен валюты Пхукет можно отыскать здесь стоимость аренды байка на пхукете .
Discover the exciting world of gambling with 777bet login and win big!
Besides the sportsbook, 777bet also hosts a remarkable online casino.
canadian pharmacy american express https://www.google.co.ve/url?sa=t&url=https%3A%2F%2Fsalepharmacies.shop azithromycin best online pharmacy
https://t.me/s/russia_Casino_1win
pharmacy online canada
https://t.me/s/ta_1win/747
Автор представляет сложные темы в понятной и доступной форме для широкой аудитории.
medco best online pharmacy https://images.google.co.nz/url?sa=t&url=http%3A%2F%2Fsalepharmacies.shop best online pharmacy adderall
buy provigil online
ProviMedsRX http://www.bssystems.org/url?q=https%3A%2F%2Fprovimedsrx.com buy provigil with no prescription
В том случае если вы готовите странствие по Италии, непременно изучите про такие объекты, как Рим и Флоренция. Например, занимательно знать, что территория Венеции и Пьяцца Венеция в Риме — это душа города, а на Авентине реально восхититься великолепными видами. Для почитателей акваториальных прогулок гондола в Венеции — неповторимый опыт; для тех, кто собирается спланировать маршрут, есть прекрасные варианты с полными картами и описаниями, в частности, “венеция за 1 день: маршрут карта” или “пешеходный маршрут по венеции”. Конкретнее можно изучить тут как добраться из милана в аэропорт бергамо .
Также, если намереваетесь в другие регионы, следует принять во внимание расстояния и средства передвижения, к примеру, рим флоренция расстояние или как доехать из Милана в аэропорт Бергамо. Для ценителей природы превосходной идеей будут Доломитовые Альпы — маршрут на машине или походные маршруты по ним невероятно впечатляют. Не забудьте поместить в программу Сикстинскую капеллу и визит в Перуджу, а для любопытных есть варианты осмотреть Потсдам или же сориентироваться, что важно посмотреть во Флоренции за 1 день.
buy provigil online without prescription
rx online pharmacy https://salepharmacies.shop/# online pharmacy no prescription required
Discover a world of thrilling games and winning opportunities with 777 bet online casino.
User data and transaction details are guarded against breaches through strict security practices.
Если вы ищете информацию о техосмотр 2026 в Санкт-Петербурге, посетите специализированный сайт для получения актуальных услуг и цен.
Каждый водитель должен регулярно проходить техосмотр транспортных средств в РФ. Он обеспечивает безопасность на дорогах и предотвращает аварии. Без прохождения этой процедуры невозможно получить полис ОСАГО.
Для жителей Санкт-Петербурга предусмотрены сертифицированные центры техосмотра на территории мегаполиса. В ходе процесса оцениваются важные элементы авто, после чего выдается подтверждающий акт.
На начальном этапе требуется подготовить все нужные документы, как паспорт и акт регистрации транспортного средства. Затем следует пройти осмотр на станции, где проверяются тормоза и другие системы. В конце выдаётся диагностическая карта, подтверждающая соответствие нормам.
В ходе техосмотра оцениваются тормоза, фары и дополнительные ключевые компоненты автомобиля. Кроме того, осматриваются шины на степень износа и их адаптацию к текущим условиям. Каждый проверяемый узел обязан полностью удовлетворять общим нормам безопасности.
В СПб работает обширная сеть аккредитованных пунктов по проведению техосмотра. К примеру, пункт на Московском проспекте предлагает услуги с возможностью предварительной записи. Ещё один вариант — станции в Приморском районе, где всё спланировано для быстрого обслуживания.
Ориентируйтесь на ближайший центр, учитывая его адрес и мнения от клиентов. Узнайте график работы заранее, чтобы избежать очередей. Запишитесь онлайн или по телефону для удобства и экономии времени.
Регулярный техосмотр продлевает срок службы автомобиля и повышает его надёжность. Он снижает вероятность аварий и дорогих ремонтов в будущем. Соблюдайте график, чтобы избежать проблем с законом и обеспечить комфортное вождение.
Если техосмотр просрочен, то последует штраф от ГИБДД. Из-за этого не стоит откладывать процедуру и выполняйте её в установленные сроки. Будьте ответственными водителями, чтобы поддерживать порядок на дорогах.
top online no prescription pharmacies
https://t.me/s/iT_ezCasH
india pharmacy online https://salepharmacies.shop/# buy viagra online no rx canada
Если вы хотите повысить свои навыки продвижения, обязательно пройдите обучение XRumer и GSA, чтобы эффективно использовать все возможности этих инструментов.
Интерфейс включает разнообразные настройки и блоки для обработки сайтов.
Если собираетесь отдых на озере Шира, настоятельно советую обратить внимание на места отдыха на Шира, которые готовы предложить разные варианты проживания. В частности, база отдыха Шира Жемчужный известна комфортными домиками и даже бассейном, что придает отдых качественным и разнообразным. Для тех, кто желает найти жилье близко к природой, базы отдыха Шира с видом на озеро — прекрасный выбор, а чтобы основательнее понять варианты, можно найти информацию здесь: шира бегущая по волнам .
Весьма интересны базы отдыха Три Звезды Шира и Бегущая по Волнам, которые предлагают превосходный сервис и различные развлечения. Если нужно понять, где остановиться у озера Шира или интересует цена на домики в Шира Жемчужный, обязательно изучите комментарии и фото на форумах, а также оцените такой своеобразный объект, как Сад Камней Шира, что обеспечит изюминку вашему отдыху.
best india pharmacies online
Download 1xbet apk and enjoy a smooth and user-friendly betting platform on your device.
Such an interface allows swift access to matches, betting possibilities, and account settings.
overseas prescriptions online https://salepharmacies.shop/# online pharmacies canada
I am not rattling good with English but I come up this real easy to understand.
http://www.onlinepharmaciescanada.com
Try your luck and enjoy the exciting game onswiminator free, which will give you a sea of ??pleasure and bonuses.
Swiminator Slot is a popular online slot game inspired by an adventurous aquatic theme.
В лабиринте игр, где любой ресурс пытается заманить обещаниями быстрых джекпотов, топ 10 рейтинг казино
превращается той самой картой, которая проводит мимо дебри обмана. Игрокам профи плюс начинающих, кто надоел с пустых обещаний, это средство, чтобы увидеть подлинную rtp, как вес выигрышной фишки у пальцах. Без лишней воды, просто реальные клубы, где выигрыш не просто цифра, но конкретная везение.Составлено из яндексовых трендов, как паутина, что ловит самые свежие веяния по сети. В нём отсутствует пространства для стандартных приёмов, каждый момент словно ставка на столе, в котором блеф проявляется немедленно. Игроки знают: на стране стиль речи на иронией, там ирония притворяется под рекомендацию, помогает обойти рисков.В https://www.wattpad.com/user/Gamer_iGaming данный рейтинг находится как открытая колода, подготовленный для раздаче. Загляни, когда хочешь ощутить биение подлинной игры, без иллюзий и неудач. Игрокам кто ценит ощущение приза, такое как иметь фишки на пальцах, вместо пялиться на дисплей.
online canadian pharmacies https://salepharmacies.shop/# discount 0nelinr pharmancy
safe rx india
Современные интерьеры становятся ещё удобнее с управляемые шторы, предлагающими качество и надежность в каждом элементе.
Электрокарнизы для штор и автоматические жалюзи — современные решения для комфорта в доме.
Lunes a Domingo 05:00 A.M. – 3:00 A.M. This website is using a security service to protect itself from online attacks. The action you just performed triggered the security solution. There are several actions that could trigger this block including submitting a certain word or phrase, a SQL command or malformed data. Inserisci il tuo indirizzo e-mail per reimpostare la password. Gioca gratis a Gates of Olympus slot online e conoscila in tutte le sue sfumature. Non avrai limiti di tempo e non dovrai registrarti. Più giochi a Gates of Olympus slot gratis più aumenti le tue probabilità di vincere. Giocare la versione demo di Gates of Olympus offre diversi vantaggi: Come la versione originale, “Gates of Olympus Super Scatter” è ambientata nell’affascinante mondo della mitologia greca, con Zeus che gioca un ruolo centrale. La grafica è eccezionale, con colori vivaci e dettagli intricati che catturano l’immaginazione. Le animazioni sono fluide, e il design del gioco è progettato per immergere completamente il giocatore nell’ambientazione mitologica.
https://hedgedoc.catgirl.cloud/s/Swo2xeroj1
Hello there! I know this is somewhat off topic but I was wondering which blog platform are you using for this website? I’m getting tired of WordPress because I’ve had issues with hackers and I’m looking at options for another platform. I would be fantastic if you could point me in the direction of a good platform. Aluminium Extrusion Profiles This is one of the best articles I’ve read on this subject. Thank you for sharing your insights. Sebbene i giochi di slot 777 gratis siano semplici in termini di grafica e meccanica, sono dei veri e propri re della scena dell’iGaming, poiché il software classico è stato popolare per decenni e anche i neofiti del mondo dei casinò online apprezzeranno queste vibrazioni tradizionali. I am a highly experienced SEO expert with over 12 years of experience in the digital marketing industry. I have a proven track record of helping businesses improve their search engine rankings and generate more traffic to their websites. I am an expert in all aspects of SEO, including keyword research, on-page optimization, off-page optimization, and technical SEO. I am also proficient in Google Analytics and other SEO tools. I am a results-oriented SEO professional who is passionate about helping businesses succeed. I am always up-to-date on the latest SEO trends and best practices.
mexican pharmacy online phentermine https://salepharmacies.shop/# discountpharmacyonlineusa.com
Когда планируете поездку на Тенерифе, безусловно заезжайте в Monkey Park Tenerife — чудесный зоопарк, где есть возможность наблюдать драконовое дерево и ознакомиться с местной флорой и фауной. Более того, рекомендую вам посетить пляж Тереситас и бассейны Lago Martianez в Пуэрто-де-ла-Крусе, это одни из самых ключевых точек интереса Тенерифе, а также прочитайте о программу Carnevale Tenerife 2025 — в числе самых запоминающихся событий на Канарских островах metro walencja .
Если вас интересует транспорт, bus Tenerife и линия teneriffa bus 343 fahrplan способствуют быстро проехать до нужных мест. За исключением Тенерифе, стоит увидеть и другие города Испании у моря, например, Барселону с пляжами и парком Цитадель, а также Малагу и Валенсию с её собором и шелковой биржей. Климатические условия на Тенерифе в ноябре и марте, в основном, приятная, что делает эти месяцы хорошим временем для отдыха.
Если вы ищете информацию о грузовой техосмотр в Санкт-Петербурге, посетите специализированный сайт для получения актуальных услуг и цен.
Технический осмотр автомобиля обязателен для всех водителей в России. Техосмотр помогает поддерживать безопасность на автодорогах, избегая потенциальных инцидентов. Отсутствие техосмотра не позволит застраховать автомобиль по ОСАГО.
Для жителей Санкт-Петербурга предусмотрены сертифицированные центры техосмотра на территории мегаполиса. Процедура включает проверку ключевых систем автомобиля и выдачу диагностической карты.
Сначала водителю нужно подготовить необходимые документы, такие как паспорт и свидетельство о регистрации. Затем следует пройти осмотр на станции, где проверяются тормоза и другие системы. В конце выдаётся диагностическая карта, подтверждающая соответствие нормам.
Процедура охватывает диагностику тормозной системы, осветительных приборов и иных важных частей. Также проверяются шины на износ и соответствие сезонным нормам. Все диагностируемые системы авто должны быть в полном соответствии с официальными требованиями.
Жителям Санкт-Петербурга доступны многочисленные официальные станции для прохождения техосмотра. К примеру, пункт на Московском проспекте предлагает услуги с возможностью предварительной записи. Ещё один вариант — станции в Приморском районе, где всё спланировано для быстрого обслуживания.
Выберите ближайший пункт, ориентируясь на его расположение и отзывы пользователей. Узнайте график работы заранее, чтобы избежать очередей. Оформите запись через интернет или звонок, что упростит процесс.
Регулярный техосмотр продлевает срок службы автомобиля и повышает его надёжность. Такая процедура уменьшает шансы на инциденты и экономит средства на последующие ремонты. Следуйте рекомендованному расписанию, избегая юридических последствий и гарантируя безопасную езду.
В случае задержки с техосмотром предусмотрены санкции, включая штрафы от ГИБДД. Поэтому не игнорируйте сроки и проходите осмотр вовремя. Стремитесь к ответственному поведению, сохраняя безопасность на трассах.
purchase prednisone
prednisonepharm https://prednisonepharm.shop/# deltasone
buy prednisone online
Sally and her younger sister, Bear, chose contrasting career paths. So look for online casinos that accept your countries currency, requiring a fresh spin. Don’t be surprised if you see flowing reels and collection payment systems on Foxium – they have it all, so you can play a lot more. One feature that we havent mentioned yet, is the net amount that is won back by the player. If you already know which game you want to play, or a certain amount is won. For mega wins, online pokies came to Australia and it was an exciting time. This means that you must deposit 5000 to enjoy this offer, and youve got yourself a slot that can deliver frequent big wins. This is your chance to win this book collection signed by NASA Astronauts, Buzz Aldrin, Charles Duke, and Gene Cernan! Defensive structure has improved, evidenced by two clean sheets in the latest three. They still concede spurts of chances when stretched (Castellón 1-3), but counter-punch quality remains. Away resilience at Valladolid suggests they can absorb pressure for long spells. Shot volume is modest; chance quality relies on quick vertical transitions. First goal matters: they are far more effective protecting a lead than chasing.
https://ssr.mtc.ac.in/chicken-road-by-inout-a-casino-game-review-for-multi-players/
K9WIN is a Asian top leading bookmaker that currently targeting more than 9 countries. Such as Pakistan, India, Indonesia, Singapore, Malaysia, Myanmar, Thailand, Vietnam and Cambodia. With more than 3 million users currently downloaded our app. K9win has been establish more than 10 years. And is license under Curacao. It is a 100% safe and secure site. With the goal of enhancing the experience of betting, the 1win app provides several bonuses for all users who download and install the application. In addition to cashback prizes and an exclusive mobile no-deposit bonus for downloading the program, these perks include a substantial 500% welcome bonus for newbies. New players at Glory Casino Pakistan are welcomed with a big welcome offer package which not only includes a match bonus but free spins. The usual bonus is a 100% match on the 1st deposit, upto a maximum in PKR. In addition, you can claim 50 free spins on top slot games with most offers. These special offers are focused on giving a powerful head start for every gamer.
prednisonepharm https://prednisonepharm.shop/# prednisonepharm
buy prednisone
xenipharm https://xenipharm.top/# xenipharm
xenipharm
generic orlistat https://xenipharm.top/# xenipharm
generic orlistat
buy ed pills medication https://eropillseasy.shop/# buy ed meds pills
Choose a trusted platform for your gaming sessions by heading to mostbet casino es confiable, offering strong reliability and excellent playing conditions.
Throughout the story, he grapples with desire, ethics, and fate.
edpillseasy
Sprawdza oferty kasyn pod względem bezpieczeństwa i rzetelności. Regularnie pisze o nowoczesnych metodach płatności, dzieląc się swoimi spostrzeżeniami i wiedzą. Mitologia i bogowie to często powielany motyw w grach online. Wielu producentów stawia na ten sprawdzony temat rozgrywki. W wolnej chwili możesz sprawdzić bliźniacze automaty podobne do Gates Of Olympus online za darmo. Przeczytaj recenzje gier Age of Gods i Zeus Slot z naszej strony. Wybierz grę, która spełni Twoje wymagania. Kasyno internetowe na prawdziwe pieniądze Przez cały rok WSOP Circuit przeniósł się również online na razie, trzeba również być bardzo wykwalifikowanych. BetOnRed oferuje szeroką gamę opcji zakładów sportowych. Platforma obejmuje popularne sporty takie jak piłka nożna, koszykówka, tenis i wiele innych. Oferują także zakłady na mniej popularne sporty i wydarzenia, zapewniając różnorodne doświadczenie zakładów dla użytkowników.
https://www.protechshine.com/34/icecasino-jak-grac-i-wygrywac-w-polskim-kasynie/
Kasyno online Mostbet oferuje niesamowite produkty do gier i opcje zakładów. Kategorie obejmują: Prawa autorskie © 2009–2025 Mostbet. Wszelkie prawa zastrzeżone. Mostbet jest własnością i jest prowadzony przez Bizbon N.V., spółkę zarejestrowaną i licencjonowaną na Curaçao (nr licencji 8048 JAZ2016-065). Obsługą transakcji finansowych zajmuje się Venson LTD (nr rejestracyjny HE 352364). Siedziba prawna firmy znajduje się przy ul. Stasinou 1, budynek MITSI BUILDING 1, I piętro, pokój 4, Plateia Eleftherias, 1060 Nikozja, Cypr, natomiast biuro operacyjne mieści się przy Kadmou Street 4, w S.I. OLYMPIA BUSINESS CENTER, Agios Andreas, 1105 Nikozja, Cypr. Aby zacząć grać w tę popularną grę na pieniądze, musisz założyć konto w Mostbet i wpłacić środki na swoje saldo. Demo Gates of Olympus jest dostępne bez rejestracji. Jednak wszystkie wygrane w grze demo będą wirtualne.
edpillseasy https://eropillseasy.shop/# edpillseasy
Hello there! edpillseasy excellent web page.
Если вы мечтаете о надежном и уютном жилье, обратите внимание на строительство каркасных домов в спб, обеспечивающие комфорт и долговечность.
Основное преимущество каркасных домов – скорость строительства и небольшая масса конструкции.
Hello guys!
I came across a 152 valuable resource that I think you should browse.
This platform is packed with a lot of useful information that you might find valuable.
It has everything you could possibly need, so be sure to give it a visit!
https://liveforbball.com/how-to-choose-your-basketball
Furthermore don’t forget, guys, that one at all times are able to in this particular piece discover responses for the most the very confusing queries. Our team tried to lay out the complete data using the most extremely understandable manner.
mexpharmrx
mexpharmrx https://www.google.gy/url?q=https%3A%2F%2Fmexpharmrx.com reliable online pharmacy
reliable online pharmacy
legitimate online pharmacy
pharmacy technician online https://www.google.cf/url?sa=t&url=https%3A%2F%2Fcanadianmedsmax.com propecia online pharmacy
online pharmacy oxycontin https://www.google.mg/url?sa=t&url=https%3A%2F%2Fmexpharmrx.com online pharmacy
canadianmedsmax
Create unique marks for your business with our stamp online maker free.
Online platforms can offer lower prices by cutting out additional charges from conventional outlets.
pola otomatis gates of gatotkaca max win Hola buen día, somos el equipo “transformers” de sexto grado, grupo A, de la escuela primaria Ford No. 8 Gral. Vicente Guerrero, zona escolar 096, sector 20, Guamúchil, Sinaloa. Los personajes principales son : Canela, el monstruo de la basura, el zorro, Der, Mip, Flippy, Any y Forestín. La enseñanza que nos dejaron los videos es que debemos de cuidar el planeta Tierra y evitar una catástrofe, también como debemos separar la basura(orgánica e inorgánica ). En nuestra opinión todas las personas debemos poner nuestro granito de arena, para mejorar nuestro medio ambiente. Guatemala, junio de 2019. – En un mundo conectado, solo las compañías que se transformen en una empresa inteligente tendrán posibilidad de sobrevivir en el futuro. El próximo 3 de septiembre de 2019, se llevará a cabo la sexta edición del Tigo Business Forum 2019, que tendrá como tema central “Connected world, smart business”. Se espera la participación de más de 1000 CEOs y CFOs de empresas nacionales y multinacionales.
https://esas-eg.org/resena-de-nine-casino-la-experiencia-definitiva-para-jugadores-espanoles/
Eva es una redactora de talento apasionada por la industria del juego online, centrada específicamente en el mercado español. Ofrece análisis en profundidad y opiniones sobre casinos online y vídeo tragaperras, ayudando a los jugadores a tomar decisiones con conocimiento de causa. Su experiencia y su atractivo estilo de redacción la convierten en una fuente de confianza en el mundo del juego online. 225847 667703The place else may just anybody get that type of information in such an ideal means of writing? 377539 © 2021 Derechos Reservado Vos Radio Ecuador TELF: 0999236775 El blackjack es quizás el juego de mesa de casino más apreciado del mundo, y utiliza la función de retiros acelerados en el programa VIP. Si esto suena como algo que le interesaría, un jugador obtiene dinero del casino para jugar. No dicen que todo es perfecto, realmente no podemos pensar en un mejor torneo de la PGA en el que participar.
mexica online pharmacy
online pharmacy cialis https://www.google.hu/url?q=https%3A%2F%2Fcanadianmedsmax.com reliable online pharmacy
pharmacy technician online https://www.google.com.sl/url?sa=t&url=https%3A%2F%2Fmexpharmrx.com mexmedimax
mexicare meds
medicine in mexico pharmacies https://www.google.com.cy/url?sa=t&url=https%3A%2F%2Fcanadianmaxmeds.top mexicare meds
mexmedimax
mexicare meds
online mexican pharmacy https://www.google.com.au/url?sa=t&url=https%3A%2F%2Fmexpharmrx.com online pharmacy xanax
order from mexican pharmacy online https://www.google.cf/url?sa=t&url=https%3A%2F%2Fcanadianmaxmeds.top order from mexican pharmacy online
online pharmacy reviews
mexicare meds
online pharmacy review https://maps.google.mn/url?q=https%3A%2F%2Fmexpharmrx.com mexmedimax
online mexico pharmacy usa https://www.google.pt/url?q=https%3A%2F%2Fcanadianmaxmeds.top mexicare meds
pharmacy technician certification online
mexicare meds
online pharmacy xanax https://maps.google.rw/url?q=http%3A%2F%2Fmexpharmrx.com cvs pharmacy application online
isotretinoin from mexico https://toolbarqueries.google.com.my/url?sa=t&url=https%3A%2F%2Fcanadianmaxmeds.top buy meds from mexican pharmacy
best online pharmacies
online pharmacy
Stream Free PROMOTED Read more › It’s your shot with winning big and even playing new position games you love at top on the internet casino real funds sites. The Active Gambling Act (IGA) of 2001 manages online casinos and even aims to protect Aussie players from not regulated gambling environments.” “The IGA prohibits online gambling companies from supplying their services to Australian players. Licensing and regulation play a pivotal function in ensuring the safety and fairness involving online casinos. Top Australian online internet casinos are licensed simply by reputable authorities, providing a secure environment for players. It’s your shot with winning big and even playing new position games you love at top on the internet casino real funds sites. The Active Gambling Act (IGA) of 2001 manages online casinos and even aims to protect Aussie players from not regulated gambling environments.” “The IGA prohibits online gambling companies from supplying their services to Australian players. Licensing and regulation play a pivotal function in ensuring the safety and fairness involving online casinos. Top Australian online internet casinos are licensed simply by reputable authorities, providing a secure environment for players.
https://tangtoto.net/goldex-casino-review-a-top-choice-for-australian-players/
Learn how to get the most out of your Gates of olympus experience. Go to the institution, but with slightly different math. Seamlessly blending the Scatter Pays mechanic with the tumble feature, Gates of Olympus delivers an intense and long-lasting slot experience, Zeus himself randomly places multipliers on the reels, boosting wins and even triggering the coveted max win for lucky players. Intrigued? Try the free-to-play Gates of Olympus demo to experience these captivating mechanics firsthand. One of the greatest features of this online casino and sportsbook is definitely the transparency, but that theres definite room for improvement. Software-wise, similar slots including The Great War and Spider-Man are close also. Tricks to win at the Gates of Olympus casino game while climbing these nine VIP tiers, table games.
cvs online pharmacy https://cse.google.at/url?sa=t&url=https%3A%2F%2Fmexpharmrx.com online pharmacy xanax
mexicare meds https://images.google.com.bn/url?q=https%3A%2F%2Fcanadianmaxmeds.top mexicare meds
mexican pharmacies online
mexicare meds
Die Ausführung „Thermo“ ist mit einer 80 mm starken Wärmedämmplatte aus Polyurethan-Hartschaum mit beidseitiger Alubeschichtung versehen. Diese ist in einem umlaufenden Z-Winkelrahmen eingebaut und kann nach der Montage einfach in den Einbaurahmen eingelegt werden. Das System PRO+ Thermo ist speziell geeignet für Schächte, für die eine spezifische Anforderung an die Temperatur besteht. Mit dem neuen Glücksspielstaatsvertrag von 2021 kommt auch die Einsatzsteuer von 5,3% bei Echtgeld Slots. Zwar bringt dies eine Menge Steuereinnahmen, aber ist klar zum Nachteil eines Slots Casino. In unserem separaten Testbericht zu den Online Casinos mit Geldspielautomaten ohne Steuer erfährst du wie du trotzdem legal spielen kannst. Supported by the Local Enterprise Office Westmeath REVISIONEN REICH Koppstrasse 112 6 EG 3002A-1160 Wien
https://polishmodernglassart.pl/vavada-casino-review-spielspas-und-gewinnchancen-fur-spieler-aus-osterreich/
Gates of Olympus Dice, presented by Pragmatic Play, invites players to the ancient world of Olympus. This online slot game captivates with its vibrant design and immersive soundtrack, capturing the essence of the gods’ dwelling. Set on a 6×5 grid, it provides an exciting gaming experience. Über die Autorin Braggs exklusives Portfolio beliebter Online-Casino-Spiele umfasst leidenschaftlich gefertigte Bragg Studios-Titel von hauseigenen Marken wie Atomic Slot Lab, Indigo Magic und Oryx Gaming sowie eine breite Palette von Spielautomaten-Titeln von sorgfältig ausgewählten Partnerstudios, die von Bragg betriebene Spiele entwickeln. Gates of Olympus with an RTP of 96.50% and a rank of 570 is an excellent choice for players who value moderate risk and consistent payouts. This RTP guarantees stability without sharp fluctuations.
online pharmacy xanax https://www.google.com.pe/url?sa=t&url=https%3A%2F%2Fmexpharmrx.com online pharmacy propecia
mexicare meds https://cse.google.com.cu/url?sa=t&url=https%3A%2F%2Fcanadianmaxmeds.top mexicare meds
You must spend time exercising restraint and adhering to the rules you have set for yourself, depending on how strong their hand is. Prize gates of olympus in this paragraph I will try to answer the question, the mobile slot is no different from the desktop version since it features all the Jungle Wild slots elements to winnings. There are more lame promos for existing customers, gates of olympus popular online slot machine but it should be noted that for unlimited experience of pokies through this gateway – you would have to conduct some in-app purchases. Give it a try by Signing Up to PlayOjo Today, but you can still visit other casinos and play your favorite games. We read every piece of feedback, and take your input very seriously. The demo is the perfect tool to confirm if the high-volatility, high-potential gameplay suits your style. You will quickly learn if you enjoy the anticipation of the big multiplier wins that define the Gates of Olympus experience.
https://laxusspa.com/fortune-gems-a-captivating-online-casino-experience-for-players-from-india/
Curious to try it before committing? Launch the Gates of Olympus demo to experience the slot for free – or play this online casino slots or fiat online at Winz casino. No account? Join now 304 Buitenkloof Studios, Cape Town, 8001, South Africa We’d recommend this game if you enjoy the original Gates of Olympus slot game, or you’re just a fan of mythical slots in general. The Super Scatters really make this game stand out. Plus, who wouldn’t want to win up to 50,000x their stake? Rise of Olympus and Gates of Olympus are both mythology-themed slots, but they offer distinct experiences. Rise of Olympus (by Play’n GO) features a 5×5 grid with cascading wins, where Greek gods Hades, Poseidon, and Zeus grant powerful modifiers. It has a darker, more atmospheric design with a focus on combo-building and multipliers.
cvs online pharmacy
order kamagra from mexican pharmacy
Это способствует повышению эффективности работы и снижению эксплуатационных затрат.
спецтехника в лизинг https://kommercheskij-transport-v-lizing04.ru/specztehnika/
Автор статьи поддерживает свои утверждения ссылками на авторитетные источники.
mexmedimax https://www.google.com.om/url?q=https%3A%2F%2Fmexpharmrx.com us online pharmacy
mexican pharmacy https://maps.google.es/url?q=https%3A%2F%2Fcanadianmaxmeds.top medication from mexico pharmacy
mexmedimax
online pharmacy viagra https://images.google.co.zw/url?q=https%3A%2F%2Fmexmedimax.com online pharmacy
mexican pharmacy online
Для организации вашего события идеально подойдут купить браслеты для мероприятий, которые обеспечат надежный контроль доступа и удобство для гостей.
Их применяют для быстрой идентификации участников и управления доступом.
mexmedimax https://cse.google.nr/url?sa=t&url=https%3A%2F%2Fmexmedimax.com viagra online mexican pharmacy
mexmedimax
mexicare meds
Compared to computers 10 years ago, you don’t need to claim rebates or use a promo code. Professional boxers compete in weight classes in order to ensure the fights are competitive and so that the fighters in such bouts are protected from finding themselves in the ring against someone simply too large or heavy for them to fight, gates of olympus wilds ‘Her Majesty’s Plate’. As simple and as fast-paced as this game is it is not at all boring, that casino was in the news recently. It includes slots games, for its owner offered free accommodation to those who were fleeing Hurricane Florence. Gates of olympus mystery symbols that can reveal instant cash prizes apart from offering a considerable gaming variety, its time to look at the gaming selection and the bonuses that are offered to supplement your play. These are the biggest contests featuring the best teams, 15 free spins if you land 3. Poker sites accepting Skrill are available online round the clock so you can play anytime, and 20 if you land 4 scatters.
http://www.regiointernet.tv/casino-lukki-casino-legit-an-honest-review-for-australian-players/
The newest Shell out Anyplace system is mostly a group pays motor. That it system doesn’t have wilds, because it might possibly be a keen overkill, in my opinion. It’s safer to state that I experienced a much greater day with Doors of Olympus a lot of versus new. This’s a much bigger, bolder, and better kind of one of the most legendary hits out of all time. Of course, Gates of Olympus is beautifully optimized for all devices, so you can enjoy it on the go. The Gates of Olympus slot machine offers a unique mix of exciting bonuses and classic features. It is suitable for gamers of any experience level, from first-timer to seasoned pro. Moreover, it promotes fairness between first-timer and loyal players by offering them the same bonus opportunities. A Leading Name in Slot Gaming. As a heavyweight in the realm of slot gaming, Pragmatic Play boasts a remarkable collection of games that have reached iconic status, enchanting legions of players worldwide. The game currently under scrutiny is a testament to their enduring appeal, consistently remaining a favorite and continuing to win over the affections of countless gaming enthusiasts.
online pharmacy tadalafil https://maps.google.com.uy/url?q=https%3A%2F%2Fmexmedimax.com cialis online pharmacy
mexicare meds https://www.google.com.na/url?sa=t&url=https%3A%2F%2Fmexicaremeds.com mexicare meds
india pharmacy online
mexican pharmaceuticals online
Good day! Do you know if they make any plugins to protect against hackers? I’m kinda paranoid about losing everything I’ve worked hard on. Any tips?
us pharmacy online https://maps.google.rw/url?q=http%3A%2F%2Fmexmedimax.com online pharmacy review
buying prescription drugs in mexico online https://toolbarqueries.google.com.sv/url?q=https%3A%2F%2Fmexicaremeds.com mexicare meds
mexicare meds
mexicare meds https://toolbarqueries.google.com.ec/url?q=http%3A%2F%2Fmexicaremeds.com buying from online mexican pharmacy
mexico drug stores pharmacies
mexican pharmacy for americans https://maps.google.ie/url?sa=t&url=https%3A%2F%2Fmexicaremeds.com cheap cialis mexico
Попробуйте свои силы в казино самолетик 1win, и испытайте удачу в уникальном игровом процессе!
Каждый участник имеет шанс получить крупный выигрыш, играя в эту удивительную игру.
Используйте Винлаб промокоды, чтобы получить выгодную скидку на первый заказ в приложении.
Рекомендуется регулярно проверять приложение для получения актуальной информации о промокодах.
generic drugs mexican pharmacy
After the end of a cascade feature sequence, all the Multiplier symbols are added together and the total win of the sequence is multiplied by the final value. Match 8-30 symbols anywhere on the grid to win. Multiplier symbols can land on any spin or tumble, boosting wins by up to 500x. If more than one multiplier symbol lands, their values are added together and applied to the total win. What to expect: Rasakan sensasi slot gacor maxwin dan slot gacor gampang menang hari ini. Mulai bermain sekarang di RAJAMAHJONG, nikmati kemenangan maksimal, dan jadilah bagian dari komunitas slot online terbaik! What to expect: Pay attention to wagering requirements, time limitations, and eligible games. By utilizing bonuses effectively, you can enhance your winning opportunities and make the most of your Gates of Olympus 1000 Dice experience.
https://www.perlina.net.ua/betonred-game-review-a-thrilling-australian-casino-experience/
One of the biggest providers of slots & live casino titles in the US, Pragmatic Play has become the premiere software studio to watch out for in the market. Beginning operation in 2015, Pragmatic Play have been integral in producing some of the most memorable slots titles, with titles like Big Bass Bonanza spawning over 25+ sequels. In 2019, the studio expanded into live casino titles; with titles like Sweet Bonanza CandyLand and Boom City competing with the premium titles on offer from Evolution. This website is using a security service to protect itself from online attacks. The action you just performed triggered the security solution. There are several actions that could trigger this block including submitting a certain word or phrase, a SQL command or malformed data. Also explore our full range of dice games, from timeless classics to modern variants. For an even more immersive experience, dive into our live games, where you can interact with live dealers and feel the atmosphere of real casino table games from the comfort of your own home. Fans of classic slots will also find a wide choice of exciting titles with stunning graphics and innovative features.
Приветствую! Стоит заранее разобрать — вибрация капота на скорости. Нет времени самому — вот толковый сервис: профессиональная шумоизоляция . Как правило дело не в одной зоне: арки плюс днище — всё это требует обработки. В общем, приложи руку к потолку — звук гулкий? Соответственно металл не демпфирован. Своими руками: один из самых эффективных способов — демпфер плюс шумопоглотитель, на первом этапе — полное прилегание. Вместо заключения: реально работает.
online pharmacy https://cse.google.hn/url?sa=t&url=https%3A%2F%2Fmexicaremeds.com mexican mail order pharmacies
jahonning yetakchi onlayn kazinolari qatoriga kiruvchi tashkilot . U yuqori sifatli o’yinlari va Professionalligi bilan ajralib turadi . 888starz o’zining yangi va klassik o’yinlari bilan foydalanuvchilarni tarbiyalaydi .
888starz вход в личный кабинет https://888staruzbeki.com/
mexicare meds
zithromax mexican pharmacy https://cse.google.com.br/url?sa=t&url=https%3A%2F%2Fmexicaremeds.com mexicare meds
mexicare meds
Для качественного ухода за вашим автомобилем посетите детейлинг полировка кузова.
После полировки наносят защитные средства для сохранения результата.
mexicare meds https://www.google.com.sl/url?sa=t&url=https%3A%2F%2Fmexicaremeds.com mexicare meds
Hello there! Do you know if they make any plugins to assist with SEO? I’m trying to get my blog to rank for some targeted keywords but I’m not seeing very good gains. If you know of any please share. Appreciate it!
sbsmeds
Статья содержит обширный объем информации, которая подкреплена соответствующими доказательствами.
buy accutane pills online https://sbsmeds.sbs/# buy accutane online
sbsmeds
The Title Balcony Nai Yang is a modern beachfront condominium in Phuket, located on the coast in the Nai Yang area.
The Title Balcony Nai Yang emerges as a cutting-edge beachfront condominium in Phuket, placed directly along the coastline in the Nai Yang area. This condominium offers breathtaking views of the Andaman Sea boasts spectacular views of the Andaman Sea . The location is perfect for those who want to wake up to the sound of waves ideal for individuals who wish to awaken to the sound of waves . The Title Balcony Nai Yang is designed to offer a luxurious lifestyle constructed to present an opulent lifestyle.
buy accutane uk https://sbsmeds.sbs/# buy isotretinoin online
sbsmeds
sbsmeds https://sbsmeds.sbs/# sbsmeds
sbsmeds
purchase accutane http://sbsmeds.sbs/# order isotretinoin
Для тех, кто ценит функциональность и практичность, складной нож москва становится незаменимым компаньоном в повседневной жизни.
в эпоху Возрождения, когда мастера начали создавать сложные механизмы. В те времена складной нож использовался как инструмент для gunlukх задач, таких как резание веревки или открытие консервов . С течением времени дизайн и функциональность складного ножа ??но совершенствовались, чтобы удовлетворять меняющимся потребностям людей .
Складной нож также стал символом ручного труда и умения мастеров . В современное время складной нож продолжает эволюционировать, включая новые функции и материалы . Его популярность обусловлена его эстетической привлекательностью и историческим значением.
Конструкция складного ножа представляет собой сочетание инновационных технологий и традиционных методов. Лезвие складного ножа изготовлено с использованием передовых технологий, которые повышают его эффективность. Ручка складного ножа разработана с учетом различных стилей и предпочтений.
Складной нож также оборудован системой быстрого открытия, которая позволяет быстро и легко выдвинуть лезвие . Его функциональность делает его незаменимым атрибутом для любителей активного отдыха. Складной нож стал неотъемлемой частью многих профессий и хобби.
Существует множество вариантов, от бюджетных до премиальных, чтобы удовлетворять разным бюджетом и ожиданиям. Один из популярных видов складных ножей – швейцарский армейский нож, который известен своей универсальностью и функциональностью . Другой вид – тактический нож, который разработан для использования в экстремальных ситуациях.
Каждый вид складного ножа разработан с учетом различных условий и ситуаций . Выбор складного ножа должен учитывать такие факторы, как размер, материал и функциональность . Складной нож может быть использован как подарок или атрибут коллекционера .
Использование складного ножа требует осторожности и внимания к безопасности . При использовании складного ножа необходимо следовать правилам безопасности и инструкциям . Уход за складным ножом должен быть выполнен с использованием специальных инструментов и материалов.
Складной нож должен быть хранен в безопасном месте, недоступном для детей . При правильном использовании и уходе складной нож будет сохранять свою функциональность и эффективность . Складной нож остается популярным среди людей, которые ценят его практичность и историю.
Снижение веса в санатории часто включает в себя [url=https://lechebnoe-golodanie.ru]голодание пожилых людей[/url], которое помогает в очистке организма и общем оздоровлении.
требует особого внимания из-за различных социальных и экономических факторов. Учитывая, что пожилым людям приходится экономить на всем, они часто вынуждены ограничивать себя в еде . Это негативно влияет на их физическое и психическое состояние.
Последствия голодания для пожилых людей могут быть очень тяжелыми . Голодание делает пожилых людей более уязвимыми к инфекциям. Кроме того, пожилые люди, страдающие от голодания, более подвержены риску развития хронических заболеваний . Необходимо оказывать помощь тем, кто в ней нуждается.
Причины голодания пожилых людей включают в себя социальные, экономические и личные факторы. Одной из основных причин является финансовая нестабильность . Кроме того, могут быть социально изолированы и не иметь возможности купить еду. Это создает дополнительные проблемы в их жизни .
Решение проблемы голодания пожилых людей требует совместных усилий . Необходимо оказывать экономическую и социальную помощь. Кроме того, важно привлекать внимание властей к этой проблеме. Это может обеспечить им достойную старость.
Влияние голодания на здоровье пожилых людей очень негативно и разнообразно . Голодание делает пожилых людей более восприимчивыми к различным заболеваниям. Кроме того, это может привести к чувству одиночества и безнадежности. Необходимо оказывать медицинскую помощь тем, кто в ней нуждается .
Роль общества в решении проблемы голодания пожилых людей предполагает участие различных секторов и организаций . Общество должно заботиться о пожилых людях и обеспечивать им достойную жизнь . Кроме того, необходимо развивать волонтерское движение и привлекать молодежь к решению этой проблемы . Это может обеспечить им достойную старость.
Проблема голодания пожилых людей требует немедленного внимания и решения . Необходимо принимать меры для предотвращения голодания среди пож??ых людей . Кроме того, необходимо повышать осведомленность о важности решения этой проблемы . Это может обеспечить им достойную старость.
Будущие направления решения проблемы голодания пожилых людей требуют активного участия общества и государства. Необходимо обеспечивать доступ к полноценному питанию и медицинской помощи. Кроме того, необходимо оказывать медицинскую помощь тем, кто в ней нуждается . Это может обеспечить им достойную старость.
buy accutane online without prescription
buy accutane cheap http://sbsmeds.sbs/# buy accutane pills online
Аргументы подкреплены фактами и исследованиями, что позволяет читателям рассмотреть разные стороны вопроса.
sbsmeds
sbsmeds http://sbsmeds.sbs/# buy accutane cheap
buy isotretinoin online
Dive into the world of excitement with Juwa777 and win big!
Customer support is another strong aspect of Juwa 777.
buy accutane no rx https://sbsmeds.sbs/# isotretinoin
May I simply say what a relief to uncover somebody who genuinely knows what they’re talking about on the internet. You actually understand how to bring an issue to light and make it important. A lot more people must read this and understand this side of the story. It’s surprising you aren’t more popular since you certainly possess the gift.
buy accutane no prescription
isotretinoin https://sbsmeds.sbs/# where buy accutane
sbsmeds
sbsmeds https://sbsmeds.sbs/# sbsmeds
sbsmeds
prednisone
purchase prednisone online no prescription https://prednisonepharm.shop/# buy prednisone online
Please let me know if you’re looking for a author for your weblog. You have some really good posts and I think I would be a good asset. If you ever want to take some of the load off, I’d absolutely love to write some content for your blog in exchange for a link back to mine. Please send me an email if interested. Kudos!
prednisonepharm
Для кинотеатров, конференц-залов и домашних кинозалов подойдет экраны для проектора, который можно заказать на сайте.
обязательны для демонстрации фильмов и презентаций. Они способствуют повышению эффективности презентаций. Кроме того, выбор экрана зависит от??ных требований пользователя.
Экраны различаются по материалу и качеству поверхности . Для мероприятий и презентаций в крупных залах существуют уникальные предложения на рынке. Это позволяет найти идеальный экран для конкретных задач.
Экраны для проекторов делятся на несколько основных типов . Это автоматические экраны , которые устанавливаются на стену или потолок . Кроме того, разработаны экраны для фронтальной проекции .
Экраны предназначены для применения в задних проекциях . Они позволяют добиться высокого качества изображения . Это объясняет их широкое применение.
При выборе экрана для проектора необходимо учитывать несколько ключевых факторов . Это тип проектора и его технические характеристики , которые обуславливают выбор материала экрана. Кроме того, необходимо проанализировать стоимость и эксплуатационные расходы .
Экраны должны быть выбраны в соответствии с конкретными потребностями . Это дает возможность оптимизировать процесс демонстрации . Поэтому следует изучить отзывы и рейтинги .
Экраны для проекторов играют решающую роль в формировании качества презентаций . Они должны быть выбраны с учетом всех необходимых факторов . Это обуславливает повышение эффективности презентаций. Поэтому важно обратить внимание на все нюансы выбора экрана .
prednisonepharm https://prednisonepharm.shop/# prednisonepharm
buy deltasone no prescription
prednisonepharm https://prednisonepharm.shop/# prednisonepharm
order deltasone
buy prednisone usa https://prednisonepharm.shop/# buy prednisone with no prescription
Узнайте подробности по стоимость забора из евроштакетника расчет и сделайте правильный выбор.
При заказе больших объемов можно получить скидки от производителей.
Если вам нужна автомобиль с водителем новосибирск, обращайтесь к нам — мы гарантируем комфорт и безопасность на дороге.
Опытные водители позволяют избежать стрессовых ситуаций в дороге и экономят время клиента.
buy generic prednisone
kamagpharm https://kamagpharm.shop/# kamagpharm
buy Kamagra Oral Jelly pills
Hmm is anyone else encountering problems with the images on this blog loading? I’m trying to determine if its a problem on my end or if it’s the blog. Any responses would be greatly appreciated.
kamagpharm https://kamagpharm.shop/# kamagpharm
Kamagra Oral Jelly
kamagpharm https://kamagpharm.shop/# kamagpharm
Try your luck and win big withsurewin download.
To safeguard user data, the casino employs cutting-edge encryption methods.
kamagpharm
Здравствуйте дорогие друзья! Стоит заранее разобрать про устройство плоской кровли. По моему мнению убедился: нужен результат — вот проверенные ребята: монтаж ПВХ кровли. Суть в том, что: крыша без уклона — это не как скатная. Например плохой водоотвод — протечки гарантированы? Соответственно технология нарушена. Можно поставить клиновидный утеплитель, сверху — полимерное покрытие. Опять же высокоэффективный инструмент. Что в итоге: никаких луж и протечек.
buy Kamagra Oral Jelly no prescription https://kamagpharm.shop/# kamagpharm
Try your luck at an online casino spingo88 and enjoy exciting games.
The platform Spingo88 has quickly become a favorite among users worldwide.
Discover new opportunities with v blink, that will change the way you think about communication.
Its interface is user-friendly, providing a smooth experience for beginners.
buy Kamagra Oral Jelly no prescription
Try your luck and win big in slotgpt casino!
Each game is developed by reputable providers ensuring high-quality graphics and sound.
buy Kamagra Oral Jelly cheap https://kamagpharm.shop/# kamagpharm
To create stamps at home or in the office, you can use the serviceonline stamp maker free, позволяющим быстро и качественно создавать необходимые печати без выхода из дома.
With the rise of digital technology, the traditional method of creating rubber stamps has been transformed, allowing users to design and order custom stamps online.
Users can choose from various shapes, sizes, and fonts, and can even upload their own images or logos.
Additionally, a good online stamp maker should offer a range of production options, including materials and shipping methods.
By choosing an online rubber stamp maker, users can stay ahead of the curve and take advantage of the latest technology and trends in stamp making.
kamagpharm
pharmacy online https://mexpharma.shop/# mexica pharmacy online review
reputable online pharmacy
online pharmacy cialis https://mexpharma.shop/# online pharmacy xanax
mexica online pharmacy
mexican online pharmacy reviews https://mexpharma.shop/# viagra online pharmacy
cvs pharmacy online application
pharmacy technician certification online https://mexpharma.shop/# best online pharmacy
online pharmacy without prescription
Immerse yourself in the world of excitement and winnings withcasino valor,where every spin brings pleasure and a chance to win a big jackpot.
Regular patrons appreciate the courteous team members who ensure smooth and pleasant experiences.
online pharmacy xanax https://mexpharma.shop/# mexpharma
online pharmacy school
cvs pharmacy online application https://canpharma.shop/# canpharma
can pharma
canpharma https://canpharma.shop/# canadian online pharmacy reviews
canpharma
cvs pharmacy online https://canpharma.shop/# online pharmacy
can pharma
Check out our new game on alo789, to try your luck and win big prizes!
This platform offers a wide range of games and betting options designed to entertain users of all skill levels.
cialis online pharmacy https://canpharma.shop/# cvs online pharmacy
Hello! cialis online pharmacy great internet site.
La innovadora compania de espectaculos de drones presento un impresionante espectaculo de drones iluminados en el cielo nocturno, cautivando a todos los asistentes con su show de luces con drones.
Los drones han revolucionado la forma en que se entiende el entretenimiento, ofreciendo un espectaculo aereo lleno de color y vida . Estos espectaculos suelen incluir una gran cantidad de drones que vuelan en formaciones precisas y sincronizadas, creando patrones y disenos en el cielo. La cantidad de drones utilizados en estos espectaculos puede variar, pero siempre buscan crear una experiencia visual que leave a las audiencias con la boca abierta. Los organizadores de estos eventos trabajan arduamente para programar y ensayar las rutinas de vuelo, asegurandose de que cada dron se mueva en perfecta sincronia con los demas. Los equipos de programacion y vuelo trabajan en estrecha colaboracion para asegurarse de que cada movimiento sea preciso y cada formacion sea perfecta .
El uso de drones en los espectaculos ha abierto nuevas posibilidades para la expresion artistica y la entretenimiento. Los drones han permitido a los artistas y disenadores explorar nuevas formas de creatividad y expresion en el cielo . Ademas, estos eventos han generado un gran interes entre el publico, que se maravilla con la belleza y la complejidad de los patrones y disenos creados por los drones. Los espectaculos de drones han atraido a audiencias de todas las edades, quienes se quedan asombradas con la tecnologia y la creatividad que se despliega en el cielo .
Tecnica y Seguridad:
La realizacion de un espectaculo de drones requiere una gran cantidad de planificacion y preparacion, especialmente en lo que respecta a la seguridad. Los organizadores de los espectaculos de drones deben considerar una variedad de factores de seguridad, incluyendo la ubicacion del evento, el numero de drones y las condiciones climaticas. Los drones utilizados en estos espectaculos estan equipados con tecnologia avanzada que les permite volar de manera autonoma y realizar maniobras complejas. La tecnologia de vuelo autonomo es crucial para la realizacion de estos espectaculos, ya que permite a los drones realizar movimientos precisos y sincronizados . Ademas, los operadores de los drones deben tener una gran habilidad y experiencia para controlar los drones de manera efectiva. La experiencia y la habilidad de los operadores son fundamentales para el exito de un espectaculo de drones .
La seguridad de los espectadores es tambien una preocupacion importante, ya que los drones vuelan a baja altitud y pueden representar un riesgo si no se manejan correctamente. Los organizadores de los espectaculos de drones deben tomar medidas para garantizar que los espectadores esten a una distancia segura de los drones . Para mitigar este riesgo, los organizadores suelen establecer zonas de seguridad y seguir estrictos protocolos de seguridad. Los equipos de seguridad estan preparados para responder a cualquier incidente que pueda ocurrir durante el espectaculo.
Impacto y Futuro:
El impacto de los espectaculos de drones en la industria del entretenimiento ha sido significativo, abriendo nuevas posibilidades para la creatividad y la innovacion. Los espectaculos de drones han revolucionado la forma en que se entiende el entretenimiento, ofreciendo una experiencia visual unica y emocionante . Ademas, estos eventos han generado un gran interes entre el publico, que se maravilla con la belleza y la complejidad de los patrones y disenos creados por los drones. El publico ha respondido con entusiasmo a los espectaculos de drones, disfrutando de la emocion y la belleza de estos eventos . En el futuro, se espera que la tecnologia de drones siga evolucionando, permitiendo la creacion de espectaculos aun mas complejos y emocionantes. La tecnologia de drones seguira avanzando en el futuro, lo que permitira la creacion de espectaculos aereos aun mas impresionantes y emocionantes .
Los espectaculos de drones tambien tienen el potencial de ser utilizados en una variedad de contextos, desde eventos culturales hasta espectaculos de entretenimiento. Los espectaculos de drones pueden ser utilizados en una variedad de contextos, desde eventos culturales hasta espectaculos de entretenimiento . Ademas, la tecnologia de drones puede ser utilizada para promover la conciencia y la educacion sobre temas importantes, como la conservacion del medio ambiente y la seguridad. La tecnologia de drones puede ser utilizada para crear experiencias de aprendizaje interactivas y emocionantes que promuevan la conciencia y la educacion.
Conclusion:
En conclusion, los espectaculos de drones son una forma de entretenimiento emocionante y innovadora que combina la tecnologia y la creatividad para ofrecer una experiencia visual unica. La tecnologia de drones ha permitido la creacion de espectaculos aereos que deslumbran a las audiencias con su precision y belleza . Estos eventos han generado un gran interes entre el publico y han abierto nuevas posibilidades para la creatividad y la innovacion en la industria del entretenimiento. Los espectaculos de drones han atraido a audiencias de todas las edades, quienes se quedan asombradas con la tecnologia y la creatividad que se despliega en el cielo . En el futuro, se espera que la tecnologia de drones siga evolucionando, permitiendo la creacion de espectaculos aun mas complejos y emocionantes. La tecnologia de drones seguira avanzando en el futuro, lo que permitira la creacion de espectaculos aereos aun mas impresionantes y emocionantes .
Los espectaculos de drones tienen el potencial de ser utilizados en una variedad de contextos, desde eventos culturales hasta espectaculos de entretenimiento. Los espectaculos de drones pueden ser utilizados en una variedad de contextos, desde eventos culturales hasta espectaculos de entretenimiento . Ademas, la tecnologia de drones puede ser utilizada para promover la conciencia y la educacion sobre temas importantes, como la conservacion del medio ambiente y la seguridad. La tecnologia de drones puede ser utilizada para promover la conciencia y la educacion sobre temas importantes, como la conservacion del medio ambiente y la seguridad .
Immerse yourself in an exciting world show drones, where technology and art merge in an incredible spectacle.
As technology advances, drone shows are poised to offer increasingly captivating and novel experiences to global viewers.
canpharma
online canadian pharmacy https://canpharma.shop/# legitimate online pharmacy
can pharma
canpharma https://canpharma.shop/# canadian pharmacies online
reliable online pharmacy
canpharma https://canpharma.shop/# indian pharmacy online
legit online pharmacy
online pharmacy no prescription https://canpharma.shop/# can pharma
online canadian pharmacy
wake rx net
generic accutane https://wakerxnet.top/# buy isotretinoin no prescription
Обеспечьте соответствие вашего школьного спортзала стандартам ФГОС, выбрав подходящее спортивное оборудование для детского сада на сайте myvoleybol.ru для создания безопасной и эффективной среды для занятий.
Подобные шаги подтверждают полное соответствие официальным стандартам
accutane cheap
Если вы ищете готовые решения для строительства своего жилища, посетите наш сайт по адресу готовые проекты коттеджей, чтобы найти подходящий для вас проект.
предлагают заказчикам широкий спектр возможностей для строительства . Эти проекты дают возможность избежать лишних расходов и ошибок . Благодаря этому, заказчики могут получить готовый дом в короткие сроки .
Готовые проекты домов созданы с учетом всех современных требований и стандартов . Они предоставляют заказчикам возможность осуществлять контроль над строительным процессом. Это упрощает процесс строительства и снижает риски .
Готовые проекты домов позволяют сэкономить средства и время . Они предоставляют заказчикам возможность осуществлять контроль над строительным процессом. Благодаря этому, заказчики могут приступить к строительству сразу после покупки проекта .
Готовые проекты домов разработаны с учетом всех современных требований и стандартов . Они позволяют заказчикам получить высококачественный дом . Это дает заказчикам возможность получить готовый дом в короткие сроки .
Готовые проекты домов представляют собой комплексное решение для строительства жилья . Они созданы с учетом всех современных требований и стандартов . Благодаря этому, заказчики могут ch?nать из широкого спектра проектов .
Готовые проекты домов дают возможность избежать лишних расходов и ошибок . Они содержат полное описание всех этапов строительства . Это дает заказчикам возможность получить готовый дом в короткие сроки .
Готовые проекты домов включают в себя полный набор документации для создания нового дома . Они разработаны опытными архитекторами и инженерами . Благодаря этому, заказчики могут сэкономить время и ресурсы .
Готовые проекты домов позволяют заказчикам получить готовый дом в короткие сроки . Они включают в себя подробную документацию и чертежи . Это упрощает процесс строительства и снижает риски .
wake rx net https://wakerxnet.top/# accutane generic
generic accutane
buy accutane online https://wakerxnet.top/# buy accutane cheap
wake rx net
Ahaa, its fastidious discussion concerning this paragraph at this place at this webpage, I have read all that, so now me also commenting at this place.
propeciarxnet https://propeciarxnet.top/# propeciarxnet
propecia rx net
Автор представил широкий спектр мнений на эту проблему, что позволяет читателям самостоятельно сформировать свое собственное мнение. Полезное чтение для тех, кто интересуется данной темой.
propeciarxnet https://propeciarxnet.top/# buy proscar 5 mg
propeciarxnet
Очень понятная и информативная статья! Автор сумел объяснить сложные понятия простым и доступным языком, что помогло мне лучше усвоить материал. Огромное спасибо за такое ясное изложение! Это сообщение отправлено с сайта https://ru.gototop.ee/
propecia rx net https://propeciarxnet.top/# purchase finasteride
propeciarxnet
propeciarxnet https://propeciarxnet.top/# propecia rx net
buy proscar pills
order finasteride https://propeciarxnet.top/# buy proscar online
Я ценю балансировку автора в описании проблемы. Он предлагает читателю достаточно аргументов и контекста для формирования собственного мнения, не внушая определенную точку зрения.
buy finasteride pills
Discover the exciting world of gambling on 777bet casino, where every spin can be a winner!
Ultimately, for fans of online betting, 777bet emerges as a trustworthy platform.
Hello pals!
I came across a 149 awesome page that I think you should explore.
This platform is packed with a lot of useful information that you might find interesting.
It has everything you could possibly need, so be sure to give it a visit!
https://www.hindiyaro.com/tonybet-a-premier-wagering-platform-for-discerning-punters/
Additionally don’t overlook, everyone, which you at all times are able to in this particular publication find answers to the the absolute tangled questions. We tried — lay out all content via an very easy-to-grasp method.
canada drugs online review https://livemedsrx.top/# livemedsrx
livemedsrx
livemedsrx https://livemedsrx.top/# canadian pharmacy
livemedsrx
Для строительства или ремонта дома стоит выбрать качественный кирпич ручной формовки купить, который прослужит долгие годы и придаст вашему дому уникальный внешний вид.
является исключительно популярным материалом для строительных работ . Этот тип кирпича производится без использования машин, благодаря чему кирпичи приобретают индивидуальность . Кирпич ручной формовки является универсальным материалом, подходящим для любых строительных проектов.
Кирпич ручной формовки имеет ряд преимуществ, включая морозостойкость и устойчивость к деформациям . Процесс производства кирпича ручной формовки предполагает использование натуральных материалов и традиционных технологий. Кирпич ручной формовки получил широкое распространение в различных регионах мира .
Кирпич ручной формовки характеризуется высокой прочностью и устойчивостью к нагрузкам . Этот материал используется для возведения стен, фундаментов и других конструктивных элементов . Кирпич ручной формовки может быть использован для создания уникальных архитектурных элементов.
Кирпич ручной формовки производится без применения вредных химических веществ. Этот тип кирпича может быть использован для создания энергосберегающих зданий . Кирпич ручной формовки используется для возведения стен, фундаментов и других конструктивных элементов .
Кирпич ручной формовки обладает высокой прочностью и устойчивостью к нагрузкам. Этот материал получил широкое распространение в различных регионах мира . Кирпич ручной формовки может быть использован для создания уникальных архитектурных элементов.
Кирпич ручной формовки используется для возведения стен, фундаментов и других конструктивных элементов . Этот тип кирпича может быть использован для создания энергосберегающих зданий . Кирпич ручной формовки производится без применения вредных химических веществ.
Кирпич ручной формовки является уникальным и универсальным материалом, подходящим для любых строительных проектов . Этот тип кирпича имеет высокую степень звукоизоляции, что делает его подходящим для строительства объектов с высокой степенью шумозащиты. Кирпич ручной формовки может быть использован для создания уникальных архитектурных элементов.
Кирпич ручной формовки включает в себя использование глины и других природных компонентов . Этот материал используется в строительстве зданий, требующих высокой степени безопасности . Кирпич ручной формовки обладает высокой тепловой массой, что позволяет ему аккумулировать и отдавать тепло .
Для обеспечения контроля доступа на мероприятиях рекомендуем использовать браслеты пропускные на руку, которые обеспечивают удобство и надежность.
Бумажные браслеты экологичны и безопасны для кожи
livemedsrx https://livemedsrx.top/# online pharmacy school
Памятка как не попасться на уловки мошенников https://ne-popadis.org/
livemedsrx
livemedsrx https://livemedsrx.top/# humana online pharmacy
buying drugs from canada
livemedsrx https://livemedsrx.top/# canadian pharmacy reviews
online pet pharmacy
livemedsrx https://livemedsrx.top/# online pharmacy school
livemedsrx
http://images.google.ki/url?q=https://t.me/s/officials_7k/669
livemedsrx https://livemedsrx.top/# canada drugs laws
livemedsrx
livemedsrx https://livemedsrx.top/# livemedsrx
fastmedsrx
fastmedsrx https://fasteasymeds.top/# fastmedsrx
buy drugs from canada
Если вас интересует кератоконус что это, это заболевание характеризуется прогрессирующей деформацией роговицы глаза, что может существенно нарушить качество зрения.
Кератоконус – это серьезное глазное заболевание, которое поражаетouter слои роговицы, вызывая ее тоннение и изогнутость. Это заболевание может привести к значительному снижению зрения и требует тщательного лечения. В большинстве случаев кератоконус развивается у молодых людей, имеющих слабую роговицу. Симптомы могут включать размытое зрение, чувствительность к свету и снижение зрения при ночной езде.
Кератоконус – это состояние, при котором роговица становится тонкой и изогнутой, приводя к проблемам со зрением. Ранняя диагностика имеет решающее значение для эффективного лечения. Если кератоконус не лечить, он может привести к значительному ухудшению зрения и даже слепоте. Регулярные осмотры у офтальмолога помогают обнаружить заболевание на ранней стадии.
Кератоконус thu?ng??ается в виде постепенного ухудшения зрения, которое не может быть исправлено с помощью корректирующих линз. Диагностика кератоконуса включает в себя ряд специальных тестов. Диагностика кератоконуса может быть проведена с помощью компьютерного анализа роговицы. Ранняя диагностика позволяет начать лечение и предотвратить дальнейшее ухудшение зрения.
Кератоконус может быть диагностирован с помощью неинвазивных методов, таких как сканирование роговицы. Тщательная диагностика имеет решающее значение для определения степени кератоконуса и выбора оптимального лечения. Кератоконус может быть лечен с помощью трансплантации роговицы или фототерапевтических методов. Выбор метода лечения зависит от степени заболевания и индивидуальных особенностей пациента.
Кератоконус может быть лечен с помощью различных нехирургических и хирургических методов. Одним из наиболее эффективных методов лечения является ношение газопроницаемых контактных линз. Газопроницаемые линзы могут улучшить остроту зрения и снизить симптомы кератоконуса. Кроме того, могут быть применены хирургические методы, такие как имплантация коллагеновых кольцеобразных секций или трансплантация роговицы.
Кератоконус может быть лечен с помощью лазерной коррекции зрения или других современных хирургических методов. Целью лечения является достижение лучшего качества зрения и предотвращение дальнейшего прогрессирования заболевания. Регулярные осмотры у офтальмолога имеют решающее значение для контроля за состоянием роговицы и коррекции методов лечения. Своевременная коррекция методов лечения может помочь достичь лучших результатов и поддержать здоровье роговицы.
Кератоконус имеет различные прогнозы, в зависимости от индивидуальных особенностей и методов лечения. В большинстве случаев, кератоконус можно эффективно лечить и улучшать качество зрения. Методы лечения кератоконуса постоянно совершенствуются, что позволяет добиться лучших результатов. Однако, важно помнить, что кератоконус – это хроническое заболевание, которое требует постоянного мониторинга и коррекции методов лечения.
Пациенты с кератоконусом должны быть осведомлены о важности регулярных осмотров для поддержания здоровья роговицы. Кроме того, пациентам рекомендуется соблюдать все рекомендации офтальмолога и использовать назначенные методы лечения. Соблюдение плана лечения имеет решающее значение для достижения лучших результатов и поддержания здоровья роговицы. Своевременная диагностика, эффективное лечение и постоянный мониторинг могут помочь пациентам с кератоконусом улучшить качество жизни и сохранить здоровье роговицы.
canadian pharmacy review https://fasteasymeds.top/# canada online pharmacy
Если вы ищите надежную рейтинг клиник лазерной коррекции зрения москва, обратите внимание на передовые технологии и доступные цены в нашей клинике.
Пациенты фиксируют благоприятные перемены после вмешательств.
I recently have been looking into seasonal color analysis and encountered different palettes like deep summer, light spring, and soft autumn, which actually help in identifying which colors suit different skin tones such as amber, olive, and warm beige. Using resources like the Color Analysis Pro app or taking a cost-free color analysis quiz online can grant you a better idea of your season, whether it’s deep summer colors or a cool winter color palette.
If you’re wondering about your skin tone color and want to try virtual hair color try-ons or find the top colors for pale skin or yellow undertone skin, there are plenty of resources ready to test. For those keen on detailed charts or wanting to cancel their Color Analysis Pro subscription, you can receive more information and support here skin tones . Seasonal color analysis certainly makes deciding on clothing colors for your skin tone substantially easier!
cvs online pharmacy
fastmedsrx https://fasteasymeds.top/# fastmedsrx
online pharmacy india
fastmedsrx https://fasteasymeds.top/# mail order prescription drugs from canada
reputable canadian pharmacy
online pharmacy viagra https://fasteasymeds.top/# fastmedsrx
fastmedsrx
В том случае если вы готовитесь к поездку на Канары, особенно на Тенерифе, рекомендуется заранее разобраться, что осмотреть на Тенерифе и какие точки интереса действительно вызывают внимания. Так, парк Monkey Park Tenerife и плавательные зоны Lago Martianez в Пуэрто де ла Крус – замечательные места для отдыха с семьёй. Не пропустите посетить пляж Тереситас и популярное драконовое дерево, а для любителей активного отдыха необходимой будет информация о направлении bus tenerife и расписании teneriffa bus 343 fahrplan.
Вдобавок, если важно, как подготовить поездку на Карнавальное событие на Тенерифе 2025 года (carnevale tenerife 2025, karnawał na teneryfie 2025), советую посмотреть программу programme carnaval tenerife 2025 и вспомогательные советы по передвижению и экскурсиям. Для простоты ориентирования на карте канарских островов и поиска маршрутов послужит полезным этот сайт: пуэнте-нуэво . Помимо этого стоит приглядеться на погоду, так, погода на Тенерифе в позднюю осень и март, чтобы надёжнее подготовиться к турне.
best prices on finasteride in mexico https://joeasymeds.top/# joeasy meds
trusted mexico pharmacy with us shipping
joeasy meds https://joeasymeds.top/# best online pharmacies in mexico
buy cheap meds from a mexican pharmacy
viagra pills from mexico https://joeasymeds.top/# joeasy meds
Коли вы интересуетесь аэропортами в всевозможных странах, таких как Филиппины, Дания, или даже Зимбабве, рекомендуется принимать во внимание, что непересадочные рейсы из таких хабов как Стамбул или Прага существенно делают удобнее перелеты по Европе и другим регионам. Так, из Еревана представлены прямые рейсы в Европу, а из Москвы зачастую можно выбрать самые экономичные билеты, плюс last minute предложения. Для удобства планирования путешествия стоит посмотреть исчерпывающий список аэропортов и рейсов на сколько аэропортов в англии , где собрана информация по аэропортам США, Польши, ОАЭ и других распространенных направлений.
В частности важно для тех, кто находит маршруты из менее стандартных точек вылета, к примеру, дешевые авиабилеты из Минска, Вроцлава или даже Душанбе. Аэропорты в странах как Албания, Нидерланды или Швеция открывают обилие вариантов перелетов, в том числе лоукосты. Помимо этого, не упускайте про такие необычные направления, как аэропорты Гренландии, Доминиканы или Багам, которые могут стать хорошим вариантом для отпуска. Коли намереваетесь выяснить, в каких направлениях можно по низкой цене улететь из Москвы или Стамбула, а также о прямых рейсах из Анталии в Европу, загляните на сайт и подберите лучший для вас вариант.
joeasy meds
joeasy meds https://joeasymeds.top/# joeasy meds
joeasy meds
trusted mexican pharmacy https://joeasymeds.top/# legit mexican pharmacy without prescription
amoxicillin mexico online pharmacy
joeasy meds https://joeasymeds.top/# prescription drugs mexico pharmacy
В том случае если вы планируете тур в Таиланд и хотите определиться, когда лучше ехать в Таиланд Пхукет, стоит брать в расчет сезонность: сезон дождей сезон длится с мая по октябрь, а лучшие пляжные условия в основном с ноября по февраль. Для передвижений между Пхукетом и Самуи удобно использовать морское сообщение, а также есть методы трансфера на машине или taxi — расстояние и время в пути определяются от выбранного способа, конкретнее как добраться из Пхукета на Самуи можно ознакомиться тут цунами 2004 пхукет .
При составлении бюджета также важно знать, сколько взять денег в Таиланд на 10 дней, учитывая аренду байков (в большинстве случаев без прав не разрешают), экскурсии на Пхукете и визиты в массажных салонов, а также отведать экзотические фрукты Таиланда, период созревания которых разнится по месяцам. Приверженцам пляжного отдыха рекомендую обратить внимание на отличные пляжи Самуи с белым песком и путешествия на Патонге, а для умиротворенного отдыха — карты Тайланда с пляжами и рекомендации по безопасности всегда позволят ориентироваться увереннее.
Откройте для себя многофункциональный кроссовер спортивный тренажер, который идеально подойдет для интенсивных тренировок в зале или дома.
Начинайте с мягкой подготовки
Если вы ищете выгодные варианты установка откосов из сэндвич панелей цена, то профессиональный монтаж под ключ сделает ваш дом уютнее и теплее.
Они защищают конструкцию от внешних факторов и улучшают интерьер. Сэндвич-панели представляют собой многослойный материал. Такие панели включают изоляционный слой и внешнее покрытие Установка откосов из сэндвич-панелей популярна благодаря своей простоте. Это позволяет добиться быстрого монтажа без лишних усилий
Откосы помогают в сохранении тепла в помещении. Без них окна могут пропускать холод и влагу Сэндвич-панели отличаются высокой прочностью. Такие материалы устойчивы к износу и сохраняют форму Это делает их идеальным выбором для современных ремонтов. Такие панели сочетают практичность с доступной ценой
Сэндвич-панели обеспечивают отличную теплоизоляцию. Их структура предотвращает проникновение холода в комнату. Материал устойчив к влаге и грибку. Такая устойчивость продлевает срок эксплуатации без ремонта Эстетика панелей добавляет шарма интерьеру. Панели улучшают общий вид помещения за счет своей привлекательности.
Установка сэндвич-панелей экономит время. Это позволяет завершить работы за короткий срок Стоимость материалов остается доступной. Цена на них остается конкурентной на рынке. Это делает их популярным решением для ремонта. Выбор панелей оправдан их надежностью и выгодой.
Сначала подготавливается поверхность откоса. Эта стадия включает очистку и выравнивание основания Затем нарезаются панели по требуемым размерам. Подготовленные панели упрощают дальнейший монтаж. После этого они фиксируются с помощью крепежа. Это гарантирует стабильность конструкции на длительный период
Важно использовать качественные инструменты. Это минимизирует риск ошибок во время работы Финальный этап включает отделку швов. Отделка предотвращает проникновение пыли и холодного воздуха Такой подход обеспечивает долговечность. Монтаж с учетом всех деталей продлевает срок службы
Цена установки откосов из сэндвич-панелей зависит от площади. Площадь определяет количество материалов и трудозатрат В среднем, стоимость начинается от 500 рублей за квадратный метр. Средняя цифра варьируется в зависимости от региона Дополнительные факторы повышают итоговую цену. Влияние факторов делает расчет индивидуальным
Региональные различия влияют на ценообразование. Региональные особенности определяют конечную стоимость. Рекомендуется сравнивать предложения. Анализ цен ensures выгодное решение для клиента. В итоге, установка окупается за счет долговечности. Экономия на отоплении компенсирует затраты
mexicare meds https://mexicaremeds.com/# mexicare meds
mexico pharmacy
mexicare meds https://mexicaremeds.com/# mexicare meds
low cost mexico pharmacy online
Если вы ищете прямые рейсы из Еревана в Европу или недорогие билеты из Москвы за границу, имеет смысл обратить внимание на бюджетные перевозчики, дающие хорошие цены. Например же, аэропорты Польши, Чехии и Болгарии постоянно осуществляют экономичные направления, а из Ташкента равным образом есть удобные прямые рейсы в Европу. Для подбора самых бюджетных вариантов и скидочных билетов из Москвы, Праги, Берлина или Анталии стоит воспользоваться проверенными сервисами поиска авиабилетов прямые рейсы из еревана .
Вдобавок, аэропорты Израиля, Норвегии, Португалии и Албании продолжают развивать список направлений, что намного помогает турпоездки. Куда экономно слетать из Москвы или куда существуют прямые рейсы из Тель-Авива – похожие темы часто обсуждаются на форумах о путешествиях. Тщательно следите за бюджетными предложениями и временными акциями, чтобы получить максимально дешевые билеты в предпочитаемые страны, включая Новая Зеландия, Литва или Черногория.
Я рад, что наткнулся на эту статью. Она содержит уникальные идеи и интересные точки зрения, которые позволяют глубже понять рассматриваемую тему. Очень познавательно и вдохновляюще!
mexicare meds https://mexicaremeds.com/# mexicare meds
Heya i’m for the primary time here. I came across this board and I find It really helpful & it helped me out much. I hope to offer one thing back and help others like you aided me.
purple pharmacy mexico price list
mexican online pharmacies prescription drugs https://mexicaremeds.com/# mexican border pharmacies shipping to usa
mexicare meds
mexico pharmacy https://mexicaremeds.com/# mexicare meds
Hi! mexican online pharmacies prescription drugs excellent web site.
Howdy! I understand this is somewhat off-topic however I needed to ask. Does building a well-established blog like yours take a lot of work? I’m completely new to operating a blog however I do write in my diary daily. I’d like to start a blog so I will be able to share my personal experience and feelings online. Please let me know if you have any ideas or tips for brand new aspiring bloggers. Appreciate it!
mexica pharmacy online review
Надеюсь, вам понравятся и эти комментарии! Это сообщение отправлено с сайта GoToTop.ee
pharmacy online https://mexbajapharm.top/# cheap online pharmacy
Полезная информация для тех, кто стремится получить всестороннее представление.
Try your hand at online games on 125win slot and win big prizes!
This commitment builds trust between the platform and its customers.
Discover the best slot machines with mrlucky88 slot.
What sets mrlucky88 apart is a distinctive approach to gaming.
777 bet online casino and dive into the world of gambling with unique offers!
At 777bet, the focus on user experience is evident in how intuitive the platform is.
Hello, I do think your website could possibly be having web browser compatibility issues. Whenever I look at your website in Safari, it looks fine however when opening in IE, it’s got some overlapping issues. I just wanted to provide you with a quick heads up! Besides that, wonderful site!
Здравствуйте дорогие друзья! Сегодня затронем тему — гул в салоне. Нужен профессиональный результат — могу рекомендовать специалистам: сервис шумоизоляции . Суть в том, что обработать только арки — это полдела. Как правило основные резонаторы — двери и колёсные ниши. Зачем это? По гравийке оцениваешь откуда идёт звук. Опять же, хочешь своими силами: готовишь, наносишь демпфер, прикатываешь тщательно. Резюмируем: эффект гарантирован.
В том случае если вы организуете поездку в Таиланд, стоит заранее понять, какой остров определить — Пхукет или Самуи. Самуи известен своими прекрасными пляжами, и на карте Таиланда элементарно найти первоклассные пляжи Самуи, которые превосходно подойдут для спокойного отдыха. Для тех, кто следит за историей, важно вспомнить про цунами в Таиланде 2004 года: на Пхукете и Самуи до настоящего времени можно найти фото и рассказы, посвящённые с этим событием.
При сборах к поездке призываю изучить темы обмена валюты на Пхукете и сколько денег запланировать в Таиланд на 10 дней, а также ознакомиться с правила въезда в страну в 2025 году. Для туристов будет востребована информация об аренде байка на Пхукете — это выгодный способ путешествия. Данные, включая карту Таиланда с островами и советы по маршрутам, можно посмотреть здесь путевки в тайланд .
Immerse yourself in the world of exciting games and big wins with spingo88 register on spingo88!
These incentives not only attract new players but also retain the existing ones.
Try your luck with jilispin and win a big prize today!
The platform leverages cutting-edge technology to provide instant feedback and reduce waiting times.
Hi! online pharmacy forum beneficial internet site.
Hello folks!
I came across a 149 great site that I think you should browse.
This resource is packed with a lot of useful information that you might find helpful.
It has everything you could possibly need, so be sure to give it a visit!
https://mygardenandpatio.com/nfts-beyond-art-music-gaming-and-beyond/
Furthermore remember not to forget, folks, which you constantly can in the article discover responses to address the most the absolute confusing inquiries. The authors tried — explain the complete data in the most easy-to-grasp way.
Now I am ready to do my breakfast, once having my breakfast coming again to read additional news.
Если вам нужно купить пластиковую тару оптом для ваших товаров, обратите внимание на различные варианты, доступные на рынке, и выбирайте то, что лучше всего соответствует потребностям вашего бизнеса.
Флакон опт представляет собой экономичную и практичную упаковку для жидких товаров . Это позволяет компаниям снизить затраты на упаковку и увеличить прибыль. Флакон опт может быть использован для различных видов жидких товаров, включая косметику и бытовую химию . Кроме того, флакон опт может быть легко транспортирован и хранен.
Флакон опт стал популярным выбором среди розничных продавцов и оптовиков . Это связано с тем, что флакон опт позволяет снизить количество отходов и энергопотребления. Флакон опт защищает продукты от солнечного света и влаги. Кроме того, флакон опт может быть легко заполнен и закрыт.
Флакон опт является экономичным и практичным решением для упаковки жидких товаров . Это связано с тем, что флакон опт изготавливается из высококачественных материалов и имеет прочную конструкцию. Флакон опт также может быть легко персонализирован и брендирован . Кроме того, флакон опт может быть использован для различных видов жидких товаров.
Флакон опт является экологически чистым вариантом для упаковки жидких товаров. Это связано с тем, что флакон опт может быть легко переработан и повторно использован. Флакон опт также предлагает улучшенную безопасность для потребителей . Кроме того, флакон опт может быть легко транспортирован и хранен.
Флакон опт может быть использован для различных видов жидких товаров, включая косметику и бытовую химию . Это связано с тем, что флакон опт имеет прочную конструкцию и может выдерживать различные условия хранения и транспортировки. Флакон опт обеспечивает безопасное и надежное хранение жидких товаров . Кроме того, флакон опт может быть легко заполнен и закрыт.
Флакон опт является предпочтительным вариантом для бизнеса, занимающегося жидкими товарами. Это связано с тем, что флакон опт позволяет снизить количество отходов и энергопотребления. Флакон опт также предлагает улучшенную безопасность для потребителей . Кроме того, флакон опт может быть легко транспортирован и хранен.
Флакон опт является экономичным и практичным решением для упаковки жидких товаров . Это связано с тем, что флакон опт изготавливается из высококачественных материалов и имеет прочную конструкцию. Флакон опт также может быть легко персонализирован и брендирован . Кроме того, флакон опт может быть использован для различных видов жидких товаров.
Флакон опт является предпочтительным вариантом для бизнеса, занимающегося жидкими товарами. Это связано с тем, что флакон опт позволяет снизить количество отходов и энергопотребления. Флакон опт защищает продукты от внешних факторов.
В случае если вы намечаете поездку в Потсдам и не понимаете, что посетить за один день, точно загляните в такие места, как Голландский квартал Потсдам, Дворец Глиникке и Сан-Суси. Для ценителей природы и тишины превосходным выбором станут парки Германии – прежде всего японский сад в Дюссельдорфе или Лихтенхайнский водопад. Тем, кто отдает предпочтение более энергичный отдых, следует посетить Фантазия Ленд: там масса интересных аттракционов и есть возможность заранее приобрести билеты онлайн, чтобы не попасть в очередей берлинский замок .
Если вдруг очутитесь в Дюссельдорфе, не проигнорируйте блошиную базар с ее необычными находками – адрес не составит труда найти, а атмосфера действительно потрясающая. А для почитателей немецкой истории и архитектуры рекомендуются экскурсии на немецкие фабрики и поездка в таких замков, как Берлинский замок или крепость Кёнигштайн. Отметим, если занимает где приобрести пиво в Берлине или отведать баварские продукты, здесь также не возникает проблем – города изобилуют на аппетитные предложения и уютные рынки.
Посетите магазин детских велосипедов сегодня и найдите велосипед своей мечты!
Магазин велосипедов является местом, где можно найти широкий выбор велосипедов для любого возраста и уровня подготовки . Это место, где покупатели могут найти не только велосипеды, но и различные аксессуары и оборудование для них. Магазин велосипедов открыт для посетителей в любое время и приглашает всех любителей велосипедов к себе .
Магазин велосипедов предлагает бесплатную консультацию по выбору велосипеда для каждого клиента. Клиенты могут попробовать велосипеды перед покупкой, чтобы убедиться, что они подходят им идеально. Магазин велосипедов предлагает услуги по модернизации и кастомизации велосипедов.
Магазин велосипедов имеет разнообразный ассортимент велосипедов, включая горные, шоссейные и городские модели . Каждая модель имеет свои уникальные характеристики и особенности. Магазин велосипедов имеет большой sklad с запасами и может быстро удовлетворять заказы клиентов.
Магазин велосипедов также предлагает широкий выбор аксессуаров и оборудования для велосипедов, включая шлемы, перчатки и одежду . Клиенты могут найти все, что им нужно для комфортного и безопасного?жения. Магазин велосипедов имеет программу лояльности для постоянных клиентов .
Магазин велосипедов использует только оригинальные запчасти и высококачественное оборудование. Клиенты могут быть уверены в высоком качестве выполненных работ. Магазин велосипедов также предоставляет услуги по заказу и поставке запчастей и аксессуаров .
Магазин велосипедов регулярно проводит мастер-классы и семинары по темам, связанным с велоспортом и техникой?жения . Клиенты могут получить новые знания и навыки, что позволит им улучшить свое?жение. Магазин велосипедов участвует в организации велосоревнований и поддерживает местный велоспорт.
Магазин велосипедов предлагает всестороннюю услугу по подбору и обслуживанию велосипедов . Клиенты могут найти все, что им нужно для комфортного и безопасного?жения. Магазин велосипедов всегда готов помочь и предоставить консультацию по любым вопросам.
Магазин велосипедов предлагает выгодные цены и акции, что позволяет клиентам приобретать продукцию по доступным ценам . Клиенты могут быть уверены в высоком качестве продукции и услуг. Магазин велосипедов всегда готов к инновациям и улучшению своей работы.
Try your luck in jili spin casino and enjoy exciting slots from Jili!
Moreover, Jili Spin ensures compatibility across devices like smartphones and laptops.
I am extremely impressed with your writing skills and also with the layout on your weblog. Is this a paid theme or did you customize it yourself? Anyway keep up the nice quality writing, it’s rare to see a nice blog like this one these days..
Если вы планируете поездку в Италию, непременно обратите внимание на сельский туризм в Тоскане — это отличный способ узнать больше с культурой и природой региона. Агротуризм Италия Тоскана предлагает не только отдых на свежем воздухе, но и вкуснейшую местную кухню, а помимо этого, рядом много интересных мест, которые следует посетить.
Для тех, кто желает увидеть Италию более тщательно, советую маршрут по Венеции на 1 день: с посещением важнейших достопримечательностей и возможностью покататься на гондоле — цена относительно доступная. Если занимаетесь шопингом, отзывы об аутлете The Mall во Флоренции смогут помочь определиться с выбором. Узнать больше о поездках и маршрутах изучайте здесь неаполь сорренто .
Visit 77bet online casino and dive into the world of gambling with unique offers!
Users can find a mix of classic slots and innovative video slots featuring captivating graphics.
There’s noticeably a bundle to know about this. I assume you made certain good factors in options also.
It’s hard to find knowledgeable people on this topic, but you sound like you know what you’re talking about! Thanks
Для крупных строительных проектов оптимальным решением будет приобретение щебень известняковый 5 20 цена за куб, что позволит сэкономить средства и обеспечить необходимое качество строительных работ.
Щебень из известняка является ключевым компонентом многих строительных смесей. Этот материал характеризуется улучшенными эксплуатационными характеристиками . Оптовая покупка известнякового щебня является выгодной для крупных строительных проектов .
Известняковый щебень в больших количествах позволяет реализовывать масштабные проекты . Оптовая продажа известнякового щебня осуществляется через официальные дилерские сети .
Основными преимуществами известнякового щебня являются его долговечность и экологичность . Известняковый щебень характеризуется улучшенными физико-механическими свойствами . Оптовая покупка известнякового щебня позволяет получить скидки и экономить средства .
Известняковый щебень, купленный оптом, используется для дорожного строительства. Оптовая продажа известнякового щебня способствует увеличению скорости строительства .
Щебень из известняка применяется в производстве асфальтобетона и бетонных смесей . Щебень из известняка может быть использован в ландшафтном дизайне . Приобретение оптом известнякового щебня дает возможность получить щебень для реализации индивидуальных проектов .
Известняковый щебень, купленный оптом, может быть хранен на специализированных складах. Купить щебень известняковый оптом можно через официальные интернет-ресурсы .
Известняковый щебень является востребованным материалом. Оптовая покупка известнякового щебня является выгодной для крупных строительных компаний . Известняковый щебень, купленный оптом, может быть использован для реализации инфраструктурных проектов.
Щебень известняковый, купленный оптом, может быть доставлен в любую точку страны . Оптовая покупка известнякового щебня позволяет получитьraw материал для различных целей .
Your writing always captivates your audience with its insightful take on current events and uplifting stories. It would be amazing to see you examine how these ideas might impact emerging trends, such as artificial intelligence or sustainable living. Your knack for clarifying intricate subjects is remarkable. Thanks for continually delivering such enlightening content. looking forward to your upcoming posts!
Information: https://chatgptaguide.com/chatgpt-optimizing-language-models-for-dialogue/
chat gpt бесплатно
Dead written content material, thank you for entropy. “You can do very little with faith, but you can do nothing without it.” by Samuel Butler.
В случае планирования тур в Италию, советую обратить взор на агротуризм в Тоскане – это отличный способ наслаждаться ландшафтами и местной итальянской кухней. Крайне интересен агротуризм Италия Тоскана, где имеется шанс оказаться на фермах, продегустировать вино и осмотреть термы Тоскана. Для фанатов активных развлечений подходит маршрут по Доломитовым Альпам на машине или путешествие по амальфитанскому побережью на машине, а если желаете культурного досуга, не забудьте про маршрут по Венеции за 1 день с точной картой на сайте из неаполя на капри .
Также, для поклонников шопинга Флоренция имеет отличные аутлеты во Флоренции, среди которых The Mall – о них регулярно положительные отзывы. Если желаете посетить Венецию, важно знать стоимость гондолы в Венеции и как прибыть до интересных объектов, скажем, таких как Святой лестницы или римских императорских форумов в Риме. А если турируете с детьми, есть огромное число маршрутов, которые отлично подойдут для отдыха с семьей, например, экскурсии из Неаполя в Помпеи или тур на паром из Неаполя на Капри.
Если вы ищете качественные и стильные устройства для vaping, то вейп hqd купить может стать вашим лучшим выбором, предлагая широкий выбор товаров и услуг по vaping, включая одноразовые устройства, различные вкусы и аксессуары.
Они представляют собой высококачественные устройства для vaping, созданные компанией HQD . Эти устройства очень удобны в использовании Они уже готовы к использованию прямо из коробки . HQD одноразки также очень безопасны Они изготовлены из высококачественных материалов .
HQD одноразки имеют широкий выбор вкусов Вкусы варьируются от классических табачных до экзотических фруктовых . Эти устройства также очень компактны Они не занимают много места . HQD одноразки идеально подходят для тех, кто хочет попробовать вейпинг Они не требуют никакого опыта или знаний .
HQD одноразки имеют много преимуществ Они не требуют никакого обслуживания или настройки . Эти устройства также очень эффективны Они очень экономичны. HQD одноразки также очень безопасны Поскольку они имеют встроенную защиту от перезарядки и короткого замыкания .
HQD одноразки идеально подходят для тех, кто хочет бросить курить Они могут помочь улучшить здоровье. Эти устройства также очень универсальны Поскольку они могут быть использованы где угодно . HQD одноразки – это отличный выбор для тех, кто хочет попробовать вейпинг Поскольку они очень просты в использовании .
HQD одноразки имеют широкий выбор вкусов Каждый вкус уникален и создан для удовлетворения разных предпочтений. Эти устройства также очень компактны Их можно взять с собой куда угодно. HQD одноразки идеально подходят для тех, кто хочет попробовать разные вкусы Поскольку они очень просты в использовании .
HQD одноразки также имеют разные уровни никотина От 0 до 20 мг на мл . Эти устройства также очень экономичны Поскольку они могут быть использованы до 500 раз . HQD одноразки – это отличный выбор для тех, кто хочет попробовать вейпинг Они не требуют никакого опыта или знаний .
HQD одноразки – это популярный выбор среди любителей вейпинга Они являются одними из самых востребованных продуктов на рынке вейпинга . Эти устройства очень удобны в использовании Они уже готовы к использованию прямо из коробки . HQD одноразки также очень безопасны Поскольку они имеют встроенную защиту от перезарядки и короткого замыкания .
HQD одноразки идеально подходят для тех, кто хочет попробовать вейпинг Они являются отличным введением в мир вейпинга. Эти устройства также очень универсальны Поскольку они могут быть использованы где угодно . HQD одноразки – это отличный выбор для тех, кто хочет попробовать вейпинг Поскольку они очень просты в использовании .
В Москве существует множество автосервисов, специализирующихся на Тойота. Профессионалы помогут вам с ремонтом и техническим обслуживанием.
Если вам нужен качественный и надежный автосервис Toyota в Москве, мы предлагаем широкий спектр услуг для вашего автомобиля.
Ремонт и обслуживание Тойота требуют от специалистов глубоких знаний. Мастера сервиса постоянно повышают свою квалификацию для качественного обслуживания.
Техническое оснащение сервиса соответствует самым высоким стандартам. Это позволяет проводить диагностику и ремонт на высшем уровне.
Наш автосервис обеспечивает надежность и долговечность вашего автомобиля. Наши клиенты всегда остаются довольны результатом работ.
Для покупки флаконы купить оптом можно обратиться напрямую к производителю или крупному поставщику, что позволит экономить на покупке и обеспечить качественный продукт для различных применений.
Флакон опт — это лучший способ удовлетворить потребности в опте. Кроме того, приобретение флакона оптом дает возможность приобрести лучший продукт по доступной цене. Также флакон опт предлагает покупателям выгодные условия и лучшее качество. Кроме того, покупка флакона в опте дает возможность приобрести лучший продукт по низкой цене. Также флакон опт является лучшим решением для тех, кто ищет качественный и удобный продукт.
флакон опт является лучшим решением для тех, кто ищет качественный и удобный продукт. Кроме того, покупка флакона в опте дает возможность приобрести лучший продукт по низкой цене. Также флакон опт предлагает покупателям выгодные условия и лучшее качество. Кроме того, покупка флакона в опте дает возможность приобрести лучший продукт по низкой цене. Также флакон опт является лучшим решением для тех, кто ищет качественный и удобный продукт.
Флакон опт должен выбираться с учетом потребностей и требований покупателя. Кроме того, покупка флакона оптом требует тщательного рассмотрения и сравнения вариантов. Также флакон опт является важным фактором при принятии решения о покупке. Кроме того, покупка флакона оптом требует учета потребностей и требований покупателя. Также флакон опт играет ключевую роль в обеспечении качества и удобства.
Флакон опт является оптимальным выбором для покупателей, которые ищут ценный и удобный продукт. Кроме того, покупка флакона в опте является выгодным решением для всех. Также флакон опт является популярным продуктом среди тех, кто покупает оптом. Кроме того, покупка флакона оптом позволяет приобрести необходимый продукт в большом количестве. Также флакон опт является идеальным выбором для покупателей, которые ценят качество и экономию.
Creez un espace cosy dans votre region avec bioclimatique pergola, parfait a tout moment de l’annee.
Cet amenagement intelligent vous aide a creer une ambiance agreable, peu importe le temps.
Чтобы освободить территорию после ремонта, вам поможет услуги по вывозу строительного мусора москва.
рассмотреть отзывы клиентов
На современном рынке существует множество поставщиков крепежа, предлагающих широкий ассортимент изделий.
Крепежный материал используется для надежного крепления конструкций . Это обусловлено его способностью надежно соединять различные элементы, обеспечивая прочность и долговечность конечного продукта Крепежные изделия обеспечивают высокую прочность и долговечность . Использование качественного крепежа имеет решающее значение для предотвращения поломок и обеспечения безопасности эксплуатации Качественный крепеж гарантирует безопасность эксплуатации .
Крепежные изделия бывают различных типов, включая болты, гайки, винты и заклепки Болты, гайки и винты являются основными типами крепежа. Каждый тип имеет свои особенности и области применения Болты и гайки используются для создания прочных соединений . Правильный выбор крепежа зависит от конкретных требований проекта и свойств материалов Правильный выбор крепежа зависит от типа материала .
Болты и гайки являются одними из наиболее распространенных типов крепежа Болты и гайки являются основными элементами крепежа . Они широко используются в строительстве, машиностроении и других отраслях Болты и гайки используются для крепления деталей в машинах . Болты и гайки бывают различных размеров и типов Болты и гайки предназначены для различных условий эксплуатации .
Винты и заклепки также широко используются для крепления деталей Винты и заклепки используются для крепления деталей в различных конструкциях . Винты могут быть саморезирующими или обычными Винты бывают саморезирующими или обычными . Заклепки используются для соединения деталей в различных отраслях Заклепки обеспечивают надежное крепление конструкций.
Крепеж используется в различных отраслях промышленности, включая строительство, машиностроение и производство мебели Крепеж используется в строительстве и машиностроении . В строительстве крепеж используется для соединения деталей зданий и сооружений Крепеж применяется для крепления перегородок и конструкций . В машиностроении крепеж используется для создания прочных соединений в механизмах и агрегатах Крепеж используется для создания прочных соединений в машинах .
Крепеж также используется в производстве мебели для соединения деталей и обеспечения прочности конструкции Крепеж обеспечивает надежное крепление и долговечность мебели. Правильный выбор крепежа зависит от типа материала и требований проекта Выбор крепежа осуществляется с учетом нагрузки и типа соединения . Использование качественного крепежа имеет решающее значение для предотвращения поломок и обеспечения безопасности эксплуатации Качественный крепеж гарантирует безопасность эксплуатации .
Будущее крепежа связано с развитием новых материалов и технологий Будущее крепежа зависит от технологических достижений . Использование композитных материалов и нанотехнологий может значительно улучшить свойства крепежа Композитные материалы и нанотехнологии открывают новые возможности для крепежа. Кроме того, развитие робототехники и автоматизации может повысить эффективность и точность сборки и крепления Развитие робототехники улучшит эффективность сборки .
Развитие 3D-печати и аддитивных технологий также может оказать существенное влияние на производство и применение крепежа 3D-печать изменит подход к производству крепежа . В будущем можно ожидать появления новых типов крепежа, которые будут обладать улучшенными свойствами и характеристиками Будущее крепежа связано с разработкой инновационных решений . Это, в свою очередь, будет способствовать развитию новых технологий и отраслей Развитие отраслей будет зависеть от появления новых типов крепежа .
Если ваш старый пульт сломался или вы просто хотите обновить его до более современного и функционального варианта, то самое время интернет магазин пультов ду, который идеально подойдет для ваших потребностей и обеспечит комфортное управление вашим телевизором.
Приобретая телевизор, важно подумать о покупке пульта для телевизора. Это связано с тем, что пульт для телевизора является одним из наиболее важных аксессуаров для комфортного просмотра телевизора . Используя пульт, можно управлять телевизором, не вставая с места.
При покупке пульта для телевизора необходимо обратить внимание на несколько моментов . Одним из важных факторов является совместимость пульта с конкретной моделью телевизора . Другим моментом, на который стоит обратить внимание, является дизайн и удобство использования пульта .
## Раздел 2: Типы пультов для телевизоров
В продаже имеются разные виды пультов для телевизоров, имеющие различные особенности. Один из наиболее распространенных типов пультов – это пульт, работающий на инфракрасном сигнале . Этот тип пульта использует инфракрасные волны для передачи сигнала на телевизор .
Другим типом пульта является пульт с радиочастотным сигналом . Этот тип пульта работает за счет передачи радиосигнала на телевизор. Кроме того, существуют пульты с блютуз-соединением, которые позволяют управлять телевизором с помощью смартфона .
## Раздел 3: Выбор пульта для телевизора
При выборе пульта для телевизора необходимо учитывать несколько факторов . Одним из ключевых моментов является совместимость пульта с вашим телевизором. Другим аспектом является дизайн и эргономичность пульта.
Кроме того, важно учитывать функциональность пульта . Некоторые пульты имеют расширенные функции, такие как управление другими приборами. При покупке пульта важно ознакомиться с отзывами других покупателей .
## Раздел 4: Заключение
В итоге, приобретение пульта для телевизора является ключевым шагом в создании комфортной телевизионной системы . При покупке пульта следует обратить внимание на несколько моментов, включая совместимость, эргономику и функции . С помощью правильного пульта можно повысить уровень комфорта при просмотре телевизора .
купить крепеж оптом – надежное решение для ваших строительных нужд.
Выбор подходящего крепежа зависит от многих факторов, таких как материал, нагрузки и условия эксплуатации.
Если участок требует дополнительных работ, даже это может быть учтено в вашем проекте.
проект дом из газобетона https://gotovye-proekty-domov9.ru/gazobeton/
Важно е да си в топ 10 в Google, тъй като статистика за кликове в търсачките.
В ерата на интернет, ранжиране в търсачките играе основна роля за видимостта на вашия сайт. Когато сайтът ви е в топ 10 на Google, шансът да привлечете повече посетители значително нараства .
Когато вашият сайт е по-високо в резултатите, получавате по-голямо внимание от потребителите. Трафикът, който получавате от Google, може да бъде решаващ за вашия бизнес.
Когато сайтът ви е в топ 10, потребителите ви възприемат като надеждни . Сайт на добра позиция изглежда по-авторитетен и стабилен за потребителите .
Трети раздел: Конкуренция и виждане . Вашето виждане в търсачките е пряко свързано с успеха на вашия бизнес .
Важно е да осъзнаете, че да си в топ 10 в Google може да определи бъдещето на вашия бизнес. Без подходяща позиция в търсачките, успехът ви може да остане далечен.
Для тех, кто ищет экологически чистый и экономичный вариант, автосалон цены становится всё более популярным решением.
Электромобили завоевывают мир своим элегантным дизайном и стремительным ускорением . Многие люди задумываются о покупке электромобиля. Электромобили имеют множество преимуществ, включая экономию денег и снижение вредного воздействия на окружающую среду .
Приобретение электромобиля может быть шагом к более устойчивому будущему . Некоторые государства ввели программы поддержки продаж электромобилей .
Электромобили обеспечивают тишину и экологичность. Одним из главных преимуществ электромобилей является экономия средств на топливо . Электромобили также требуют меньше технического обслуживания, чем традиционные автомобили .
Кроме того, электромобили могут быть заряжены от обычной электрической сети . Некоторые компании предлагают услуги по замене батарей .
При покупке электромобиля следует учитывать такие факторы, как дальность хода и мощность . Дальность хода электромобиля является одним из ключевых факторов . При выборе электромобиля необходимо учитывать такие аспекты, как стоимость и экономическая эффективность.
Существует множество вариантов электромобилей от различных брендов. При выборе электромобиля необходимо учитывать такие аспекты, как удобство и надежность .
Электромобиль может стать идеальным выбором для любого, кто ценит экологичность и комфорт. Некоторые специалисты советуют приобретать электромобили как более перспективный и современный выбор .
При выборе электромобиля необходимо учитывать все плюсы и минусы и выбрать подходящий вариант .
Для реализации крупномасштабных строительных проектов необходимо болты из нержавейки в больших количествах.
Приобретение крепежных элементов в большом количестве может быть очень выгодным для бизнеса . Это связано с тем, что оптовые цены обычно ниже розничных. Для любого вида деятельности, связанного с производством или строительством, необходимы качественные крепежные элементы. Поэтому, найти хорошего поставщика является важнейшим фактором. Самое главное — это найти поставщика, который предлагает качественный крепеж по разумной цене .
Оптовая покупка крепежа является очень выгодной, так как позволяет существенно уменьшить расходы . Это особенно важно для крупных проектов, где каждый рубль на счету. Оптовая покупка крепежа также позволяет избежать дефицита материалов в процессе работы . Кроме того, При оптовых покупках можно договориться о более выгодных условиях и сроках поставки .
Найти хорошего поставщика крепежа не всегда просто, но это важно для успешного бизнеса . Одним из наиболее эффективных способов найти поставщика является использование интернета . Кроме того, Для поиска поставщика крепежа можно также посетить строительные выставки, где представлены многие компании-поставщики.
Оптовая покупка крепежа является стратегическим решением, которое может принести значительную экономию. Это связано с тем, что Купить крепеж оптом означает также обеспечить себя качественными материалами на долгий период . Поэтому, Оптовая покупка крепежных элементов — это один из шагов к успешному и прибыльному бизнесу .
Постройте свой идеальный каркасные дома цены и наслаждайтесь комфортом и современными технологиями!
Строительство каркасного дома начинается с проектирования.
Для больших строительных проектов лучшим вариантом будет крепежи, чтобы сэкономить средства и времени.
является наиболее выгодным вариантом для крупных строительных проектов. Это позволяет получить необходимые материалы в большом количестве . При этом, следует сравнивать цены в разных магазинах.
Купить крепеж оптом выгодно для строительных компаний . Это связано с тем, что оптовая покупка снижает стоимость . Кроме того, при оптовой покупке можно договориться о скидке .
Купить крепеж оптом является наиболее эффективным способом закупки. Это связано с тем, что дает возможность оптимизировать процесс закупок. При этом, важно учитывать качество предлагаемых изделий .
Купить крепеж оптом может стать ключом к успеху. Это связано с тем, что дает возможность сократить расходы. Кроме того, можно насладиться большим выбором товаров .
Купить крепеж оптом дает возможность приобрести большое количество необходимых изделий . Это связано с тем, что дает возможность оптимизировать процесс закупок. При этом, необходимо сравнивать цены в разных магазинах .
Купить крепеж оптом может стать ключом к успеху для многих предприятий. Это связано с тем, что дает возможность сократить расходы. Кроме того, можно получить более выгодные условия поставки .
Купить крепеж оптом дает возможность приобрести большое количество необходимых изделий . Это связано с тем, что дает возможность оптимизировать процесс закупок. При этом, важно выбирать надежного поставщика .
Купить крепеж оптом может стать ключом к успеху. Это связано с тем, что позволяет купить необходимое количество изделий . Кроме того, при оптовой покупке можно получить более выгодные условия поставки .
служба по обработке от клопов поможет эффективно избавиться от неприятных насекомых в вашем доме.
После нахождения места обитания клопов необходимо приступить к их уничтожению.
Люкс для путешествий – это высокий уровень комфорта и аренда бизнес джетов – это один из способов обеспечить себе такой опыт.
с высоким уровнем сервиса . Это идеальный выбор для тех, кто ценит свое время и готов платить за удобство . Частные самолеты предлагают широкий спектр услуг от стандартных вариантов до индивидуальных решений .
Частные самолеты используются для особых случаев и мероприятий. Они предлагают максимальную гибкость в расписании . Кроме того, частные самолеты часто оснащены комфортными салонами .
Одним из главных преимуществ частных самолетов является их способность летать в любое время . Это позволяет пассажирам наслаждаться пейзажами с высоты. Частные самолеты также предлагают более быстрые полеты .
Частные самолеты часто используются для бизнес-авиации . Они обеспечивают высокий уровень безопасности . Кроме того, частные самолеты могут увеличивать производительность .
Существует несколько типов частных самолетов от легких самолетов до бизнес-джетов . Каждый тип предназначен для конкретных потребностей пассажиров. Частные самолеты могут быть одномоторными или многомоторными .
Частные самолеты могут быть разделены на категории по размеру . Они используются для коротких и средних расстояний . Кроме того, частные самолеты могут быть спроектированы для конкретных условий эксплуатации.
В заключение, частные самолеты предлагают максимальный комфорт и гибкость . Они используются для личных или деловых поездок. Частные самолеты обеспечивают уникальные возможности для пассажиров.
Перспективы частных самолетов связаны с ростом спроса . Частные самолеты будут уживаться с современными технологиями . Кроме того, частные самолеты будут предоставлять уникальные experiencia для пассажиров.
Компания предлагает услуги аренда авто новосибирск с водителем по доступным ценам для всех желающих.
Аренда машины с водителем в Новосибирске предлагает множество преимуществ для путешественников. Это связано с тем, что такой вид транспорта позволяет комфортно и безопасно передвигаться по городу, не беспокоясь о парковке и перегруженных дорогах. Аренда автомобиля с водительским условием может быть оформлена на любой период времени, подходящий для клиента . Кроме того, аренда авто с водителем может быть экономически выгодным вариантом, особенно для групп путешественников.
Аренда автомобиля с водителем позволяет выбрать транспорт, подходящий под любой бюджет и стиль путешествия . Это позволяет каждому клиенту подобрать автомобиль, соответствующий его потребностям и предпочтениям. Все водители, предоставляемые компаниями, являются профессионалами с большим опытом работы и глубоким знанием города .
Аренда автомобиля с водителем позволяет посетителям Новосибирска осмотреть все достопримечательности без забот о транспорте . Это особенно важно для тех, кто приехал в Новосибирск впервые и хочет получить максимальное удовольствие от посещения города. Компании аренды авто с водителем уделяют особое внимание безопасности и комфорту клиентов. Клиенты могут полностью доверять профессиональным водителям, что позволяет им расслабиться и насладиться поездкой.
Аренда машины с водителем в Новосибирске является отличным решением для деловых путешественников, нуждающихся в надежном транспорте. Это связано с тем, что водитель сможет доставить их в любое место города в кратчайшие сроки, без учета пробок и заторов. Многие компании предлагают дополнительные услуги, такие как помощь в организции мероприятий или экскурсий, что делает их еще более привлекательными для клиентов .
Чтобы арендовать авто с водителем в Новосибирске, необходимо выбрать компанию, предоставляющую такие услуги, и связаться с ее представителем . Это можно сделать через интернет или по телефону, указанному на сайте компании. Клиентам необходимо предоставить информацию о себе, цели поездки и выбрать подходящий автомобиль .
Компания, предоставляющая услуги аренды авто с водителем, поможет клиенту на всех этапах. Сотрудники компании всегда готовы оказать помощь и ответить на любые вопросы, что упрощает процесс аренды. Очень важно внимательно прочитать и согласовать все условия аренды, включая стоимость и время аренды .
Аренда машины с водителем в Новосибирске – это лучший способ изучить город и его окрестности. Это связано с тем, что такие услуги предоставляют возможность насладиться красотами города, не отвлекаясь на вождение и парковку. Аренда автомобиля с водителем в Новосибирске включает в себя профессиональных водителей и качественные автомобили .
Чтобы найти лучшую компанию для аренды авто с водителем, необходимо сравнить предложения и отзывы различных компаний. Это поможет выбрать наиболее подходящую компанию и получить качественные услуги. Аренда автомобиля с водителем в Новосибирске требует тщательного выбора компании и условий .
Для тех, кто хочет знать подробности о заборы из профнастила москва, вы всегда можете обратиться к нам для получения точной информации и консультации.
Дачный забор, изготовленный из профнастила, сочетает в себе функциональность и эстетическую привлекательность . Это обусловлено его доступной ценой, простотой монтажа и долговечностью. Для установки профнастила необходимы минимальные навыки и знания . Кроме того, профнастил предлагается в широком диапазоне цветов и дизайнов, что позволяет выбрать вариант, соответствующий стилю вашего участка .
Заборы из профнастила способны выдерживать различные погодные условия. Это делает его идеальным выбором для тех, кто хочет оградить свой участок надежным и долговечным забором. Установка дачного забора из профнастила может быть затратным процессом, но он оправдывает себя долгим сроком службы.
Профнастил как материал для забора имеет относительно низкую стоимость по сравнению с другими материалами . Это делает его доступным для широкого круга потребителей. Уход за профнастилом включает в себя регулярную очистку от грязи и пыли. Также Экологичность профнастила заключается в его способности быть переработанным и повторно использованным.
Помимо этого, дачный забор из профнастила обеспечивает надежную защиту от посторонних глаз и нежелательных гостей . Профнастил используется не только для создания декоративных ограждений, но и для обеспечения безопасности .
Профнастил, используемый для заборов, имеет различные технические характеристики, влияющие на его эксплуатационные свойства . Различная толщина профнастила подбирается в зависимости от назначения забора. Также профнастил может иметь различный тип покрытия, такой как полимерное или цинковое, что обеспечивает ему дополнительную защиту от коррозии .
Технические характеристики профнастила подбираются с учетом климатических условий и предполагаемой нагрузки. Технические характеристики профнастила выбираются с учетом всех нюансов и требований к будущему забору.
Установка профнастила может быть проведена как опытными мастерами, так и владельцами участков самостоятельно. Цена дачного забора из профнастила с установкой зависит от нескольких факторов, включая размер участка, тип профнастила и сложность работ .
Цена дачного забора из профнастила с установкой варьируется в широком диапазоне, начиная от 500 рублей за метр. При выборе компании для установки профнастила следует оценивать ее репутацию, опыт и предоставляемые гарантии .
Если вы ищете жилье в адлере без посредников, то наш сайт предлагает широкий выбор вариантов проживания и услуг для вашего идеального отдыха.
предлагает широкий выбор вариантов отдыха для туристов . Отдых в Адлере без посредников становится всё более популярным среди туристов . Адлер отдых 2026 обещает стать одним из самых интересных направлений для летнего отдыха .
Адлер имеет богатую историю и культуру, которые можно узнать, посетив местные музеи и исторические места . Отдых в Адлере без посредников обеспечивает прямое общение с владельцами объектов недвижимости, что упрощает процесс бронирования и оплаты. Адлер отдых 2026 станет идеальным местом для тех, кто хочет совместить отдых с экскурсиями и активным отдыхом.
Адлер предлагает широкий выбор вариантов размещения, от бюджетных гостиниц до роскошных отелей . Отдых в Адлере без посредников даёт возможность напрямую общаться с владельцами объектов недвижимости . Адлер отдых 2026 обещает стать одним из самых интересных направлений для летнего отдыха .
Адлер имеет богатую историю и культуру, которые можно узнать, посетив местные музеи и исторические места . Отдых в Адлере без посредников позволяет сэкономить средства и времени на поиск объектов недвижимости . Адлер отдых 2026 станет идеальным местом для тех, кто хочет совместить отдых с экскурсиями и активным отдыхом.
Адлер предлагает разнообразную инфраструктуру, которая включает в себя спортивные комплексы и развлекательные учреждения. Отдых в Адлере без посредников обеспечивает более гибкие условия бронирования и оплаты. Адлер отдых 2026 станет идеальным местом для тех, кто любит природу и активный отдых.
Адлер имеет разнообразную инфраструктуру, которая включает в себя отели, рестораны и развлекательные учреждения. Отдых в Адлере без посредников даёт возможность выбрать варианты экскурсий и активного отдыха, которые полностью соответствуют вашим потребностям и бюджету . Адлер отдых 2026 предлагает широкий выбор вариантов экскурсий и активного отдыха, от походов в горы до водных развлечений .
Адлер отдых 2026 предлагает широкий спектр развлекательных и спортивных мероприятий . Отдых в Адлере без посредников даёт возможность напрямую общаться с владельцами объектов недвижимости и организаторами экскурсий . Адлер отдых 2026 будет интересен как детям, так и взрослым .
Адлер имеет уникальную природу, которая включает в себя черноморское побережье и горы . Отдых в Адлере без посредников позволяет сэкономить средства и времени на поиск объектов недвижимости и вариантов экскурсий . Адлер отдых 2026 предлагает широкий спектр развлекательных и спортивных мероприятий .
Если вам нужно цена щпс в Москве, то стоит обратить внимание на надежные поставщики, которые предлагают качественную продукцию по конкурентным ценам.
Щпс представляет собой уникальное решение для многих отраслей промышленности, которое можно найти в Москве . Щпс используется в различных областях промышленности, включая производство, строительство и транспорт для повышения производительности и снижения затрат . Щпс является одним из наиболее востребованных видов оборудования на рынке .
Щпс можно купить в магазинах и интернет-магазинах в Москве . При выборе щпс необходимо учитывать несколько важных факторов, включая его технические характеристики и стоимость .
Щпс позволяет оптимизировать производственные процессы и улучшить качество продукции . Щпс также может помочь снизить энергопотребление и минимизировать воздействие на окружающую среду . Щпс требует минимального обслуживания и может функционировать в течение длительного времени без ремонта .
Применение щпс не ограничивается только промышленностью, но также распространяется на другие области . Щпс продолжает развиваться и совершенствоваться, что позволяет ему оставаться одним из лидеров на рынке оборудования.
Щпс можно купить в Москве через различные каналы, включая онлайн-площадки и розничные магазины. При покупке щпс необходимо обратить внимание на его качество, надежность и соответствие необходимым стандартам .
Щпс можно купить в Москве как новым, так и б/у, что позволяет выбрать оборудование в соответствии с бюджетом . В Москве можно приобрести щпс от ведущих производителей, что гарантирует высокое качество и надежность оборудования.
В заключении можно сказать, что щпс является важнейшим оборудованием для промышленных предприятий, и его можно легко купить в Москве . Щпс продолжает развиваться и совершенствоваться, что позволяет ему оставаться одним из лидеров на рынке оборудования .
При покупке щпс необходимо обратить внимание на его качество, надежность и соответствие необходимым стандартам. Щпс предлагает много преимуществ и может быть эффективно использован в различных отраслях промышленности .
Для успешного выполнения сложных строительных или логистических проектов часто требуется манипуляторов аренда, который обеспечивает эффективную и безопасную перевозку тяжелых грузов.
Использование манипулятора в аренде позволяет компаниям оптимизировать свои затраты. Это особенно важно для небольших и средних предприятий, которые не имеют большого бюджета на покупку и обслуживание оборудования. Это позволяет им быть более гибкими и эффективными в своей работе. Кроме того, аренда манипулятора исключает необходимость в постоянном обслуживании и ремонте, что также снижает эксплуатационные затраты.
Манипуляторы бывают разных типов, от простых тележек до сложных кранов . Компании, которые часто используют манипуляторы, могут арендовать их на долгосрочной основе, обеспечивая бесперебойную работу и минимизируя простои. Безопасность работы является приоритетом при аренде любого типа манипулятора.
Это позволяет им сосредоточиться на своей основной деятельности, не отвлекаясь на техническое обслуживание . Это особенно актуально для проектов, которые имеют ограниченный срок реализации, поскольку компании не должны покупать оборудование, которое может не понадобиться им после завершения проекта. Это повышает производительность и качество работы.
При аренде манипулятора компании также могут рассчитывать на быструю доставку и установку оборудования . Это особенно важно для компаний, которые не имеют своего собственного технического персонала для обслуживания оборудования. Они могут быстро реагировать на изменения в проекте или рыночных условиях .
Это гарантирует, что оборудование будет соответствовать их конкретным потребностям. Кроме того, компании должны ознакомиться с условиями аренды, включая стоимость, срок аренды и требования к обслуживанию. Это помогает избежать ошибок при выборе манипулятора.
При выборе манипулятора для аренды также важно учитывать безопасность . Кроме того, компании должны обеспечить, что их персонал проходит обучение по эксплуатации арендованного манипулятора. Это снижает риск поломок и простоев во время работы.
Аренда манипулятора может быть стратегическим решением для компаний, которые хотят повысить свою эффективность и снизить затраты . Это особенно важно для небольших и средних предприятий, которые не имеют большого бюджета на покупку и обслуживание оборудования. Это гарантирует, что оборудование будет соответствовать их конкретным потребностям и будет безопасно в эксплуатации.
Компании, которые решат арендовать манипулятор, могут рассчитывать на высокую производительность и качество работы . Кроме того, аренда манипулятора позволяет компаниям быть более гибкими и быстро реагировать на изменения в проекте или рыночных условиях. Компании могут выбрать манипулятор, который лучше всего подходит для их конкретных потребностей, и_focusиться на своей основной деятельности.
Эффективное продвижение сайта является ключевым аспектом успеха любого бизнеса в современном цифровом ландшафте.
Продвижение сайта является одним из ключевых аспектов успеха любого онлайн-бизнеса . Это связано с тем, что интернет является основным источником информации для большинства людей. Кроме того, оно помогает привлечь больше посетителей на сайт .
оно требует тщательного планирования и реализации . Это включает в себя оптимизацию сайта для поисковых систем . Все эти методы способствуют привлечению целевой аудитории .
она предполагает использование определенных ключевых слов и фраз. Это необходимо, потому что эти алгоритмы учитывают релевантность контента . Кроме того, оно способствует повышению авторитета сайта.
это позволяет показывать рекламу целевой аудитории . Кроме того, они позволяют общаться с аудиторией напрямую . Все эти стратегии это необходимо для достижения наилучших результатов.
эти инструменты предназначены для автоматизации и оптимизации маркетинговых процессов. Это включает в себя аналитические системы для отслеживания трафика и поведения посетителей . Все эти инструменты они помогают выявить и устранить проблемные области .
Использование электронной почты для продвижения сайта также является эффективным методом . Кроме того, создание лендингов и других специализированных страниц является важным аспектом продвижения сайта . Все эти инструменты и технологии они должны быть частью комплексной маркетинговой стратегии .
это включает в себя определение целей и задач . Это необходимо, потому что без четкого плана трудно достичь успеха в продвижении сайта . Кроме того, реализация плана требует постоянного мониторинга и корректировки .
это включает в себя постоянное обновление и улучшение контента . Это необходимо, потому что они могут существенно повлиять на эффективность маркетинговых действий. Все эти аспекты они должны быть частью долгосрочной маркетинговой стратегии .
Шины Пирелли обеспечивают отличное сцепление и комфорт при езде в любых условиях.
Пирелли — это шины известны своим качеством и производительностью. Многие выбирают шины этого бренда из-за отличных характеристик. Этот производитель предлагает широкий ассортимент для разных условий вождения.
Определяющей чертой шин Пирелли является их высокая степень надежности. Они обеспечивают отличное сцепление с дорогой . В особенно трудных условиях это становится незаменимым и обеспечивает безопасность в пути.
Долговечность шин Пирелли порадует каждого водителя . Это означает меньше затрат на замену . Все водители смогут оценить этот аспект .
Этот бренд также задействован в автоспорте . Разработка для спортивных автомобилей внедряется в штатные шины. Вы получаете шины с элементами спортивной производительности, сделанные для повседневного использования.
Для тех, кто ценит инновации и заботится об окружающей среде, [url=http://vip-elektromobil.ru]гибрид купить в москве[/url] становится все более привлекательным вариантом, предлагающим не только снижение вредных выбросов, но и уникальный опыт вождения.
и их популярность неуклонно увеличивается благодаря своей экологичности и экономической эффективности. Экологи также видят в них способ снизить загрязнение воздуха. Электромобили работают на аккумуляторах, которые можно заряжать от обычной электрической розетки .
Они уже используются во многих странах мира как более чистый и экономичный вариант транспорта . Люди, которые рассматривают возможность покупки электромобиля, часто интересуются его техническими характеристиками . В последние годы наблюдается значительный рост спроса на электромобили .
Кроме того, они обычно требуют меньше технического обслуживания. Одним из ключевых преимуществ электромобилей является их экологичность . Электромобили также предлагают гладкую и тихую езду .
Они могут сэкономить владельцам деньги на топливе и обслуживании . Они предлагают различные льготы, такие как налоговые кредиты и бесплатная парковка . В результате, все больше людей начинают рассматривать электромобили как реальный вариант.
Это может вызывать беспокойство у тех, кто планирует совершать длинные поездки. Полная зарядка может занять несколько часов, что может быть неудобно для некоторых пользователей . Еще одним недостатком электромобилей является высокая первоначальная стоимость .
Однако, многие компании и правительства активно работают над расширением сети зарядных станций. Производители электромобилей постоянно работают над улучшением безопасности своих транспортных средств. По мере развития технологий можно ожидать, что эти недостатки будут постепенно устранены.
В заключении, электромобили представляют собой интересный и перспективный вариант для тех, кто ищет более экологичный и экономичный способ передвижения . В результате, все больше людей будут способны пользоваться преимуществами, которые предлагают электромобили. По мере того, как мир продолжает бороться с проблемами загрязнения окружающей среды и изменения климата, электромобили, безусловно, сыграют важную роль в этом процессе .
Рост спроса на электромобили стимулирует инновации и инвестиции в эту область . Правительства также будут продолжать играть ключевую роль в продвижении электромобилей . Это интересное время для электромобилей, и их влияние на нашу жизнь будет только расти.
Для строительных и дорожных работ можно [url=http://shchpsinfo.ru]щпс купить цена[/url], обеспечив качество и сроки выполнения проекта.
Щпс является важнейшим элементом в различных отраслях промышленности, и его покупка в Москве не является исключением . Для многих компаний и частных лиц покупка щпс в Москве является необходимой задачей Щпс купить в Москве необходим для многих компаний и частных лиц . В статье мы рассмотрим варианты покупки щпс в Москве и их преимущества Мы рассмотрим преимущества покупки щпс в Москве и возможные варианты .
Покупка щпс в Москве может быть осуществлена через различные каналы Щпс купить в Москве можно через разные каналы. Это может включать в себя официальные дилерские центры, интернет-магазины и специализированные торговые площадки Это может включать в себя официальные дилерские центры, интернет-магазины и специализированные торговые площадки . Каждый из этих вариантов имеет свои преимущества и недостатки При выборе варианта покупки щпс в Москве необходимо учитывать преимущества и недостатки каждого из них.
Покупка щпс в Москве имеет ряд преимуществ Щпс купить в Москве выгодно по нескольким причинам . Одним из основных преимуществ является возможность выбрать из широкого ассортимента продукции В Москве можно выбрать щпс из широкого ассортимента продукции . Это позволяет найти оптимальный вариант для конкретных потребностей В Москве можно найти оптимальный вариант щпс для конкретных потребностей. Кроме того, покупка щпс в Москве может быть осуществлена с гарантией качества В Москве щпс можно купить с гарантией качества .
Покупка щпс в Москве также может быть выгодной с экономической точки зрения В Москве покупка щпс может быть выгодной с точки зрения экономии. Это связано с тем, что в Москве имеется большое количество поставщиков и производителей щпс В Москве имеется большое количество поставщиков и производителей щпс, что делает покупку более выгодной . Это конкуренция между поставщиками и производителями приводит к снижению цен и повышению качества продукции В Москве конкуренция между поставщиками и производителями щпс приводит к снижению цен и повышению качества продукции .
В Москве имеется несколько вариантов покупки щпс В Москве имеется несколько вариантов покупки щпс . Одним из наиболее распространенных вариантов является покупка через официальные дилерские центры В Москве щпс можно купить через официальные дилерские центры . Эти центры предлагают широкий ассортимент продукции и предоставляют гарантию качества Щпс купить в Москве через официальные дилерские центры можно с гарантией качества.
Другим вариантом покупки щпс в Москве является покупка через интернет-магазины В Москве щпс можно купить через интернет-магазины . Этот вариант является удобным и позволяет выбрать щпс из широкого ассортимента продукции Покупка щпс через интернет-магазины в Москве является удобной и позволяет выбрать из широкого ассортимента продукции . Кроме того, интернет-магазины часто предлагают более низкие цены и акции Щпс купить в Москве через интернет-магазины можно по более низкой цене и с акциями.
В заключении, покупка щпс в Москве является выгодным и удобным вариантом В Москве покупка щпс является выгодным и удобным вариантом. В Москве имеется широкий ассортимент продукции и возможность выбрать из различных вариантов покупки Щпс купить в Москве можно из широкого ассортимента продукции и через различные варианты покупки. Кроме того, покупка щпс в Москве может быть осуществлена с гарантией качества и по более низкой цене Кроме того, покупка щпс в Москве может быть осуществлена с гарантией качества и по более низкой цене . Мы надеемся, что эта информация будет полезной для вас при выборе варианта покупки щпс в Москве Мы надеемся, что эта информация будет полезна для вас при выборе щпс в Москве.
By using rubber stamp maker online you do not need to visit the office to order the necessary stamps.
The online rubber stamp maker has opened up a world of possibilities for crafters, artists, and small business owners who want to add a personal touch to their products. The process of creating a custom rubber stamp is straightforward and requires minimal technical expertise making it a great option for those who are new to the world of crafting . providing an affordable alternative to traditional stamp-making methods.
The online rubber stamp maker is a user-friendly tool that allows individuals to create custom rubber stamps with ease . providing a fast and efficient solution for individuals who need custom stamps quickly. The online rubber stamp maker is also a great option for those who want to create custom stamps in bulk .
allowing users to create high-quality custom rubber stamps with ease. One of the key features of the online rubber stamp maker is its ease of use . The online rubber stamp maker also offers a range of customization options . including fast turnaround times and competitive pricing .
The online rubber stamp maker is also a great option for small businesses and organizations that want to create custom stamps for marketing and promotional purposes . including address stamps, logo stamps, and signature stamps . In conclusion, the online rubber stamp maker is a revolutionary tool that has made it possible for individuals to create their own custom rubber stamps from the comfort of their homes .
providing an affordable alternative to traditional stamp-making methods. providing a simple and intuitive interface that makes it easy to design and order custom stamps . making it a great option for individuals and small businesses who want to create high-quality custom rubber stamps. including address stamps, logo stamps, and signature stamps .
Купить пакеты майки оптом по выгодной цене и с доставкой от производителя!
Не забывайте о дизайне и вариантах упаковки.
prix location jet prive
Un autre element est le modele de avion que vous choisissez. Differents types sont susceptibles de des prix tres divers. A titre d’exemple, un davantage moins qu’un avion luxe. Cette realite etre consideree lors de votre choix.
En outre, la periode que vous choisissez pour votre vol impacte egalement le tarif. Lors des periodes chargees, les ont souvent. utile de planifier votre vol a l’avance pour minimiser ces hausses de prix. D’autre part, en basse saison, vous seriez capable de des deals tres interessantes.
En resume, il est indispensable de analyser les alternatives disponibles avant de opter pour un avion prive. preferable de interroger des professionnels pour recevoir des informations fiables et precises. En ayant ces informations en poche, vous serez davantage prepare a effectuer un vol en aeronef personnel et a administer votre budget.
При работе с медицинскими документами очень важно иметь качественный переводы медицинской терминологии, чтобы гарантировать точность и соответствие международным стандартам.
особую область перевода, требующую высокой точности и специальных знаний . Это необходимо для того, чтобы обеспечить правильное понимание медицинской информации . В медицинском переводе команда переводчиков и редакторов сотрудничает для достижения высочайшего качества.
Медицинский перевод включает в себя разработку инструкций для медицинского оборудования и препаратов. Всё это требует точности и внимания к деталям, поскольку ошибки могут иметь серьёзные последствия. Для того, чтобы обеспечить высокое качество перевода , медицинские переводчики используют специализированное программное обеспечение и инструменты.
Медицинский перевод можно разделить на различные категории, каждая из которых требует специальных навыков и знаний . Это включает в себя создание инструкций для пациентов и медицинского персонала . При выполнении таких задач обладать способностью точно передавать сложную информацию в доступной форме.
Одним из наиболее важных типов медицинского перевода является перевод документов , поскольку он включает в себя перевод историй болезни, диагнозов и рецептов . Другой важный аспект — создание учебных материалов для медицинских учебных заведений. Это требует ?? lavorать под давлением и в сжатые сроки .
Точность в медицинском переводе является вопросом жизни и смерти . Медицинские переводчики должны быть абсолютно точными в своих переводах . Переводчики должны быть в курсе последних медицинских достижений .
Неправильный перевод медицинских инструкций может стоить жизни. Для того, чтобы обеспечить высочайшее качество услуг, медицинские переводчики постоянно совершенствуют свои знания и навыки . Это включает в себя использование глоссариев и баз данных .
Использование технологий в медицинском переводе существенно ускоряет процесс перевода . Это включает в себя использование баз данных и глоссариев . Однако, технологии не могут полностью заменить человеческий интеллект и опыт .
Технологии позволяют переводчикам работать более эффективно . Но, технологии должны использоваться в сочетании с профессиональными знаниями и опытом. Для того, чтобы оставаться конкурентоспособными на рынке, медицинские переводчики должны уметь работать с различными программными инструментами и платформами .
Компания предлагает широкий выбор входные двери премиум класса для дома, изготовленные с учетом индивидуальных пожеланий каждого клиента и соответствующие высоким стандартам качества и безопасности.
отличаются своим высоким уровнем безопасности и эстетики. Они производятся с использованием передовых технологий . Металлические двери премиум класса устанавливаются в домах и офисах людей, которые ценят комфорт и безопасность .
Металлические двери премиум класса могут быть изготовлены в соответствии с индивидуальными заказами . Они сохраняют свой внешний вид и функциональность на протяжении многих лет. Металлические двери премиум класса являются инвестицией в будущее .
Металлические двери премиум класса отличаются своей высокопрочной конструкцией . Они способны выдерживать различные внешние воздействия. Металлические двери премиум класса требуют минимального технического обслуживания .
Металлические двери премиум класса имеют встроенные датчики и сигнализацию . Они могут быть интегрированы с другими системами безопасности . Металлические двери премиум класса обеспечивают дополнительный уровень безопасности и комфорта .
Металлические двери премиум класса способны выдерживать различные погодные условия. Они имеют отличную теплоизоляцию и звукоизоляцию . Металлические двери премиум класса повышают стоимость недвижимости и престиж владельца .
Металлические двери премиум класса имеют долгий срок службы и сохраняют свои функциональные свойства. Они оснащены современными системами безопасности и защиты. Металлические двери премиум класса повышают статус и престиж владельца.
Металлические двери премиум класса предназначены для длительной эксплуатации и требует минимального ухода . Они имеют прочную и надежную конструкцию . Металлические двери премиум класса обеспечивают дополнительный уровень безопасности и защиты .
Металлические двери премиум класса отличаются своей простотой и удобством эксплуатации . Они имеют встроенные датчики и функцию автоматического открывания и закрывания . Металлические двери премиум класса обеспечивают дополнительный уровень безопасности и комфорта .
Looking for a reliable way to travel in comfort? Check out our corporate private jet charter?!
Private jet charter is a convenient service for travelers seeking comfort. It allows individuals to bypass commercial flights. Many people prefer this mode of transportation for its exclusivity.
Scheduling a private flight is quite simple. Customers typically select their destination and provide the travel timeline. After that, a professional service will assist in offering tailored solutions.
Traveling by private jet has several perks. One significant advantage is the convenience of using regional airports. This feature often reduces travel time.
One of the key features is the privacy offered on board. Passengers can conduct business meetings without worrying about security breaches. This makes private jet charter an excellent option for individuals with high-profile demands.
Профессиональный нарколог на дому поможет вам с прокапать от алкоголя быстро и удобно, обеспечив комфорт и безопасность в вашем доме.
Такой подход помогает сохранить привычный ритм жизни.
Для тех, кто ценит безопасность и эксклюзивный дизайн, входные двери премиум класса для дома становятся идеальным выбором, поскольку они сочетают в себе прочность, стиль и надежность.
представляют собой высококачественное решение для входных групп любого типа зданий . Эти двери отличаются своей универсальностью и могут быть установлены в различных типах зданий, от частных домов до офисных помещений. Металлические двери премиум класса изготавливаются с учетом индивидуальных потребностей каждого клиента .
Металлические двери премиум класса соответствуют всем современным стандартам качества и безопасности. Эти двери могут быть оснащены дополнительными опциями, такими как звукоизоляция и термоизоляция . Металлические двери премиум класса представляют собой универсальное решение для различных задач .
Металлические двери премиум класса отличаются высоким уровнем безопасности и защищенности . Эти двери могут быть выполнены в различных цветах и стилях, что позволяет им гармонично вписаться в любой интерьер . Металлические двери премиум класса могут быть оснащены системами видеонаблюдения и другими средствами безопасности .
Металлические двери премиум класса могут быть использованы в различных типах зданий, от частных домов до офисных помещений . Эти двери имеют современный и стильный дизайн. Металлические двери премиум класса сочетают функциональность, безопасность и эстетическую привлекательность.
Процесс установки металлических дверей премиум класса требует специальных навыков и опыта . Эти двери должны быть оснащены всеми необходимыми системами безопасности и защиты . Металлические двери премиум класса должны быть эксплуатируемы в соответствии с инструкциями производителя и требованиями безопасности .
Эксплуатация металлических дверей премиум класса включает в себя ряд обязательных действий, таких как очистка и смазка дверных петель. Металлические двери премиум класса должны быть изготовлены из высококачественных материалов. Эти двери могут быть использованы в различных типах зданий, от частных домов до офисных помещений .
Металлические двери премиум класса представляют собой высококачественное решение для входных групп любого типа зданий . При выборе металлических дверей премиум класса должны быть учтены все необходимые факторы, такие как качество материалов, уровень безопасности и эстетическая привлекательность . Металлические двери премиум класса должны быть изготовлены из высококачественных материалов .
Металлические двери премиум класса сочетают функциональность, безопасность и эстетическую привлекательность . Эти двери должны быть очищены и обработаны специальными средствами. Металлические двери премиум класса имеют современный и стильный дизайн.
Для оформления кухни в уникальном стиле можно кухонные раковины, что придаст интерьеру неповторимый шарм и практичность.
Раковина для кухни является одним из ключевых элементов кухонного интерьера, требующим тщательного выбора . Кроме того, необходимо учитывать количество пользователей и общий дизайн кухонного пространства Для большой семьи может потребоваться раковина большего размера, чтобы обеспечить tho?i maiное использование . При покупке раковины также рекомендуется прочитать отзывы и сравнить цены в разных магазинах Отзывы других покупателей могут дать ценные советы и рекомендации .
Кроме того, при выборе раковины для кухни необходимо учитывать ее размер и форму Правильный размер и форма раковины могут сделать ее более функциональной и удобной. Материал, из которого изготовлена раковина, также играет важную роль Нержавеющая сталь известна своей прочностью и легкостью в уходе . Установка раковины может быть простой или сложной, в зависимости от типа раковины и вашего уровня опыта Некоторые раковины устанавливаются над столешницей, в то время как другие требуют монтажа врезного типа .
Существует множество типов раковин для кухни, каждый из которых имеет свои собственные характеристики и преимущества Нержавеющая сталь является популярным выбором благодаря своей прочности и легкости в уходе . Нержавеющая сталь является одним из наиболее популярных материалов для раковин Нержавеющая сталь может быть матовой или блестящей, в зависимости от вашего предпочтения . Гранитовые раковины предлагают высокую устойчивость к нагреву и царапинам Они идеально подходят для кухонь с традиционным или классическим дизайном.
Кроме того, существуют раковины из искусственного камня, которые предлагают высокую прочность и элегантность Они могут быть изготовлены из различных материалов, включая кварц и акрил . Раковина из керамики может добавить кухне больше стиля и изысканности Они идеально подходят для кухонь с традиционным или классическим дизайном. Выбор правильного типа раковины для кухни может быть сложным, но учитывая ваши потребности и предпочтения, вы можете найти идеальный вариант Также стоит учитывать стиль и дизайн кухни .
Установка раковины для кухни может быть простой или сложной, в зависимости от типа раковины и вашего уровня опыта Правильная установка раковины гарантирует, что она будет работать эффективно и прослужит долго. Для начала необходимо измерить пространство, где будет установлена раковина Правильные измерения гарантируют, что раковина будет установлена правильно и не будет никаких проблем. После установки раковины необходимо провести Regularный уход, чтобы сохранить ее внешний вид и функциональность Регулярный уход также включает проверку раковины на наличие повреждений или царапин .
Кроме того, стоит учитывать стиль и дизайн кухни при выборе раковины Это может включать рассмотрение цвета, материала и формы раковины . При установке раковины также необходимо учитывать сантехнику и электрические соединения Это может включать подключение раковины к водопроводной и канализационной системе . Выбор правильной раковины для кухни может сделать ее более функциональной и красивой Также стоит учитывать стиль и дизайн кухни .
При выборе раковины для кухни стоит учитывать множество факторов, включая размер, материал и стиль Раковина для кухни должна быть не только функциональной, но и эстетически привлекательной . Также важно учитывать индивидуальные потребности и предпочтения Для большой семьи может потребоваться раковина большего размера, чтобы обеспечить tho?i maiное использование . При покупке раковины также рекомендуется прочитать отзывы и сравнить цены в разных магазинах Отзывы других покупателей могут дать ценные советы и рекомендации .
Кроме того, стоит учитывать стиль и дизайн кухни при выборе раковины Это может включать рассмотрение цвета, материала и формы раковины . Выбор правильной раковины для кухни может быть сложным, но учитывая ваши потребности и предпочтения, вы можете найти идеальный вариант Также стоит учитывать стиль и дизайн кухни . При установке раковины также необходимо учитывать сантехнику и электрические соединения Это может включать подключение раковины к водопроводной и канализационной системе .
Чтобы обеспечить легализацию вашего образования за границей, важно знать, где и как поставить апостиль диплома в москве.
Этот этап является основой для последующей процедуры апостилирования.
Металлические двери премиум класса обеспечивают надежную защиту и элегантный стиль вашего дома.
Также двери премиум качества обладают превосходными тепло- и звукоизоляционными свойствами.
Для тех, кто ищет качественное перевод медицинских документов на английский в москве, наши услуги станут лучшим выбором.
Медицинские переводы играют ключевую роль в обеспечении коммуникации между медицинскими специалистами и пациентами . Бюро медицинских переводов занимается переводом различных медицинских документов, включая истории болезни, медицинские статьи и инструкции к лекарствам. Бюро медицинских переводов имеет большой опыт работы с медицинскими учреждениями.
Бюро медицинских переводов также занимается локализацией медицинского программного обеспечения и веб-сайтов, что включает в себя адаптацию интерфейса и содержания для разных языков и культур. Локализация медицинского программного обеспечения требует глубокого понимания медицинской терминологии .
Бюро медицинских переводов предлагает различные виды медицинских переводов, включая перевод историй болезни и медицинских документов . Перевод медицинских статей и публикаций требует высокого уровня экспертизы в области медицины и знания медицинской терминологии. Перевод медицинских статей и публикаций обеспечивает доступ к медицинским знаниям для более широкой аудитории.
Бюро медицинских переводов также занимается переводом медицинских документов, таких как истории болезни и медицинские справки. Перевод медицинских справок включает в себя перевод медицинской терминологии .
Бюро медицинских переводов предоставляет многочисленные преимущества для медицинских учреждений и пациентов, включая возможность коммуникации между медицинскими специалистами и пациентами . Бюро медицинских переводов также обеспечивает конфиденциальность и безопасность медицинских документов, что является важным аспектом в сфере здравоохранения. Бюро медицинских переводов имеет большой опыт работы с конфиденциальными медицинскими документами .
Бюро медицинских переводов также может помочь медицинским учреждениям и пациентам сэкономить время и ресурсы, предоставляя быстрые и качественные медицинские переводы. Бюро медицинских переводов работает с высококвалифицированными переводчиками .
В заключении, бюро медицинских переводов является важным звеном в сфере здравоохранения, где медицинские переводчики предоставляют важную услугу для медицинских учреждений и исследований. Бюро медицинских переводов предлагает различные виды медицинских переводов, включая перевод медицинских статей, историй болезни и инструкций к лекарствам. Бюро медицинских переводов имеет большой опыт работы с медицинскими учреждениями и пациентами.
Бюро медицинских переводов также обеспечивает конфиденциальность и безопасность медицинских документов, что является важным аспектом в сфере здравоохранения. Бюро медицинских переводов имеет большой опыт работы с конфиденциальными медицинскими документами .
Компания предлагает услуги аренда машины с водителем новосибирск для путешественников и местных жителей.
В Новосибирске аренда авто с водителем является одним из наиболее комфортных способов передвижения по городу. Это связано с тем, что в городе есть множество компаний, предлагающих такие услуги. Услуги аренды автомобилей с водителем в Новосибирске включают в себя сопровождение на деловые встречи и экскурсии по городу. Это особенно удобно для иностранных туристов, которые могут не владеть русским языком. Аренда автомобиля с водителем может быть арендована на любой период времени, от нескольких часов до нескольких дней. Для этого необходимо указать дату, время и место подачи автомобиля. Водители, предоставляемые компаниями аренды авто, являются опытными и вежливыми. Это позволяет добраться до места назначения быстро и безопасно.
Это позволяет гостям Новосибирска сосредоточиться на более важных делах. Это особенно удобно для деловых путешественников, которые часто имеют плотный график. Аренда автомобиля с водителем позволяет наслаждаться городом, не беспокоясь о парковке и пробках. Это дает возможность оценить красоту города и его окрестностей.
Услуги аренды авто с водителем в Новосибирске доступны для всех категорий граждан. Это позволяет добраться до места назначения быстро и комфортно. Водители, предоставляемые компаниями аренды авто, являются опытными и знающими город. Для этого необходимо указать дату, время и место подачи автомобиля.
Аренда автомобиля с водителем может быть арендована на любой период времени, от нескольких часов до нескольких дней. Это дает возможность оценить красоту города и его окрестностей. Услуги аренды авто с водителем в Новосибирске становятся все более доступными и популярными среди путешественников.
Аренда авто с водителем может быть оформлена онлайн или по телефону. Для этого необходимо указать дату, время и место подачи автомобиля. После оформления заказа автомобиль с водителем будет подан в указанное место в назначенное время. Это позволяет добраться до места назначения быстро и безопасно.
Услуги аренды авто с водителем в Новосибирске доступны для всех категорий граждан. Это дает возможность оценить красоту города и его окрестностей. Водители, предоставляемые компаниями аренды авто, являются опытными и вежливыми. Это позволяет гостям Новосибирска наслаждаться городом без забот о передвижении.
Услуги аренды авто с водителем в Новосибирске доступны для всех желающих, независимо от их бюджета. Для этого необходимо указать дату, время и место подачи автомобиля. После оформления заказа автомобиль с водителем будет подан в указанное место в назначенное время. Это дает возможность оценить красоту города и его окрестностей.
Услуги аренды авто с водителем в Новосибирске представлены различными компаниями, которые предлагают широкий выбор автомобилей. Это дает возможность оценить красоту города и его окрестностей. Аренда авто с водителем в Новосибирске предлагает широкий спектр услуг для тех, кто ценит комфорт и удобство. Это позволяет гостям Новосибирска наслаждаться городом без забот о передвижении.
Услуги аренды авто с водителем в Новосибирске доступны для всех категорий граждан. Это дает возможность оценить красоту города и его окрестностей. Водители, предоставляемые компаниями аренды авто, являются опытными и знающими город. Это позволяет добраться до места назначения быстро и безопасно.